
Il controllo del flusso è la sequenza con cui le istruzioni vengono eseguite durante l’esecuzione del programma. Le chiamate di procedura ( e anche gli interrupt ) alterano il controllo del flusso. Infatti molte istruzioni non alterano il controllo del flusso, ovvero che dopo l’esecuzione di un’istruzione, il program counter viene incrementato della lunghezza dell'istruzione elaborata, e quindi viene eseguita l’istruzione successiva a quella appena elaborata.
Procedure ricorsive
Le procedure ricorsive sono quelle procedure che richiamano se stesse. Lo studio delle procedure ricorsive aiuta la comprensione del modo in cui sono implementate le chiamate di procedura e della natura delle sue variabili locali.
Vediamo un esempio di procedura ricorsiva, considerando il problema delle “torri di Hanoi”, dove abbiamo 3 pioli ( peg ) e nel primo sono inseriti dischi ( figura con 5 dischi ):
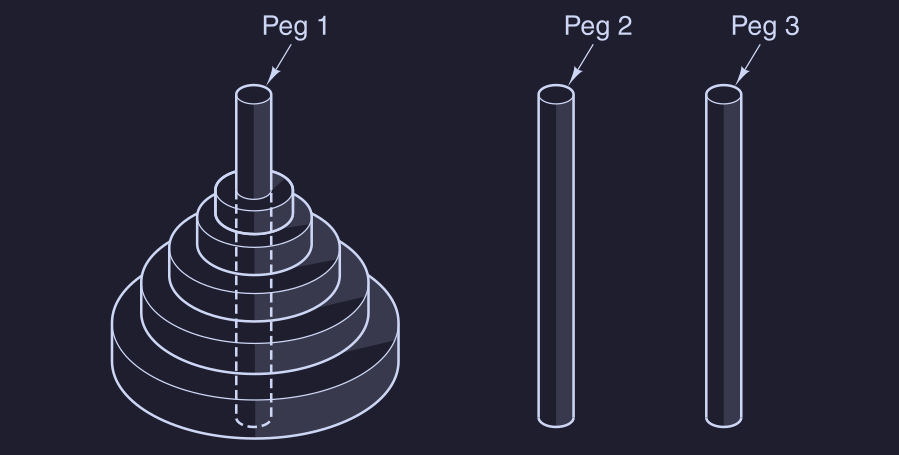
dove il problema sta nel trasferire gli dischi ( uno alla volta ) dal primo piolo al terzo, senza inserire un disco sopra uno più grande. Una soluzione sta nel muovere dischi dal piolo 1 al piolo 2, in modo da mettere l’ultimo disco più grande nel piolo 3, e poi muovere dischi dal piolo 2 al piolo 3 ( figura con 3 dischi ):
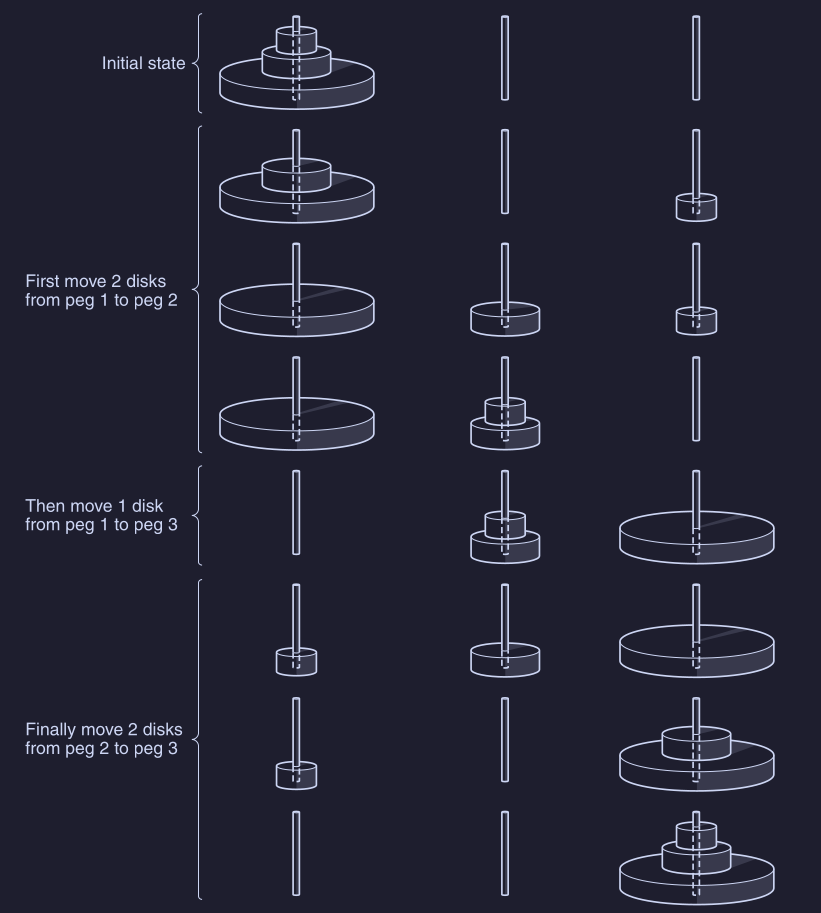
Possiamo implementare questa soluzione attraverso una procedura towers(n,i,j), dove i parametri stanno per “sposto gli n dischi da i a j” :
public void towers(n,i,j){
if (n == 1){
System.out.println("Sposto un disco da "+i+" a "+j);
}else{
k = 6 - i - j; // numero piolo temporaneo (di appoggio)
towers(n-1,i,k);
towers(1,i,j);
towers(n-1,k,j);
}
}Per gestire le procedure ricorsive viene utilizzato uno stack per memorizzare i parametri ( n,i e j ) e le variabili locali ( k ) a ogni chiamata.
Ogni volta che una procedura viene chiamata viene allocato uno stack frame in cima allo stack per la procedura stessa. Quindi inoltre al SP ( stack pointer ) risulta conveniente avere un puntatore anche allo stack frame, FP ( frame pointer ) per poter accedere a variabili locali o parametri.
Vediamo ora come si comporta lo stack in momenti diversi :
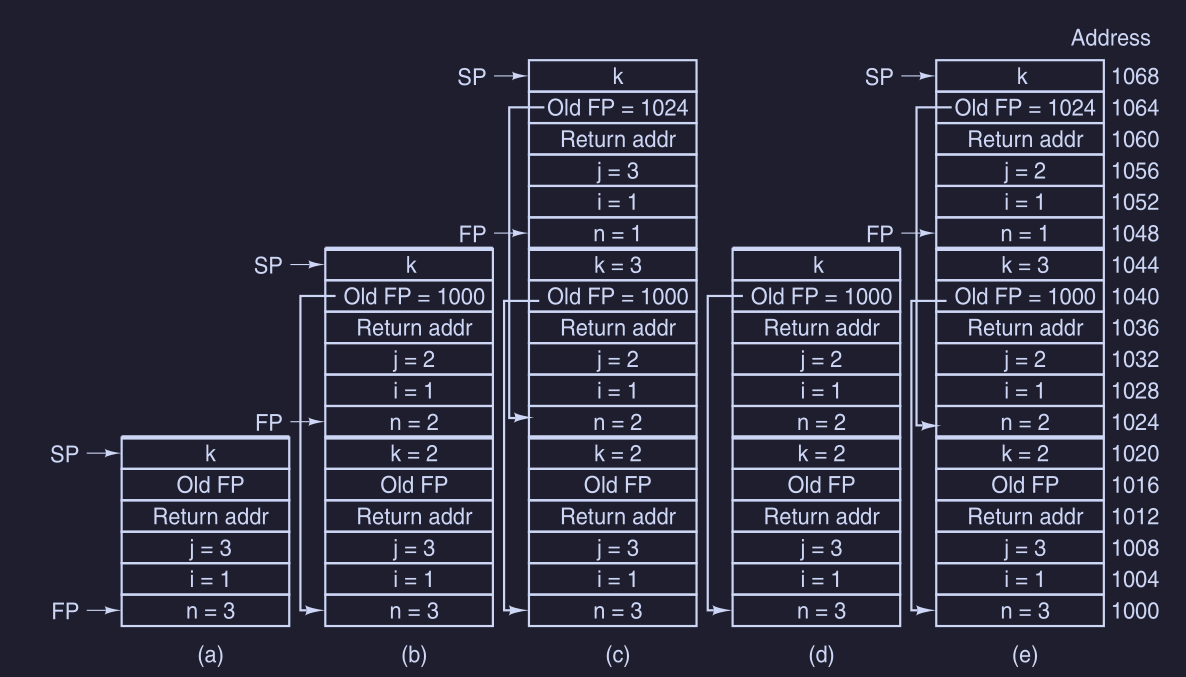
La prima chiamata originale towers(n,i,j) pusha nello stack n, i e j e esegue un’istruzione CALL che pusha nello stack l’indirizzo di ritorno ( del main ).
Nel momento dell’ingresso, viene “pushato” il vecchio valore FP ( del main ) e incrementa SP per allocare spazio alle variabili locali ( k ).
Quando viene chiamata un’altra procedura ricorsivamente, si fa la stessa roba, sempre tenendo nello stack lo stack frame della procedura precedente.
Coroutine
Consideriamo uno scenario con una procedura A e una procedura B, dove A chiama B e B ricomincia sempre dall’inizio, e quando ha finito B ritorna su A. In questo A e B sono asimmetriche perché A avanza ma B ricomincia sempre dall’inizio, viceversa le coroutine sono procedure simmetriche ovvero le procedure sono alla pari, e si passano il controllo tra di loro.
Le coroutine sono utili per una simulazione di parallelismo, ovvero che su una singola CPU si fa credere a due task stanno girando in parallelo, ma in realtà si scambiano il controllo tra di loro in continuazione.
Trap
È una specie di chiamata di procedura automatica, che viene effettuata quando si verificano alcune condizioni ( eventi che si verificano raramente ). Un esempio è l’overflow, dove quando in un computer il risultato di un’operazione aritmetica eccede il più grande numero rappresentabile, si verifica una trap, e il controllo del flusso viene interrotto e riparte da una locazione di memoria prefissata, invece di proseguire in sequenza. Nella locazione di memoria prefissata si trova l’indirizzo per un salto ad una procedura di trap handler ( gestore di trap ) che svolge le azioni appropriate al caso.
Interrupt
Gli interrupt sono cambiamenti del flusso esecutivo causati non dal programma in esecuzione, ma di solito da qualche altro problema ( di solito causato da I/O ). Per esempio un programma può ordinare al disco di iniziare il trasferimento delle informazioni e di inviare un interrupt non appena il trasferimento termini. Come nelle trap, gli interrupt interrompono il programma e trasferiscono il controllo a un handler di interrupt.
Consideriamo un esempio : un calcolatore deve scrivere sullo schermo una riga di caratteri, allora i step da seguire sono i seguenti :
- Azioni hardware :
- il controllore del dispositivo attiva una linea di interrupt sul bus di sistema
- la CPU attiva sul bus un segnale di conferma dell’interrupt
- il controllore del dispositivo vede la conferma ed invia sulla linea dati un intero che lo identifica - chiamato vettore di interrupt
- la CPU preleva il vettore di interrupt e lo salva
- la CPU pusha il
PCePSWnello stack ( in modo da ritornarci dopo ) - la CPU usa il vettore di interrupt per cercare il nuovo
PCche punta all’inizio della routine di servizio dell’interrupt - ISR
- Azioni software :
- la routine inizia a salvare tutti i registri che utilizza ( per ripristinarli dopo )
- lettura delle informazioni sull’interrupt, come il codice di stato
- gestire eventuali errori I/O
- creano due variabili globali, che poi vengono aggiornate
ptr: punta all’inizio del buffer ( aggiornata incrementandola in modo che punti al byte successivo )count: # di caratteri da visualizzare ( aggiornata decrementandola per indicare che manca un byte in meno da visualizzare )
- se richiesto, viene inviato un codice al dispositivo o al controllore dell’interrupt, per indicare che l’interrupt è stato trattato
- ripristino di tutti i registri salvati
- ripresa delle attività dal momento dell’interrupt
Ricordiamo inoltre che anche per gli interrupt esistono dei livelli di priorità.