
- Come garantire le prestazioni del file system?
Come sappiamo benissimo l’accesso al disco è molto più lento di un accesso alla memoria. Per questa differenza di tempo di accesso, in molti file system sono stati progettati diverse ottimizzazioni per migliorare le performance, riducendo al minimo :
- numeri di accessi al disco/SSD
- tempo di ricerca (seek) del dato sul disco/SSD
- utilizzo dello spazio
Infatti tra le ottimizzazioni delle prestazioni abbiamo :
- block cache / buffer cache : utilizzata per ridurre i tempi di accesso al disco, mantenendo i blocchi più usati in memoria
- allocazione intelligente : blocchi vicini nello stesso cilindro per minimizzare il movimento del braccio del disco
- bitmap in memoria per allocare blocchi contigui e migliorare l’efficienza di scrittura sequenziale (meglio della free list siccome i bit sono in ordine fisico e quindi è meglio per allocare blocchi contigui)
- deframmentazione : con il tempo i dischi si frammentano, ovvero che i dati dei file sono sparsi portando a prestazioni inferiori
- con la deframmentazione vengono riorganizzati i file per essere contigui e raggruppa lo spazio libero
- windows offre il tool
defragper questa operazione (consigliato per HDD ma non per SSD)
Caching - block / buffer cache
Per minimizzare gli accessi al disco tramite caching, vengono memorizzati i blocchi del disco in RAM.
- buffer cache (o block cache) : memorizza i blocchi grezzi del disco
- page cache : memorizza le pagine di dati del disco in RAM (utilizzato con VFS) (gestiti come pagine di memoria)
Info
Oggi il page cache ha assorbito il ruolo del buffer cache e tutto il I/O bufferizzato passa dalla page cache prima. Inoltre la vulnerabilità CopyFail si basa proprio sulla page cache, dove riesce a scrivere una page cache di un binario come
sue riuscire a diventare root.
Quando viene richiesta la lettura di un blocco del file :
- verifica nella cache
- se c’è ottimo
- altrimenti, il blocco viene prima letto dal disco, portato nella cache e poi utilizzato
Esempio con grep :

La ricerca del blocco nella cache in modo sequenziale è lento, per questo si usa la tecnica a dizionario/hash, dove viene utilizzata una funzione hash per identificare velocemente la presenza di un blocco nella cache e nel caso di blocchi con lo stesso hash (collisione), vengono messi in una lista concatenata (già visto nel corso di Programmazione) :
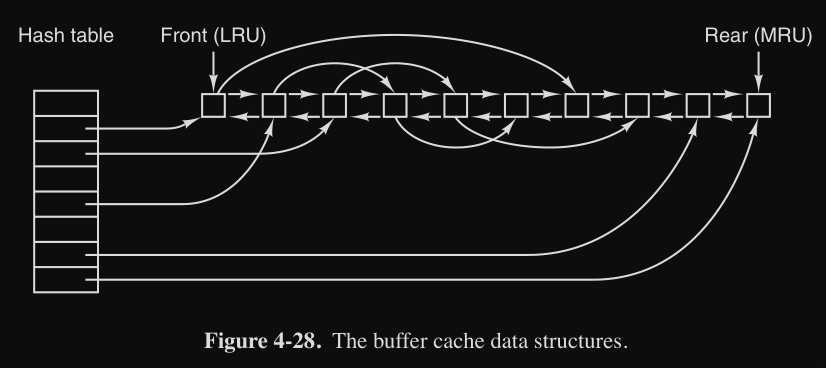
Ricerca blocco da sostituire
Un altro problema da considerare è quando la cache diventa piena. In questo caso bisogna scegliere quale blocco sostituirlo e se “sporco” va scritto su disco (insomma come paging).
Algoritmi per il paging come FIFO, FIFO2 e LRU sono applicabili anche qua. L’algoritmo LRU in questo caso utilizza una lista bidirezionale, dove i blocchi sono tenuti in ordine d’uso (- recenti in testa e + recenti in fondo).
Il LRU butta il blocco più vecchio, ma il problema è che non distingue tra blocchi puliti e sporchi.
Rischio: un blocco sporco importante (es. i-node) può essere buttato fuori perché “vecchio”, mentre blocchi puliti appena letti restano in cache. Crash → dati persi → file system inconsistente.
LRU modificato: prima di buttare un blocco, controlla se è sporco. Se sì, lo scrive su disco, poi lo elimina. I blocchi puliti vengono eliminati per primi, perché sono già al sicuro.
Crash sistema e soluzioni
Inoltre per evitare che un crash ci distrugga i file, il OS interviene con due regole di sicurezza :
- scrittura immediata dei blocchi critici : appena modificati vengono scritti su disco
- scrittura periodica dei blocchi normali :
- in UNIX si usa un daemon che lancia periodicamente la system call
sync, che prende tutti i blocchi modificati che sono nella cache e li riversa su disco
- in UNIX si usa un daemon che lancia periodicamente la system call
La filosofia di Windows (MS-DOS) era di scrivere immediatamente tutti i blocchi modificati, siccome questo non è efficiente, è stata integrata la chiamata FlushFileBuffers che può essere chiamata dai programmi (decidono loro quando svuotare su disco) (inoltre Windows ora con NTFS adotta il meccanismo di journaling).
Comando free (Linux)
In Segmentazione abbiamo già incontrato il comando free che ci permette di avere una panoramica dettagliata del utilizzo della RAM, inclusa la cache e lo spazio libero, in particolare :
buff/cache: rileva quanto spazio RAM il sistema sta utilizzando per la cache dei blocchi del discofree: spazio RAM completamente vuotoavailable: colonna che dobbiamo vedere se vogliamo sapere se possiamo far partire un nuovo programma
La differenza tra le due colonne free e available è la seguente :

Deframmentazione del disco
Abbiamo già descritto il problema della frammentazione e la soluzione tramite la deframmentazione.
Facciamo alcune osservazioni :
- la deframmentazione è utile solo nei HDD e non sui SSD (per evitare scritture inutili)
- su Windows il
defragsi usa spesso, ma su Linux non serve quasi mai, siccome utilizza fs come ext3/ext4 che utilizzano la pre-allocazione dei blocchi (vedi Linux_FS)
Mentre se il disco risulta pieno, esistono due tecniche avanzate che permettono al fs di recuperare spazio :
- compressione :
- lavora all’interno dei file
- cerca sequenza di dati che si ripetono e la sostituisce con una formula più leggera (es. A A A A A A )
- utilizzato automaticamente da molti fs come NTFS (Win) e Btrfs/ZFS (Linux)
- deduplicazione :
- lavora sull’intero disco
- cerca file o blocchi di dati identici, conservando una sola copia di ciascun dato
- utile nei server dove ci sono dati condivisi
Nella deduplicazione il sistema utilizza un hash per capire se due blocchi dati sono uguali. Il problema è che ci possono essere delle collisioni (rare ma possibili), quindi è necessario un double check per assicurarsi che i due blocchi siano uguali.