
Ora che sappiamo abbastanza su circuiti integrati, clock e chip di memoria, possiamo mettere tutto insieme per avere un sistema completo. Vedremo alcuni aspetti generali delle CPU dal punto di vista logico digitale. Siccome le CPU sono strettamente interconnesse con il design dei bus che usano, vedremo inoltre una introduzione al design dei bus e come sono interfacciati con le CPU.
Chip della CPU
Tutte le CPU moderne sono contenute in un singolo chip, questo fa si che tutte le interazioni con il resto del sistema è well defined. Infatti ogni chip della CPU comunica con il “mondo esterno” attraverso un insieme di pin, alcuni mandano i segnali di output e altri accettano segnali in input dal “mondo esterno” ( alcuni fanno tutte e due ).
Important
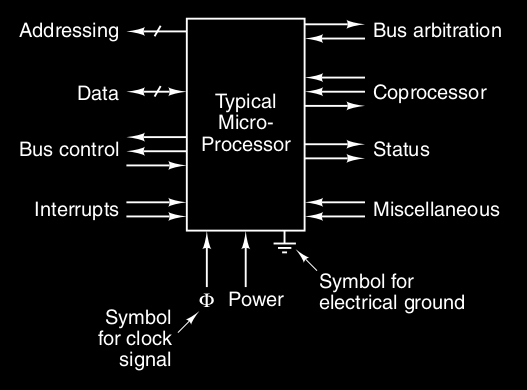
I pin in un chip della CPU possono essere divisi in tre tipi :
- address
- data
- control
Questi pin sono connessi ad altri pin simili nei chip di memoria e dispositivi I/O, attraverso il bus.
Quando la CPU deve eseguire una istruzione :
- pone l’indirizzo di memoria dell’istruzione nei pin address ( o bus address )
- asserisce le linee di controllo (pin control ) del bus per informare la memoria che vuole ( per esempio ) leggere una word
- la memoria risponde ponendo la word richiesta nei pin data e asserendo un segnale di controllo per dire “ok ho fatto”
- la CPU riceve questo segnale di controllo, legge la word e si prepara ad eseguire l’istruzione letta
I 2 parametri chiave che determinano le prestazioni di una CPU sono :
- numero di pin address
- con pin address può indirizzare locazioni di memoria
- di solito sono 16, 32 o 64
- numero di pin data
- con pin data può leggere/scrivere word da -bit in una singola operazione
- di solito sono 8, 32 o 64
Una CPU ha anche i pin control, che regolano il flusso e il timing dei dati che entrano ed escono dalla CPU ( e altri usi ), infatti possono essere di 6 categorie :
- controllo del bus : sono molti output dalla CPU al bus ( ingressi per chip di memoria e di dispositivi I/O ) e dicono al resto del sistema cosa vuole fare
- interruzioni : vengono da dispositivi I/O
- arbitraggio del bus : per regolare il “traffico” nel bus, per evitare che due dispositivi provino ad usare la CPU nello stesso momento. Anche la CPU richiede il bus come gli altri dispositivi
- comunicazione con il coprocessore : per comunicare con coprocessori come chip di floating-point, grafica o altri chip
- stato
- altri segnali di controllo : compatibilità vecchi chip I/O, reset computer, debugging etc
Inoltre i chip della CPU hanno anche pin per :
- l’alimentazione ( da +1.2 a 1.5 volt )
- massa
- segnale di clock
Bus del computer
Il bus è un collegamento comune che unisce vari dispositivi e infatti possono essere :
- interni alla CPU : per trasportare dati dalla ALU e alla ALU ( vedi nel prossimo capitolo )
- esterni alla CPU : per connetterla a memoria o dispositivi I/O ( quello che tratteremo ora )
I primi PC avevano un singolo bus di sistema, oggi i pc hanno un bus dedicato tra CPU-memoria e (almeno) un altro bus per CPU-dispositivi I/O .
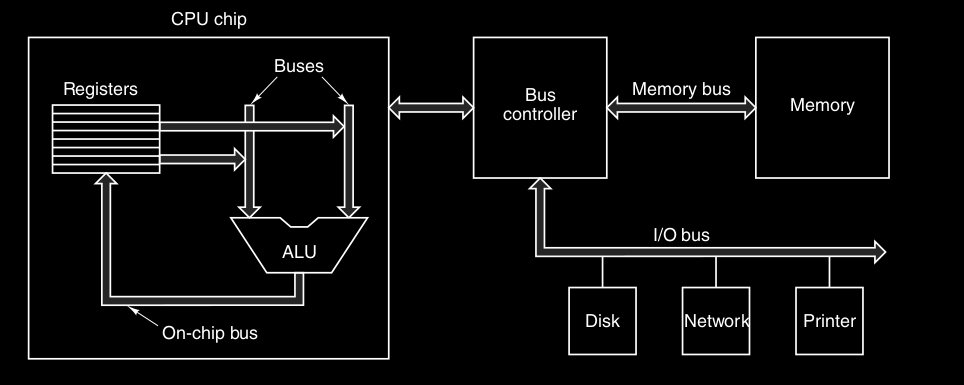
Questo in figura è infatti un esempio di sistema con un bus di memoria e uno per I/O.
Mentre i progettisti di CPU possono usare un qualsiasi tipo di bus all’interno dei loro chip, per i bus esterni devono essere definite delle regole ben definite protocollo di bus.
I dispositivi collegati al bus possono essere :
- attivi - masters : è il dispositivo che inizia e controlla una transazione nel bus
- passivi - slave : restano in attesa di una richiesta da un master
Per esempio, quando la CPU ordina al controllore del disco di voler leggere o scrivere un blocco, la CPU sta agendo come master e il controllore del disco come slave. Dopo, anche il controllore del disco agirà come master perché dovrà “ordinare” alla memoria di accettare le parole che sta leggendo dal disco.
Siccome i segnali binari sono spesso deboli per alimentare un bus, la maggior parte dei master sono collegati al bus da un bus driver, che amplifica il segnale, similmente i slave sono collegati al bus da un bus receiver. Per evitare il problema di connettere più uscite insieme, queste interfacce possono essere :
- buffer tri-state (come abbiamo visto nel chip della memoria in Memoria)
- open collector - wired-OR ( OR-cablato ) : quando due o più dispositivi asseriscono la “linea” nello stesso momento, viene fatto l’OR di tutti i segnali
Ampiezza del bus
Come abbiamo già visto, se un bus ha linee di indirizzo, allora una CPU può utilizzarlo per indirizzare locazioni di memoria differenti. Ok, questo sembra semplice, ma il problema è che più linee ci sono più aumentano i costi e lo spazio del bus ( infatti esiste un compromesso ).
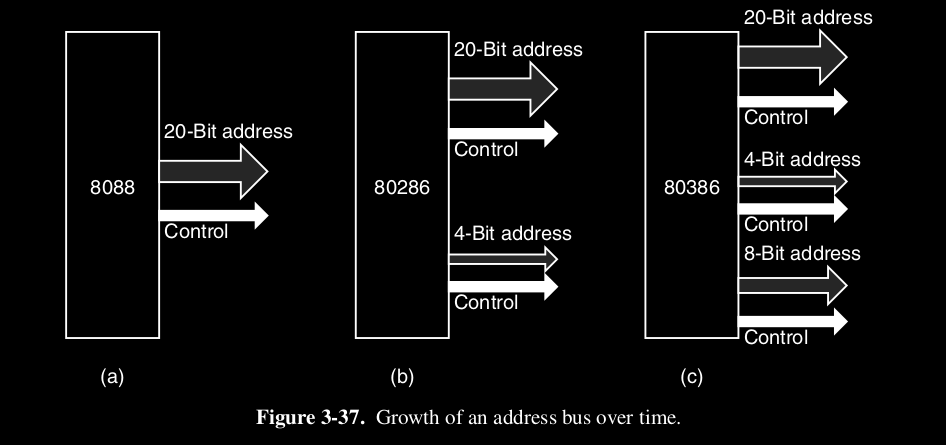
Infatti l’evoluzione dei processori Intel, mostra come l’incremento delle linee e la retro-compatibilità siano due aspetti contrapposti.
Larghezza di banda del bus
Non solo il numero di indirizzi incrementa nel tempo, ma anche il numero di linee dati. Infatti ci sono due modi per aumentare la larghezza di banda del bus :
- Diminuire il ciclo di clock ( o periodo ) del bus, in modo da aumentare la frequenza ( così molti più trasferimenti al secondo ). Difficile ( di solito si evita ) per questi problemi :
- abbiamo più dispositivi che operano a velocità diverse ( disallineamento del bus )
- perdiamo la retro-compatibilità
- Tenere lo stesso bus alla stessa velocità e aumentare le linee dati per aumentare l’ampiezza del bus. Per evitare il problema di bus troppo ampi si opta per un bus multiplexato, dove invece di tenere linee di indirizzo e di dati separati, si utilizzano le stesse 32 linee per tutte e due, questo rallenta però il sistema
Temporizzazione del bus
Se parliamo di temporizzazione dei bus, allora dobbiamo dividerli in due categorie :
- bus sincroni : ogni operazione è orchestrata da un segnale di clock, e quindi richiede un certo numero di cicli di bus per essere eseguita
- bus asincroni : non ha un orologio principale e quindi ogni operazione non è orchestrata da un segnale di clock
Bus sincroni
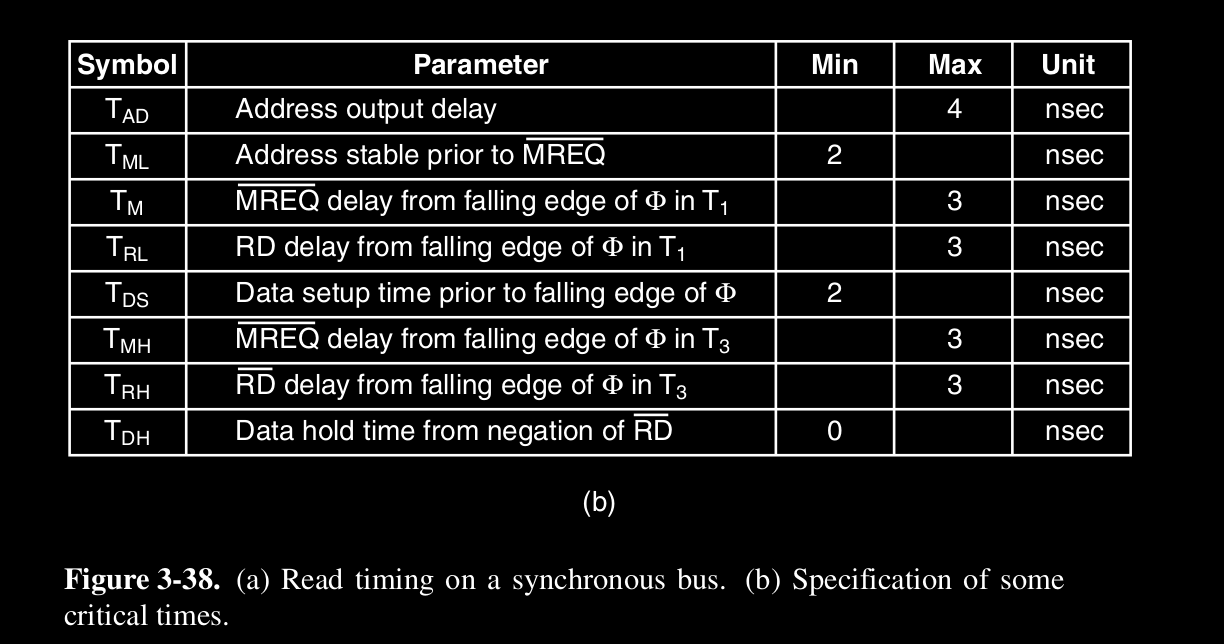
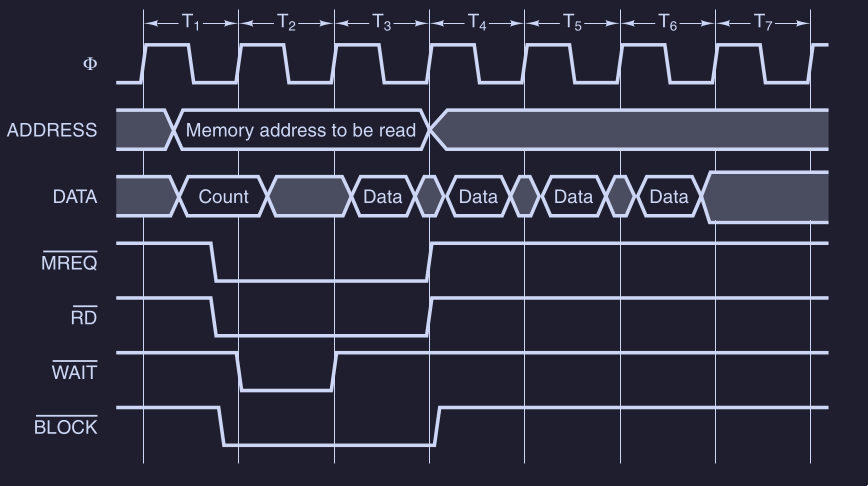
Come esempio consideriamo la seguente temporizzazione :
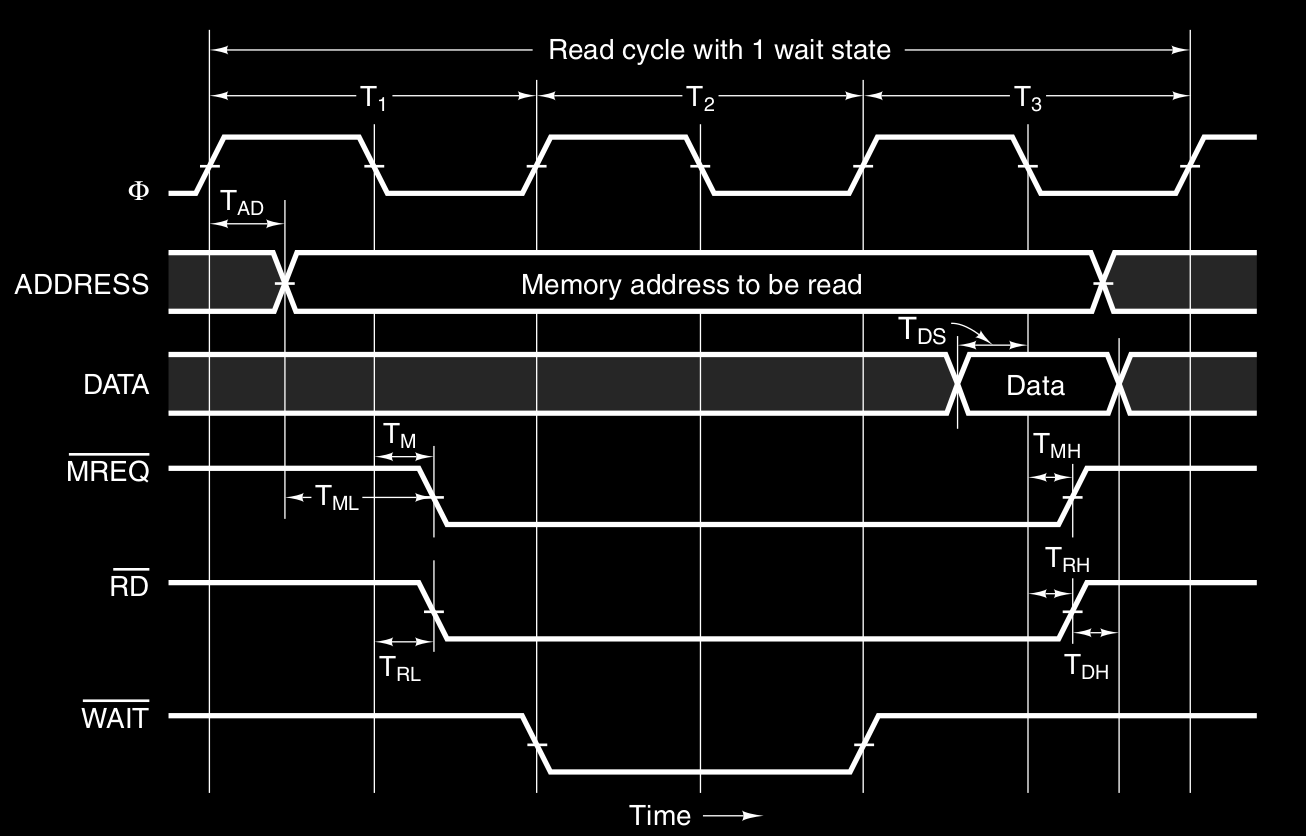
dove si utilizza un clock a 100 MHz che fornisce un ciclo di bus di 10 ns. Di solito, per i problemi visti prima ( disallineamento, retro-compatibilità … ), i bus moderni operano a velocità non elevata. Per esempio il bus PCI ha una frequenza di clock tra i 33 MHz e i 66 MHz. Supponiamo inoltre che la memoria per leggere un dato ( dopo che ha ricevuto l’indirizzo - sia stabile ) ci metta 15 ns. Quindi la questione è che la CPU è “impaziente” ed è molto veloce, la memoria è lenta, quindi dobbiamo necessariamente in qualche modo dire alla CPU “aspetta”. Infatti l’esempio mostra una lettura che richiede 3 cicli di bus, a causa di questa “lentezza”.
- Ciclo T1 : cpu inizia l’operazione di lettura
- sul fronte di salita di T1 : la CPU fornisce, dopo un piccolo ritardo , l’indirizzo della word sulle linee ADDRESS. Le linee impiegano circa 1 ns ( ecco perché non sono verticali ) per stabilizzarsi. Inoltre la zona “ombreggiata” mostra che quel valore non ci interessa
- dopo un certo ritardo , la CPU asserisce ( in logica negativa - quindi è asserito quando è basso ) ( Memory Request ) per indicare al sistema che l’indirizzo sul bus è per la memoria
- dopo un certo ritardo viene asserito il segnale , per indicare un’operazione di lettura
- Ciclo T2 : Stato di attesa
- la memoria vede asseriti i segnali e , e l’indirizzo stabile (sulle linee di address)
- la memoria, siccome ci metterà almeno 15 ns per leggere, chiede di aspettare e quindi asserisce il segnale
- per tutto il ciclo T2, la CPU aspetta la memoria, finché il segnale wait non è negativo
- è per questo ciclo aggiuntivo di attesa che i cicli di bus sono 3 e non 2
- Ciclo T3 : Lettura dati disponibili
- sul fronte di salita del ciclo T3, la memoria nega il segnale wait, in quanto sicuramente i dati saranno disponibili in questo ciclo
- la memoria mette i dati sulle linee DATA, che anche qui, ci mettono un po di tempo a stabilizzarsi
- sul fronte di discesa del clock di T3, la CPU legge i dati dalle linee DATA
- la CPU nega i segnali MREQ\RD e l’operazione è conclusa
Bus asincroni
Il problema dei bus sincroni è che se un bus sincrono ha un insieme di dispositivi, alcuni lenti e altri veloci, il bus sincrono deve essere regolato alla velocità di quello più lento, e quelli più veloci non possono sfruttare tutto il loro potenziale.
La possibile soluzione è l’utilizzo di un bus asincrono, che non possiede un clock principale.
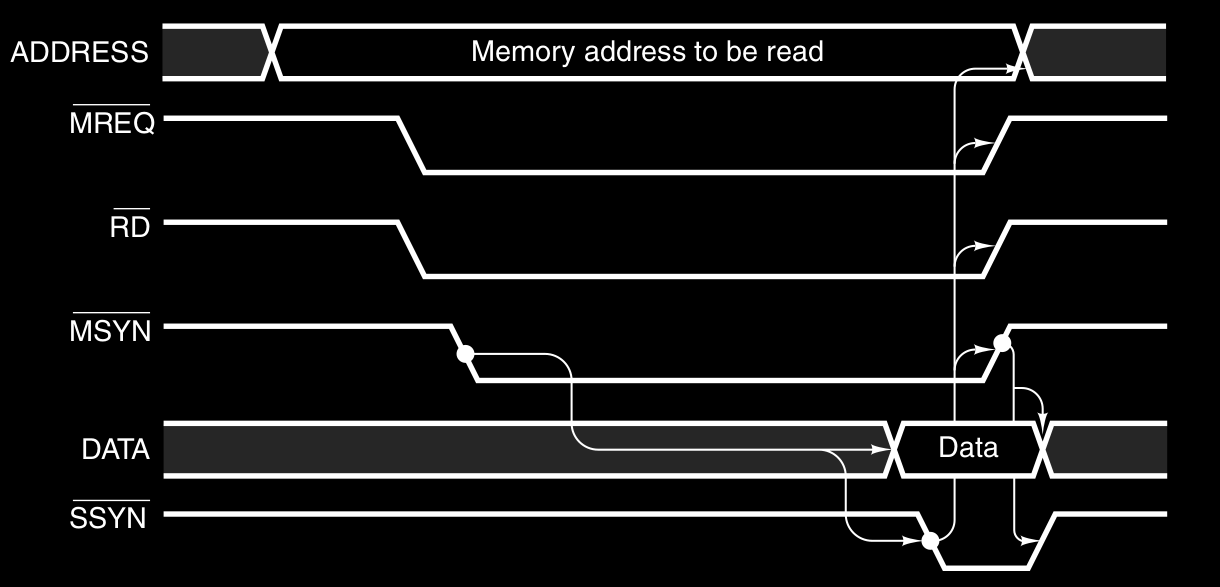
Il master del bus ( es. CPU ), invece di legare ogni operazione al clock :
- asserisce , e tutto ciò che gli serve
- asserisce ( Master SYNchronization ) - evento 1
- quando lo slave ( es. memoria ) vede questo segnale, esegue il lavoro richiesto alla massima velocità possibile
- una volta finito lo slave asserisce ( Slave SYNchronization ) - evento 2
- il master vede questo segnale asserito, e sa che i dati sono disponibili
- il master successivamente nega le linee di ADDRESS, , e , - evento 3
- lo slave vede negato , sa che il ciclo è completato è quindi nega - evento 4
- l’operazione è completata
Questi 4 eventi di coordinazione tra master e slave sono un full handshake ( stretta di mano completa ) che non dipendono dalla temporizzazione.
Il vantaggio è evidente, il bus si adatta alla velocità del dispositivo collegato in quel momento e non al dispositivo più lento che potrebbe rallentare l'intero sistema.
In verità la maggior parte dei bus sono sincroni, perché più semplici da realizzare ( non è presente nessun feedback di causa ed effetto ) e perché si è investito molto in questa tecnologia dei bus sincroni.
Arbitraggio del bus
Fino ad ora abbiamo assunto che solo la CPU è un bus master, in verità anche altri dispositivi possono diventare bus master, tra cui :
- chip I/O per scrivere e leggere la memoria
- coprocessori
Important
L’arbitraggio del bus è utilizzato per prevenire il caos, ovvero situazioni di conflitto dove uno o più dispositivi tentano di diventare, nello stesso momento, bus master.
Può essere :
- centralizzato
- decentralizzato
Centralizzato
In questo schema - chiamato daisy-chaining - un singolo arbitro di bus ( di solito costruito nella CPU ) determina chi va primo.
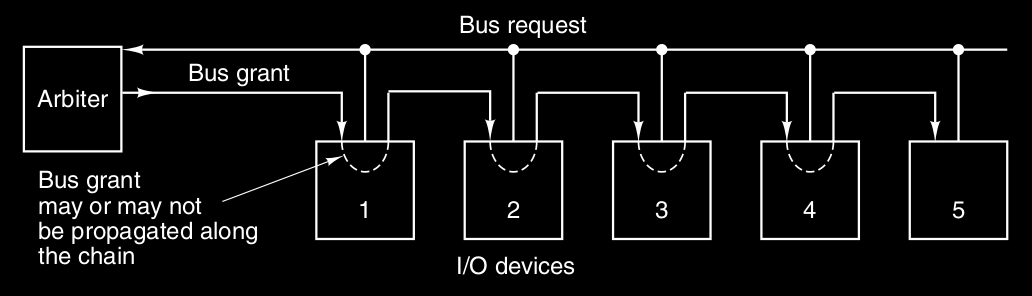
Il bus contiene una singola linea wired-OR per le richieste che può essere asserita da uno o più dispositivi alla volta. Quindi l’arbitro non sa quanti e non sa quali dispositivi hanno fatto la richiesta, vede solo questa linea asserita ( c’è almeno una richiesta ) o negata ( non ci sono richieste ). Quando l’arbitro vede la linea di richiesta asserita :
- asserisce la linea di concessione del bus ( bus grant ), il quale è connessa a tutti i dispositivi I/O in serie
- quando il dispositivo più vicino vede la concessione, controlla se ha fatto lui la richiesta :
- se si : prende il bus, e nega la concessione ai successivi
- se no : propaga la concessione ai successivi
La priorità quindi è basata su chi è più vicino all'arbitro.
Per aggirare il problema che la priorità è cablata e che quindi dipende dalla distanza del dispositivo, molti bus hanno livelli di priorità multipli :
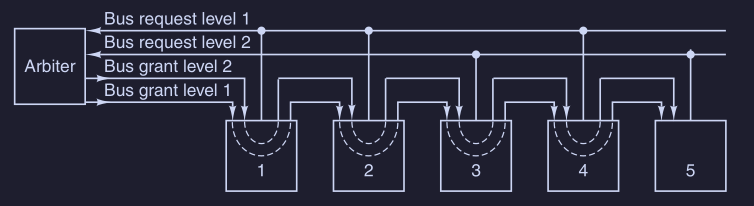
( questo in figura ha 2 livelli di priorità, di solito i bus hanno 4, 8 o 16 livelli ) Per ogni livello di priorità ci sono linee di richiesta del bus e linee di concessione del bus (grant). Quindi ai dispositivi la cui temporizzazione è critica vengono assegnate priorità piu alte. Inoltre tra dispositivi con la stessa priorità viene utilizzato il metodo daisy-chaining.
Alcuni arbitri hanno una terza linea che viene asserita da un dispositivo nel momento in cui accetta la concessione del bus e si impadronisce del bus. Appena viene asserita questa linea di conferma, le linee di richiesta e di concessione possono essere negate, in questo modo altri dispositivi possono richiedere il bus, mentre il primo dispositivo lo sta usando ancora. In questo modo si sfrutta al meglio i cicli del bus.
Nei sistemi in cui la memoria è collegata al bus principale, la CPU deve competere con tutti i dispositivi I/O per il bus ad ogni ciclo. Una soluzione è dare alla CPU la priorità più bassa, in questo modo la CPU può sempre aspettare ma i dispositivi I/O non possono aspettare siccome perderebbero i dati in entrata.
Decentralizzato
Primo metodo
In un primo metodo di arbitraggio decentralizzato, ogni dispositivo ha una sua linea di richiesta con una priorità predefinita.
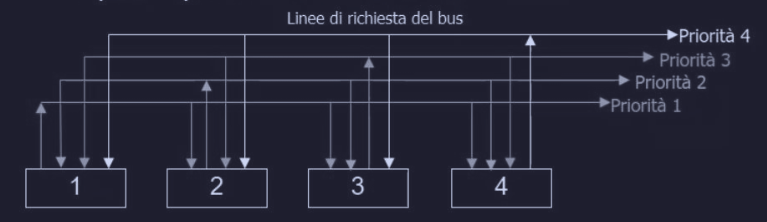
Quando un dispositivo vuole usare il bus asserisce la linea di richiesta corrispondete. Tutti i dispositivi monitorano tutte le linee di richiesta, in modo che alla fine di ogni ciclo del bus, ogni dispositivo può sapere se era il richiedente con priorità più alta e se quindi ha diritto all’utilizzo del bus durante il ciclo successivo.
A differenza di quello centralizzato, questo metodo di arbitraggio utilizza più linee di bus di richiesta, ma evita il costo dell'arbitro. Inoltre il numero di dispositivi non può superare quello delle linee di richiesta.
Secondo metodo
In un secondo metodo di arbitraggio decentralizzato del bus, vengono utilizzate solo 3 linee, indipendentemente dal numero di dispositivi presenti.
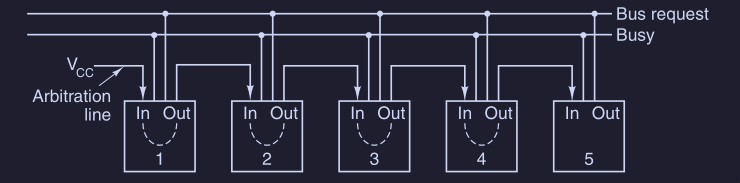
Le linee che si utilizzano sono :
- linea wired-OR per le richieste del bus
- lineaBUSY asserita dal muster del bus corrente
- linea utilizzata per arbitrare il bus, collegata con daisy-chaining a tutti i dispositivi e la testa di questa “catena” è mantenuta asserita dall’alimentazione
Per ottenere il bus, il dispositivo deve :
- controllare che il bus BUSY sia inattivo
- controllare che il segnale di arbitraggio
IN( che passa a tutti ) sia asserito- se
INè negato, non diventa il muster del bus e negaOUT - se
INè asserito, negaOUTin modo che il successivo ( e gli altri di conseguenza ) vedràINnegato e negherà a sua volaOUT
- se
Una volta finita la “catena” e a tutti sarà arrivato il segnale in IN, rimarrà solo uno che avrà IN asserito e OUT negato; esso asserisce BUSY e diventa master del bus, una volta finito il trasferimento nega BUSY ( liberandolo ) e asserisce OUT in modo da ripristinare la daisy-chaining.
Tra tutti i dispositivi che richiedono il bus, lo avrà quello che sta più a sinistra. Inoltre questo tipo di arbitraggio è simile a quello centralizzato a daisy-chaining ma non ha l’arbitro, è più economico, più veloce e non è soggetto a errori dell’arbitro.
Operazioni del bus
Fino ad ora abbiamo parlato solo di bus ordinari con un master che legge da uno slave o scrive su di esso. In verità esistono altre operazioni del bus.
Utilizzo della caching
Quando si utilizza la cache è preferibile prelevare in una volta un’intera linea di cache ( es. 8 word consecutive da 64-bit ). Inoltre spesso i trasferimenti a blocchi sono più efficienti di una sequenza di trasferimenti individuali.
In questa figura è mostrata una modifica della temporizzazione, aggiungendo un nuovo segnale che indica che è richiesto un trasferimento a blocchi.
- all’inizio della lettura di un blocco il master del bus comunica il numero di parole che devono essere trasferite
- lo slave invece di ritornare una sola parola ( Data ), ritorna una parola ad ogni ciclo finché il conteggio del numero di parole non è finito
Attention
La definizione di ciclo del bus dipende dal contesto, infatti se parliamo di bus sincroni, con ciclo del bus si intende come il singolo ciclo che determina un’attività del bus ( indirizzamento, Wait … ). Invece in altri contesti ( come in questo ), con ciclo del bus si intende per l’insieme delle attività del bus che compongono una singola operazione ( lettura, scrittura … )
Problema del sistema multiprocessore e bus
In un sistema multiprocessore con due o più CPU sullo stesso bus è necessario assicurarsi che, in un dato momento, soltanto una CPU utilizzi delle strutture dati critiche della memoria. Una tipica soluzione è di mettere in memoria una variabile lock che vale 0 quando nessuna CPU sta utilizzando la struttura dati e 1 quando è in uso. Quando una CPU vuole accedere alla struttura dati, deve leggere lock e se vale 0 impostarla a 1.
Il problema è che due CPU possono portare al caos se vedono entrambe la variabile a 0 e la impostano a 1, penseranno di essere l'unica CPU che sta utilizzando la struttura dati.
Una soluzione infatti è l’esistenza di uno speciale ciclo di bus read-modify-write, che permette di leggere una parola dalla memoria, analizzarla e riscriverla in memoria, senza rilasciare il bus.
Gestione degli interrupt - interrupt handling
Un’altro tipo di ciclo di bus è per la gestione degli interrupt. Infatti quando una CPU ordina ad un dispositivo I/O di fare qualcosa, si aspetta di solito un interrupt quando il dispositivo ha finito e la segnalazione di questi interrupt richiede l’utilizzo del bus. Il problema è che anche qui bisogna gestire la priorità, perché più dispositivi possono voler generare un interrupt. Infatti la soluzione è assegnare priorità ai dispositivi e di utilizzare un arbitro centralizzato per dare priorità al dispositivo con la temporizzazione più critica
Il chip controllore di interrupt più diffuso è il 8259A ( Intel )
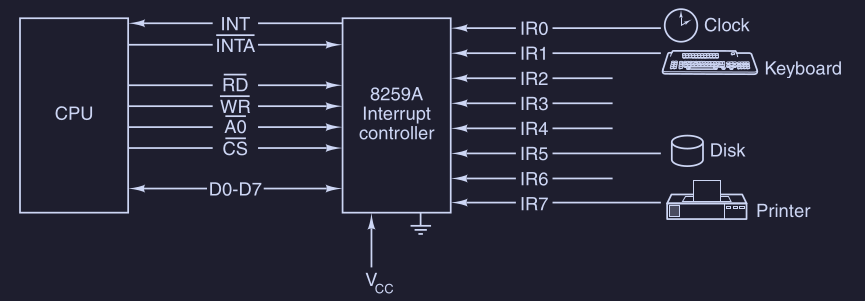
Il chip ha otto input IRx ( Interrupt Request ) ai quali possono essere collegati fino a 8 dispositivi I/O.
Quando un dispositivo vuole generare un interrupt :
- asserisce la propria linea di input
- quando uno o più input
IRxsono asseriti il chip 8259A asserisceINT(INTerrupt ) che arriva alla CPU - quando la CPU è in grado di gestire l’interrupt, rispedisce al chip un impulso su
INTA( INTerrupt Acknowledge ) - il chip deve specificare quale input
IRxha richiesto l’interrupt, generando il suo numero sul bus dati ( richiede ciclo di bus speciale ) - la CPU utilizza quel numero come indice all’interno di una tabella di puntatori - vettore di interrupt - per cercare l’indirizzo della ISR ( Interrupt Service Routine )
Inoltre all’interno del chip 8259A ci sono vari registri che la CPU può leggere e scrivere in modo da gestire il chip.
Quando sono presenti più di 8 dispositivi I/O vengono messi in cascata più chip.