
Mentre gli utenti si preoccupano di come i file sono denominati e delle operazioni disponibili, agli sviluppatori del file system interessa di come i file e le directory sono memorizzati e come è gestito lo spazio su disco.
Infatti cercheremo di rispondere alle seguenti domande:
- come memorizzare i file?
- come implementare le directory?
- come gestire lo spazio su disco ? Gestione_spazio_disco
- come garantire le prestazioni del file system? Performance_FS
- come garantire l’affidabilità del file system? Affidabilità_FS
Gli argomenti principali relativi alla implementazione del file system sono :
- layout del file system
- realizzazione dei file (gestione allocazione)
- realizzazione delle directory
Implementazione dei file
Cerchiamo ora di rispondere alla domanda :
- come memorizzare i file?
Layout del file System
I dischi possono essere suddivisi in una o più partizioni ed ogni partizione può avere un suo file system.
I metodi di layout del file system dipendono a secondo dell’epoca del computer.
Due schemi di partizionamento :
| Schema | Firmware associato | Caratteristiche |
|---|---|---|
| MBR (Master Boot Record) | BIOS legacy | Settore 0, max 2.2 TB, 4 partizioni primarie |
| GPT (GUID Partition Table) | UEFI | Tabella + backup, max 8 ZiB, partizioni illimitate |
BIOS con MBR - vecchia scuola
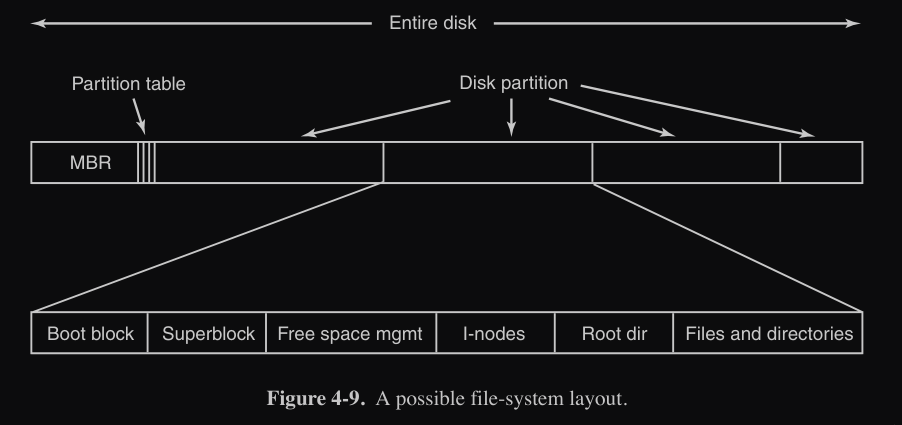
Un “vecchio” schema del layout del file system è quello con BIOS con MBR (Master Boot Record) :
- MBR è nel settore 0 del disco ed è utilizzato per avviare il computer
- alla fine del MBR c’è la tabella delle partizioni : specifica inizio e fine di ogni partizione
- nella tabella delle partizioni, una sola partizione è contrassegnata come attiva
- quanto il computer è avviato :
- BIOS legge ed esegue il MBR
- MBR localizza la partizione attiva
- MBR legge ed esegue il primo blocco (boot block) della partizione attiva per avviare l’OS
Ogni partizione è così costituita :
- Boot Block : primo blocco di ogni partizione, dove il programma all’interno carica il OS contenuto nella partizione di riferimento
- superblock : contiene i parametri chiave del file system
- gestione dello spazio libero : informazioni sui blocchi non allocati
- i-nodes
- root directory
- file e directory
UEFI - nuova scuola
Il sistema UEFI (Unified Extensible Firmware Interface) sostituisce il vecchio BIOS.
I suoi vantaggi principali sono :
- avvio più veloce : ottimizza processo di inizializzazione hardware
- UI avanzata : può includere grafica + mouse
- compatibilità con hardware a 32 e 64 bit
- sicurezza con la funzionalità di secure boot
UEFI funziona con GPT (GUID Partition Table), ovvero un sistema moderno per “disegnare” la mappa delle partizioni. Consente inoltre di superare i limiti di 2.2 TB dei dischi gestiti con MBR.
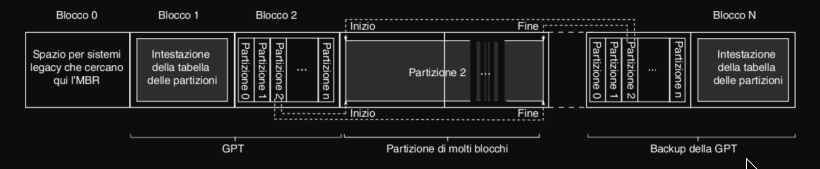
- supporta dischi fino a 8 ZiB (zettabyte)
- consente numero illimitato di partizioni (limite imposto solo dal OS)
- include backup della tabella delle partizioni per maggiore sicurezza
- controllo di integrità (CRC) per evitare la corruzione dei dati
Su ogni disco formattato in GPT, esiste una piccola partizione chiamata ESP (EFI System Partition) che :
- archivia i file di avvio (bootloader) del OS
- essenziale per avviare il OS
- utilizza il file system FAT32, siccome è semplicissimo e compatibile con il firmware UEFI
La funzionalità del secure boot è stata progettata per impedire l’avvio di software non autorizzato :
- controlla le firme digitali dei bootloader
- mantiene integrità del OS
- aumenta la sicurezza per utenti domestici e aziende
:luc_youtube: BIOS and UEFI - CompTIA A+ 220-901 - 1.1
Realizzazione dei file - schemi di allocazione dei blocchi
L’aspetto importante nell’implementazione della memorizzazione dei file è tenere traccia di quali blocchi del disco sono associati ad un determinato file.
Esistono diversi metodi :
- allocazione contigua
- allocazione con liste collegate
- allocazione con tabella in memoria (FAT - File Allocation Table)
- I-nodes (Index-nodes)
Allocazione contigua
Questo schema di allocazione è quello più semplice, dove ciascun file è memorizzato coma una sequenza contigua di blocchi adiacenti sul disco.
Per esempio l’allocazione contigua di 7 file su disco :
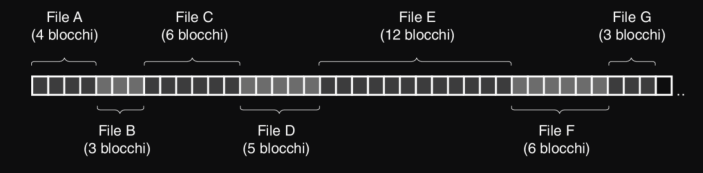
Vantaggi :
- semplicità di implementazione : per tenere traccia dei blocchi di un file, basta conoscere solo due numeri :
- indirizzo del disco del primo blocco del file
- numero di blocchi del file
- alte prestazioni in lettura : siccome l’intero file è su blocchi consecutivi, può essere letto con una singola operazione su disco
Svantaggi :
- frammentazione esterna : con la rimozione dei file nel tempo, vengono liberati blocchi che creano buchi di ampiezza variabile sul disco. Quindi quando si crea un nuovo file, gli spazi vuoti tra i file non si riescono a utilizzare

- dimensione massima nota : nella creazione del file è necessario specificarne la dimensione massima, che non è sempre nota in anticipo
- spreco interno : se la dimensione del file non è un multiplo della dimensione del blocco, si ha un piccolo spreco di spazio all’interno dell’ultimo blocco
Allocazione con liste collegate
In questo modo ogni file è gestito come una lista collegata di blocchi del disco, che non devono essere necessariamente adiacenti.
La prima word di ciascun blocco viene utilizzata come puntatore al blocco successivo, mentre il resto del blocco è riservato ai dati.
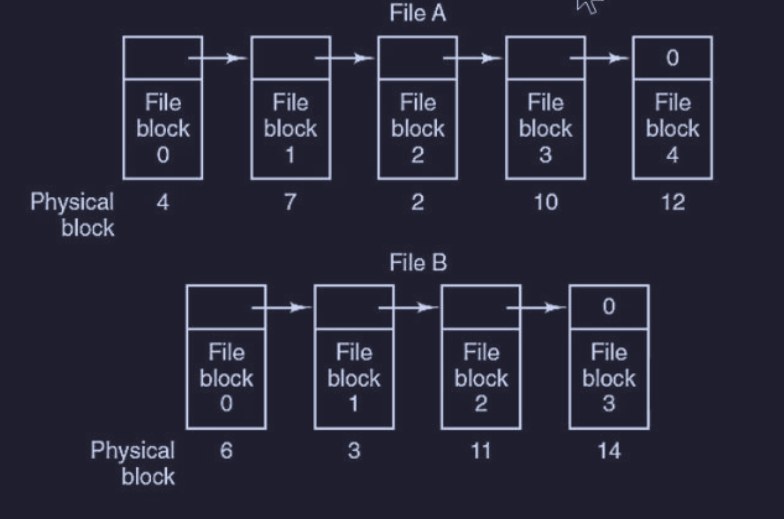
Vantaggi :
- uso efficiente dello spazio : non si verifica spreco di spazio e tutti i blocchi del disco possono essere utilizzati
- semplicità nella directory : ciascuna voce di directory deve memorizzare solo l’indirizzo del primo blocco del disco di ciascun file (contenuto nella directory)
Svantaggi :
- accesso casuale estremamente lento : per accedere al blocco bisogna prima accedere ai puntatori di blocchi precedenti per seguire la catena dei puntatori
- inefficienza di spazio : siccome la dimensione dei dati di un blocco non è una potenza di due (siccome il puntatore occupa alcuni byte), questo può portare ad alcune inefficienze per i programmi che leggono/scrivono dati espressi in
Per questi motivi l’allocazione a liste collegate è utilizzato per i file in cui si accede principalmente in modo sequenziale.
Allocazione con tabella in memoria - FAT
Entrambi gli svantaggi dell’allocazione a liste collegate possono essere rimossi, infatti i puntatori sono rimossi da ogni blocco e raccolti in una tabella centrale chiamata FAT - File Allocation Table, che risiede nella memoria principale.
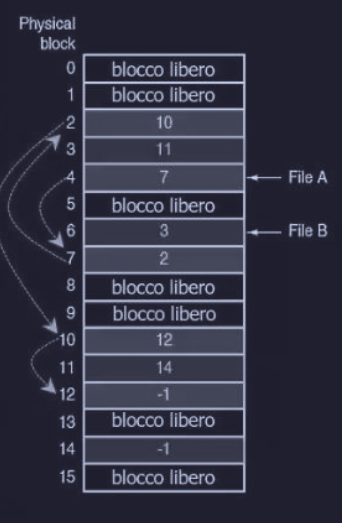
In questo modo :
- il blocco è interamente disponibile per i dati
- ogni catena di dati termina con un terminatore speciale
-1- esempio il file A utilizza i blocchi (dove termina con
-1)
- esempio il file A utilizza i blocchi (dove termina con
- accesso casuale diventa facile siccome la sequenza dei blocchi (tabella centrale) è in memoria
- la entry nella directory mantiene il numero di blocco iniziale
La tabella deve essere interamente in memoria, infatti questo diventa un problema, perché se abbiamo per esempio un disco da 200 GB e blocchi da 1 KB, la tabella viene ad occupare quasi 600 MB di RAM.
Quindi l’idea della FAT non viene bene con dischi di grandi dimensioni.
I-NODE
Questo metodo è utilizzato tipicamente nei sistemi UNIX (fondamentale in ext2/ext3/ext4), dove ad ogni file (e directory) viene associata una struttura dati fissa chiamata i-node (index-node), che elenca :
- attributi del file
- indirizzi dei blocchi di dati sul disco
Siccome la struttura i-node ha un numero fisso di posizioni, per consentire l’incremento dei blocchi dati del file, l’ultima cella è riservata per contenere un indirizzo verso un altro blocco speciale che contiene altri indirizzi di blocchi dati.
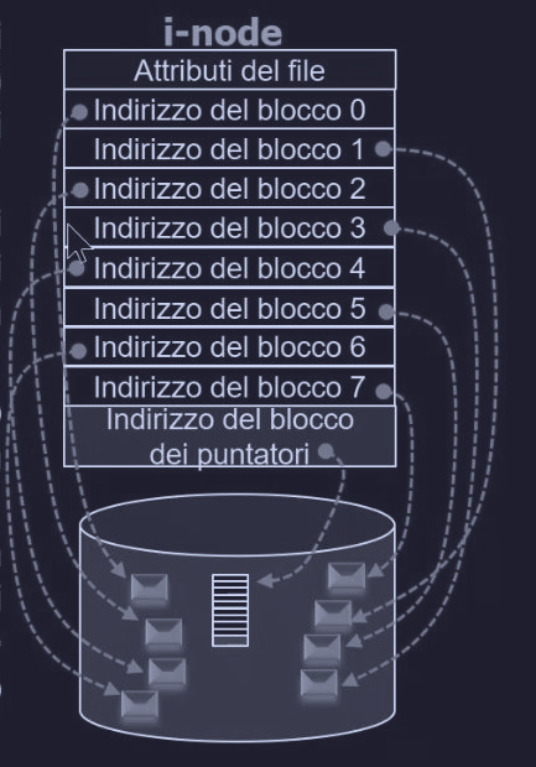
Vantaggi :
- efficienza di memoria : l’i-node di un file è in memoria solo quando il file corrispondente è aperto
- la memoria totale occupata dagli i-node è proposizionale al numero massimo di file che possono essere aperti contemporaneamente e non alla dimensione totale del disco (come nel FAT)
- gestire file di grandi dimensioni con efficienza
Implementazione delle directory
Cerchiamo ora di rispondere alla domanda :
- come implementare le directory?
Durante l’apertura di un file, il OS utilizza il path name (fornito dall’utente) per individuare la voce di directory corrispondente, che fornisce una delle due informazioni :
- indirizzo del primo blocco del disco (caso utilizzo allocazione contigua e a lista collegata)
- numero di i-node (caso utilizzo degli i-node)
Quindi la funzione della directory è associare il nome del file (fornito dall’utente) alle informazioni necessarie per la sua localizzazione.

Implementazione dei nomi di file e lunghezza variabile
Come facciamo a salvare i nomi dei file all’intero di una directory?
Quasi tutti gli OS supportano nomi di file di lunghezza variabile, con un limite di 255 caratteri. Il problema che sorge è se alloco 255 caratteri per ogni file, sprechiamo tanto spazio per file che si chiamano solo “foto.jpg”.
Esistono due soluzioni (vedi foto) :
- voci di directory di lunghezza variabile (a) : dove ogni entry (voce) è composta da :
- lunghezza entry del file
- attributi del file
- nome del file (carattere per carattere)
- gestione degli heap (b) dove ogni entry ha :
- puntatore al nome del file nel heap
- attributi del file
- poi c’è sotto l’heap che contiene uno dopo l’altro i nomi dei file
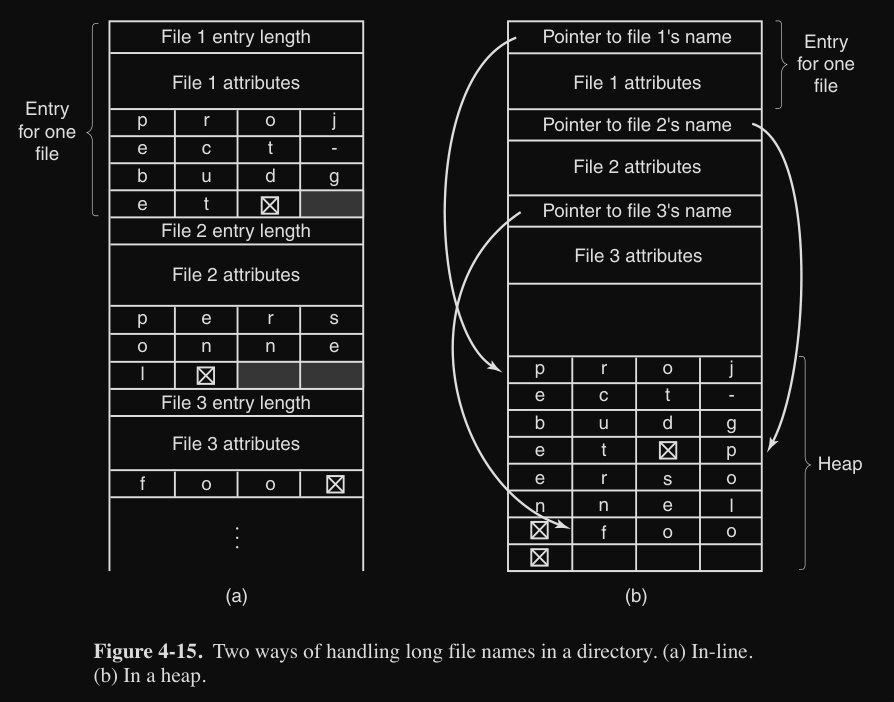
I problema è che quando un file viene rimosso, si crea un buco di dimensioni variabile (frammentazione) (si può compattare lo spazio siccome è interamente in memoria ma è un costo aggiuntivo)
Ottimizzazione ricerca nelle directory - tabelle hash + cache
La ricerca dei file in una directory inizialmente veniva fatta in modo lineare (lento). Per questo è stata introdotta la tabella hash in ogni directory per velocizzare la ricerca. Quindi il nome del file è sottoposto a hashing per generare un indice da 0 a . Come già sappiamo, dobbiamo gestire le collisioni (nome file stesso hash), utilizzando liste concatenate, quindi la ricerca verifica tutte le voci nella catena per trovare il file desiderato.
Possiamo utilizzare anche il caching delle ricerche per velocizzare le ricerche. Quindi ci salviamo i risultati delle ricerche comuni nella cache e successivamente prima di avviare una ricerca si verifica se il file cercato è nella cache.
- + complessità : uso di tabelle hash e cache introducono complessità nella gestione delle directory
- adatto a sistemi con directory piene di file