
Ogni calcolatore deve poter ricevere e fornire informazioni con gli umani, e quindi è necessario che riconosca almeno i caratteri dell’alfabeto. I calcolatori per utilizzare questi caratteri gli assegnano loro un numero naturale, questo è chiamato codice o codifica dei caratteri. Infatti due calcolatori per poter comunicare tra di loro è necessario che utilizzino lo stesso codice, per questa ragione sono stati definiti alcuni standard :
- ASCII ( American Standard Code for Information Interchange )
- UNICODE
- UTF-8
ASCII
È il codice più utilizzato e per codificare un carattere e utilizza 7 bit ( sarebbe 1 byte → 8 bit e il primo bit a 0 ), che quindi può codificare 128 caratteri .
I codici iniziali che vanno da 0 a 1F sono caratteri di controllo e non sono stampabili :
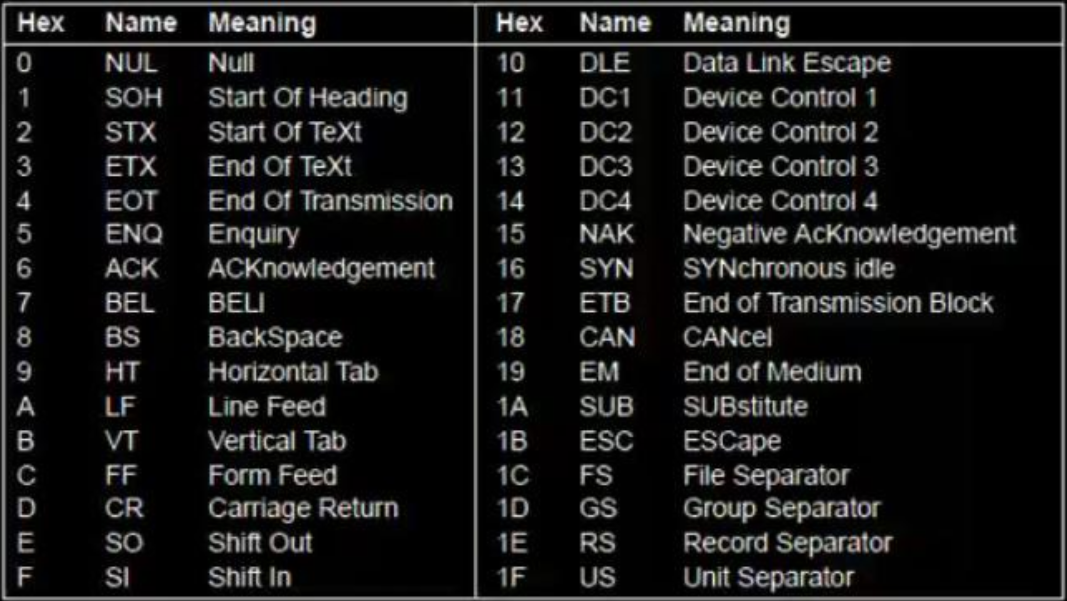
Il problema è che questa codifica funziona bene con il linguaggio anglosassone e non per altre lingue con caratteri diversi, infatti 128 caratteri non bastano ( il cinese ha circa 7000 caratteri e non ha l’idea dell’alfabeto ).
Il primo tentativo era di utilizzare un bit in più ( diventava così a 8-bit ) in modo da arrivare a 256 caratteri chiamato Latin-1.
Questo tentativo non bastò, così un gruppo di produttori di calcolatori ha creato un nuovo sistema chiamato UNICODE.
UNICODE
L’idea sarebbe nell’assegnazione ad ogni carattere un valore a 16-bit chiamato code-point, il fatto che sono 16-bit rende più facile la scrittura di programmi. Con 16-bit abbiamo quindi 65 536 code point ( combinazioni ), inoltre il consorzio ha deciso di usare Latin-1 per i code point compresi tra 0 e 255, rendendo facile la conversione tra ASCII e UNICODE.
I problemi dell’UNICODE sono :
- ordinamento degli ideogrammi : mentre le lettere dell’alfabeto latino sono nell’ordine corretto, gli ideogrammi Han non sono ordinati come nel dizionario
- nascita di nuove parole ⇒ nuovi ideogrammi nel giapponese
- utilizzo dello stesso code point per caratteri giapponesi e cinesi che hanno aspetto simile, siccome i code point sono limitati
Cosi nel 1996 furono aggiunti 17 plane ( piani ) da 16 bit ciascuno portando il numero di caratteri a 1 114 112 .
UTF-8
Ok come facciamo a rappresentare un code point in binario? Sono stati sviluppati vari modi ma il più utilizzato è lo standard UTF-8 ( Universal Character Set Transformation Format ) che può codificare 2 miliardi di caratteri. UTF-8 è un sistema a lunghezza variabile per i caratteri UNICODE, ovvero che non tutti i caratteri utilizzano lo stesso numero di byte
- alcuni 1 byte ( come ASCII )
- altri 2, 3, o 4 byte
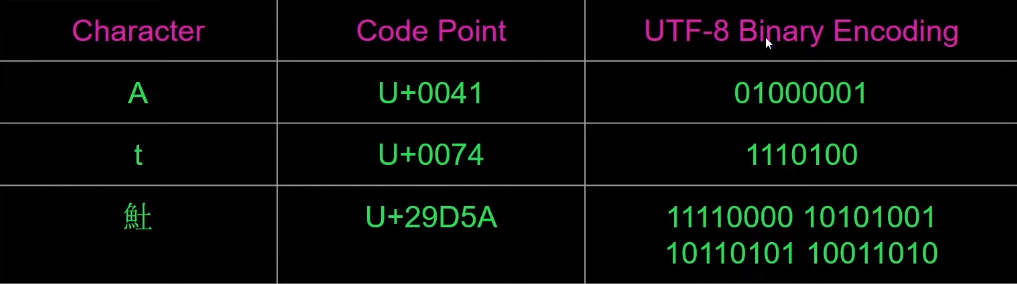
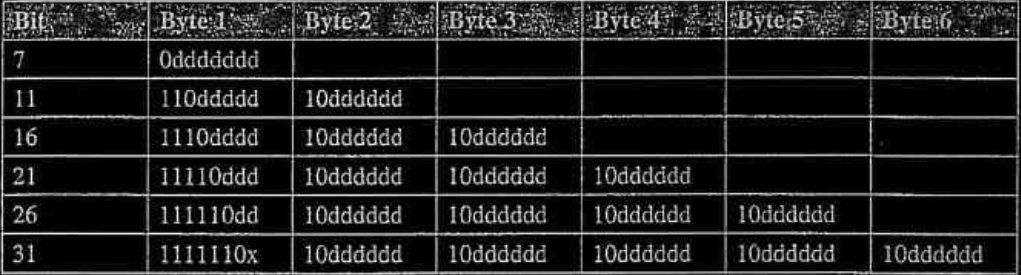
L’algoritmo di codifica funziona in questo modo :
- se si necessitano più byte, il primo bit più significativo del primo byte è impostato a “uni” per indicare se servono bytes.
- se si necessitano più byte, il secondo byte dopo il primo inizia sempre con
Example
Il carattere א ( alif dall’arabo ) corrisponde all’UNICODE : U+05D0, ovvero al valore binario , quindi necessita sicuramente di bytes, quindi avremo uno schema del genere da “riempire” :
quindi se iniziamo a prendere dal bit che vale di più ( ovvero il primo da sinistra verso destra ) riusciamo a riempire perfettamente lo schema :
ovvero in hex :
I vantaggi nell’utilizzare questo sistema sono :
- ottimizzato, infatti basta 1 byte per ASCII
- auto-sincronizzante, infatti dal numero di “uni” è possibile determinare il numero di byte del carattere
- se si scoprissero nuove lingue, il sistema è in grado di codificarle