
Il file system è un’astrazione fondamentale del OS per la gestione organizzata delle informazioni su dispositivi di informazione (tipicamente dischi).
Necessità e funzioni del File System
Tutte le applicazioni informatiche richiedono di memorizzare e recuperare informazioni.
Ci sono vari problemi che portano alla necessità del file system :
- limitazione RAM : un processo in esecuzione può memorizzare una quantità limitata di informazioni nel proprio spazio di indirizzamento, ma questo spazio è insufficiente per alcune applicazioni
- perdita dati : quando un processo termina, le informazioni scritte nel suo spazio di indirizzamento vengono perse, ma molte applicazioni hanno la necessità di memorizzare per lunghi periodi le informazioni, anche se un crash del computer uccide il processo
- accesso concorrente : necessità di accesso simultaneo da più processi
Dobbiamo pensare al disco come una sequenza lineare di blocchi di dimensione fissa e che supporta due operazioni :
- leggi blocco k
- scrivi il blocco k
Important
Il file system risponde alle seguenti domande :
- come si trovano le informazioni?
- come si impedisce che un utente legga i dati di un altro utente?
- come si fa a sapere se un blocco è libero o meno (quali blocchi sono liberi)?
File
In un OS le principali astrazioni sono :
- processi e thread
- spazio di indirizzamento
- file
Il OS può risolvere la complessità e rispondere alle domande precedentemente poste con l'astrazione dei file.
I file sono unità logica di informazioni create dai processi e gestite dal OS, e le informazioni salvate nel file sono persistenti e non dipendono dalla vita del processo che le ha create.
Quindi i file fungono da metodo di astrazione per salvare e leggere informazioni su memoria secondaria.
Il OS gestisce i file attraverso il file system, che si occupa dei seguenti aspetti dei file :
- denominazione
- struttura
- accesso
- protezione
- implementazione
Important
Quindi i file system sono un modo per organizzare e memorizzare (in modo persistente) le informazioni ( su hard disk e SSD ). I file system sono organizzati in file e tipicamente attraverso le directory. Tra gli esempi di file system abbiamo : FAT12/FAT16 (MS-DOS), NTFS (Win), ext4/ext3/ext2 (Linux), APFS (macOS).
Denominazione dei file
Una delle caratteristiche più importanti di ogni meccanismo di astrazione è il modo in cui vengono denominati i file/directory :
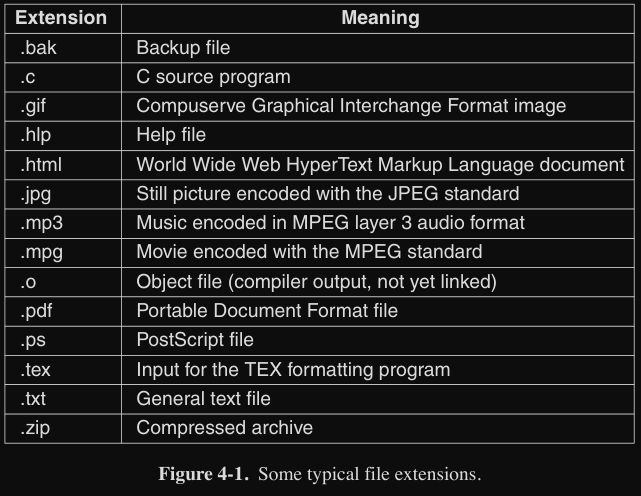
- rule names : variano da sistema a sistema, ma tutti considerano nomi validi sequenze fino a 8 caratteri, ad esclusione dei meta-caratteri usati dal file system :
~,",#,/,\,{,&,%… - lunghezza : molti file system supportano nomi di file fino al massimo di 255 caratteri
- sistemi come UNIX distinguono tra maiuscole e minuscole, mentre altri no come MS-DOS review
- estensione : molti sistemi operativi la adottano per specificare il tipo di file
- in UNIX se c’è o meno l’estensione fa niente, mentre su Windows ha un significato specifico (programmi specifici) (es. si apre Word se clicchiamo su un file
.docx)
- in UNIX se c’è o meno l’estensione fa niente, mentre su Windows ha un significato specifico (programmi specifici) (es. si apre Word se clicchiamo su un file
Nel MS-DOS i nomi dei file potevano arrivare fino al massimo a 8 caratteri e l'estensione opzionale era al massimo di 3 caratteri.
Struttura dei file
La struttura dei file è fondamentale nella progettazione dei OS, siccome definisce il modo in cui i file sono organizzati internamente e come i processi interagiscono con i dati contenuti nei file.
A seconda del OS, i file possono avere strutture diverse :
- sequenza di byte
- sequenza di record
- albero di record
Sequenza di byte - senza struttura
Il modello a sequenza di byte è il più diffuso e flessibile :
- il file è visto come una sequenza non strutturata di byte, quindi il OS non sa cosa sia contenuto nel file e tutto ciò che vede sono byte
- massima flessibilità : il significato e l’interpretazione di questi byte avvengono dal programma a livello utente (se si tratta di testo, immagini o un eseguibile)
- modello utilizzato da tutte le versioni di UNIX (Linux e OS X), MS-DOS e Windows

I file binari eseguibili anche se usano questo modello, richiedono comunque un formato specifico, per permettere al OS di eseguirli in modo corretto.
Sequenza di record
Il modello a struttura di record impone una struttura definita dal OS :
- un file è una sequenza di record di lunghezza fissa, e ogni record ha una sua struttura interna definita
- operazioni di lettura/scrittura avvengono tramite record
- la lettura restituisce un record
- la scrittura sovrascrive o aggiunge un record
I primi mainframe utilizzavano questo modello con record da 80 caratteri come le 80 colonne delle schede perforate. Mentre i OS attuali non utilizzano più questo modello.
Albero di record
Il modello ad albero di record è l’organizzazione più strutturata :
- il file è composto da un albero di record, che sono tutti della stessa lunghezza
- ogni record ha un campo chiave in una posizione precisa e l’albero è ordinato in base a questo campo chiave per velocizzare le ricerche
- modello utilizzato ancora su mainframe in alcune applicazioni commerciali
Tipi di file
Molti OS supportano diversi tipi di file, infatti UNIX e Windows supportano i file e le directory normali. UNIX ha inoltre dei file speciali a caratteri e a blocchi, mentre i file normali cono quelli contenenti i dati degli utenti. #review
Le directory sono file di sistema usati per mantenere la struttura del file system.
Per riconoscere il tipo di file in UNIX esiste il comando
fileche esegue dei test e supposizioni basate su pattern (euristiche) per determinare il tipo di file (txt, dir, eseguibile, etc.).
File normali
I file normali sono generalmente ASCII o binari :
- file ASCII :
- consistono in righe di testo, dove ogni riga termina con un carattere speciale ( carriage return e/o line feed )
- sono facili da visualizzare, stampare e modificare (editor di testo)
- file binari :
- sequenze di bit (non interpretati come caratteri)
- hanno una struttura nota solo ai programmi che li utilizzano
- NON possono essere stampati o modificati da editor di testo
- esempi : file eseguibili e archivi
:luc_gamepad_2: Bandit13
File eseguibile
Un esempio di formato di un file binario eseguibile (prime versioni di UNIX) è il seguente :
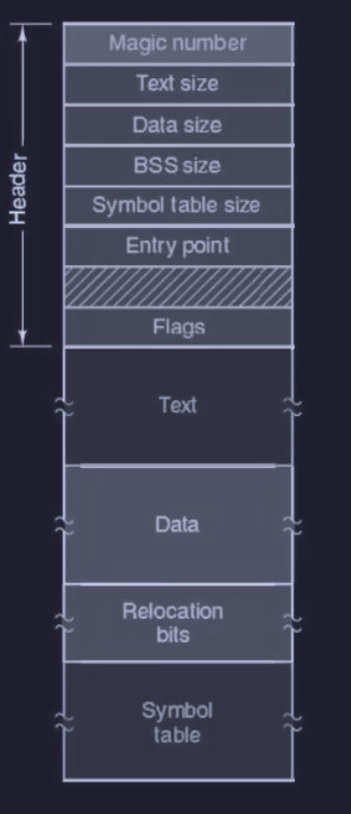
Infatti il formato è molto importante, siccome il OS esegue solo i file con un determinato formato :
- intestazione (header) :
- numero magico (identificatore del file binario come eseguibile)
- dimensione del testo, dati, BSS e tabella dei simboli
- entry point (indirizzo di inizio del programma)
- alcuni flag
- testo
- dati
- bit di ri-locazione
- tabella dei simboli (per debug)
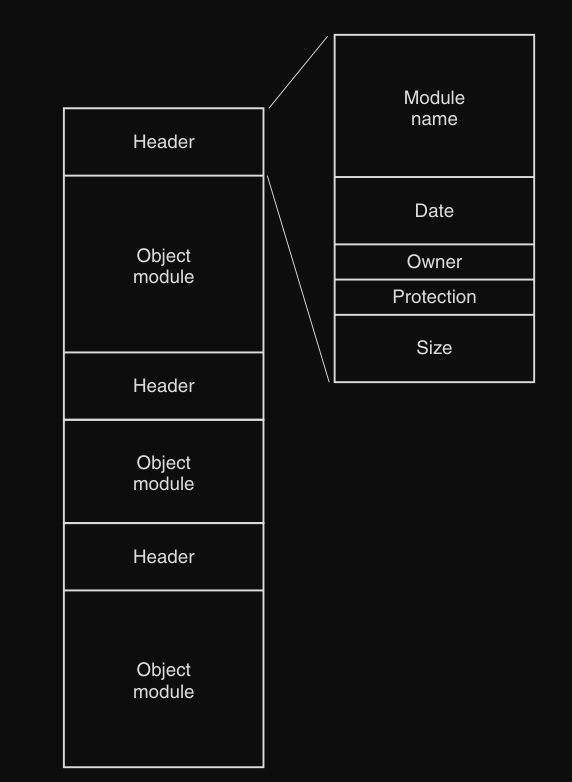
File archivio
Un secondo esempio di file binari è quello di un file archivio (sempre UNIX), che consiste in una collezione di procedure di libreria (moduli) compilati ma non collegati :
- ogni modulo ha un’intestazione (header) che contiene :
- nome del modulo
- data di creazione
- proprietario
- permessi (protection code)
- dimensione
- il resto è codice oggetto (binario) (object module) del modulo, che se vengono stampati sarebbero incomprensibili
Per esempio è possibile creare una propria libreria statica :
gcc -c modulo1.c modulo2.c # produce modulo1.o e modulo2.o
ar rcs libmialib.a modulo1.o modulo2.o # crea la libreria statica
gcc main.c -L. -lmialib -o programma # linka con la libreriaCi sono anche i file archivio generali che permettono di “archiviare” qualsiasi tipo di file (es. tar e zip) (vedremo dopo come si creano e gestiscono su Linux Archivi_linux).
Accesso ai file :luc_file_search:
Nei primi OS esisteva solo un tipo di accesso ai file ovvero l’accesso sequenziale, dove i byte del file vengono letti nell’ordine in cui sono scritti (cominciando dall’inizio del file). I file sequenziali erano buoni quando l’archiviazione era su nastro magnetico piuttosto che su disco.
Con l’introduzione dei dischi diventa possibile leggere i byte o i record dei file in qualsiasi ordine (possibile usare una chiave per accedere ai record indipendentemente dalla posizione), per questo viene introdotto anche l’accesso casuale (random access files) :
- cruciali per db che devono accedere rapidamente ai dati
- adottato sia in UNIX che Windows
Attributi dei file
Ogni file ha un nome, un contenuto (i dati) e alcuni attributi (o meta-dati), tra cui :
- timestamp di creazione
- dimensione
- protezione/accesso : utenti autorizzati ad accedere al file
- flag specifici (es. readonly, file nascosto, file di sistema, file di backup)
- tipo file
- gestione record (per file basati su record) : lunghezza del record, posizione e lunghezza della chiave
- …
L’elenco degli attributi dipende da sistema a sistema, di solito quelli più comuni sono i seguenti :


PS: Esiste un tool chiamato exiftool che dato un file da come output i suoi meta-dati (maggior parte dei meta-dati).
Operazioni sui file
Esistono varie operazioni disponibili nei OS e le system call più comuni per farlo sono :
- create : crea un file vuoto con alcuni attributi imposti
- delete : rimuove il file e libera spazio sul disco
- open : prima di poter utilizzare (leggere o scrivere) un file, un processo deve aprirlo
- questa operazione permette al OS di portare in memoria principale gli attributi del file e l’elenco degli indirizzi sul disco (informazioni su dove sono memorizzati i dati), garantendo così un accesso rapido
- close : chiude il file al termine di tutti gli accessi
- libera la memoria da tutti i riferimenti al file perché non verrà più utilizzato
- siccome l’input e output su disco avviene a blocchi, la chiusura del file detta la scrittura dell’ultimo blocco del file sul disco
- read : legge i dati dal file dalla posizione corrente (o specificata)
- occorre specificare anche
- il numero di dati da leggere
- buffer di memoria dove inserire quello che legge
- occorre specificare anche
- write : scrive dati nel file, dalla posizione corrente
- append : scrive dati alla fine del file
- seek : cambia posizione corrente
- stat (get attributes) : usato in UNIX per leggere gli attributi del file
- utilizzato per esempio da
makeper la gestione dei progetti software
- utilizzato per esempio da
- rename
Directory
I file system organizzano i file in “contenitori” chiamati directory o cartelle.
Per gestire la crescente quantità di file per utente, sono stati sviluppati diversi schemi organizzativi :
- sistema a directory a livello singolo : forma più semplice dove esiste solo una root directory che contiene tutti i file (file semplici da trovare)
- applicati oggi in :
- dispositivi embedded : fotocamere digitali o riproduttori MP3
- tecnologie RFID : chip di RFID, carte di credito o tessere di trasporto
- applicati oggi in :
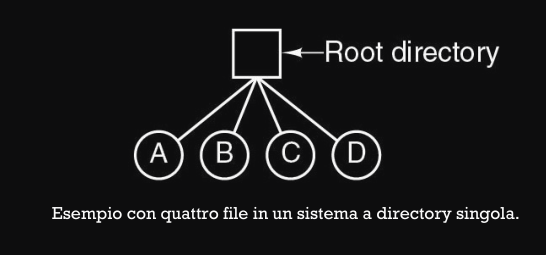
- sistema a directory gerarchico (ad albero) : metodo utilizzato da quasi tutti i sistemi operativi (UNIX e Windows), dove si adotta una definizione ricorsiva in cui ogni directory può contenere file e altre sotto-directory
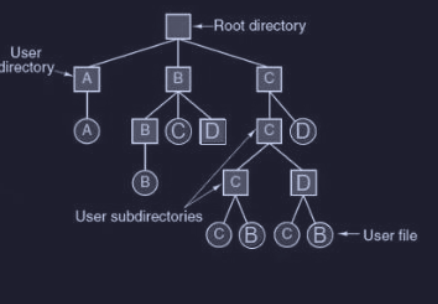
Path name
In un sistema di directory gerarchico, sono utilizzati due metodi per identificare in modo univoco un file o una directory :
- path name assoluto : nome del percorso completo che identifica un oggetto a partire dalla directory root. Il percorso è composto da una sequenza ordinata di directory separate da un carattere speciale come
/in UNIX,\in Win e>in MULTICS, inoltre riusciamo a capire che si tratta di un percorso assoluto se il primo carattere è il carattere speciale separatore (es./home/ubuntu/file1) - path name relativo : il file o la directory viene individuato da un punto di riferimento di partenza relativo
Nella maggior parte dei OS, in ogni directory sono contenuti (sempre) due file speciali :
.: rappresenta la directory corrente..: rappresenta la directory precedente (genitore)
Operazioni sulle directory
In UNIX abbiamo :
mkdir()/ create : crea una directory vuota, ma con dentro.e..rmdir()/ delete : rimozione solo se la directory è vuotaopendir(): carica i riferimenti di localizzazione delle directory in memoria (come quando facciamoopen()per i file)readdir(): legge una voce alla volta all’interno di una directory (già aperta)closedir(): chiude la directory al termine della lettura e libera il corrispondente spazio in memoriarename()link(): crea un link hard tra un file esistente e il path name indicato- il link hard è una tecnica che incrementa un contatore nel
i-nodedel file per tenere traccia del numero di directory che contengono il file
- il link hard è una tecnica che incrementa un contatore nel
unlink(): rimuove il collegamento alla directory, ricordiamo che se il file è unico viene eliminato dal file system, altrimenti viene rimosso solo il link