
La gestione della memoria è un concetto fondamentale nei OS, poiché la memoria principale (RAM) è una risorsa da gestire.
La parte del OS che gestisce (in parte) la gerarchia della memoria viene chiamato gestore della memoria. Il suo compito è quello di tenere traccia delle parti della memoria che sono utilizzate, allocare memoria per i processi e deallocare quando serve.
Nessuna astrazione di memoria
In questo modello i processi vedono direttamente la memoria fisica così come è costituita (sequenza di indirizzi da 0 a un massimo).
Per esempio se veniva eseguito :
MOV REGISTER1, 1000veniva veramente spostato il contenuto della locazione di memoria fisica 1000 nel registro.
L’organizzazione della memoria fisica può essere organizzata in 3 modi:
- OS in fondo alla RAM
- OS in testa alla ROM (es. sistemi embedded)
- OS distribuito (es. PC con MS-DOS):
- OS in fondo alla RAM
- driver in testa alla ROM (qui BIOS - Basic Input Output System)
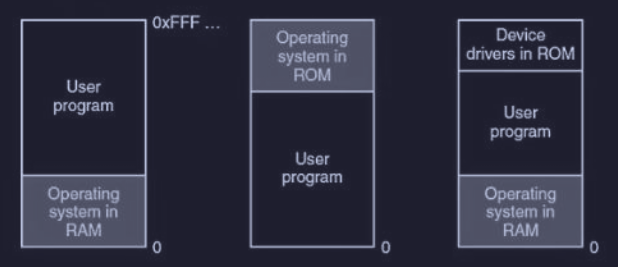
I modelli in cui il OS risiede in parte o totalmente nella RAM (come primo e terzo), presentano lo svantaggio critico che un errore nel programma utente può eliminare o sovrascrivere l'OS, causando un caos!!
La mancanza di una astrazione memoria è ancora comune nei dispositivi come la radio, lavatrici e forni a microonde, dove il software indirizza la memoria in modo assoluto e funziona solo perché i programmi che girano si conoscono a priori (un utente non può far girare Minecraft su un tostapane).
Esecuzione di più programmi
Per consentire l’esecuzione di più programmi, anche nei sistemi privi di astrazione, è possibile simulare di avere più programmi contemporaneamente.
Una strategia sviluppata per gestire il sovraccarico della memoria (sopratutto quando la RAM non è sufficiente per i tutti i processi) è lo swapping (vedremo meglio di seguito).
Problema ri-locazione
Il problema è che i programmi utilizzano indirizzi assoluti di memoria fisica portando a conflitti durante l’esecuzione.
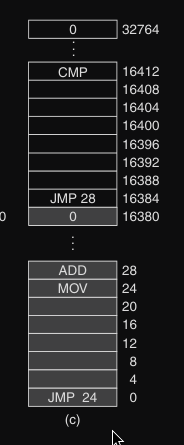
Consideriamo per esempio :
- primo programma da 16 KB che inizia con l’istruzione
JMP 24 - secondo programma da 16 KB che ha l’istruzione
JMP 28

quando entrambi verranno caricati in memoria consecutivamente, avremo che quando il secondo programma eseguirà JMP 28 finirà nel primo programma.
Astrazione della memoria
Esporre la memoria fisica direttamente ai processi presenta 2 problemi principali:
- protezione: se i programmi utente possono indirizzare ogni byte, possono facilmente sovrascrivere l’OS
- ri-locazione/organizzazione (posizionamento dei programmi): è complicato mantenere un’organizzazione rigida della memoria che permetta a più programmi di girare contemporaneamente in memoria
Quindi per poter consentire a più programmi di risiedere in memoria senza interferire l’uno con l’altro, devono essere risolti questi due problemi citati.
Soluzione con gli spazi degli indirizzi - spazio degli indirizzi
Una soluzione è quella di inventare una nuova astrazione della memoria, ovvero lo spazio di indirizzi.
Uno spazio di indirizzi è l’insieme di indirizzi che un processo può utilizzare per accedere alla memoria.
Quindi ogni processo ha il suo proprio spazio di indirizzamento e questo rappresenta una forma di memoria astratta.
Registri base e limite
La soluzione classica dello spazio degli indirizzi, prevede che ogni CPU sia dotata di 2 registri hardware speciali:
- registro base : contiene l’indirizzo fisico di memoria dove inizia il programma
- registro limite : contiene la lunghezza del programma
Quando un processo accede alla memoria :
- la CPU aggiunge automaticamente il valore del registro base all’indirizzo richiesto
- verifica che l’indirizzo calcolato non supera il valore del registro limite
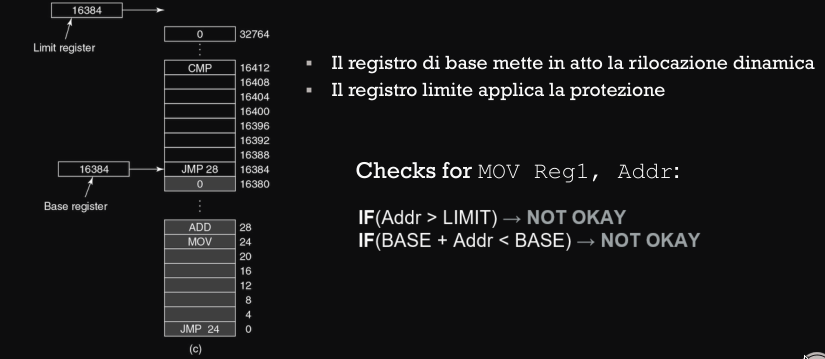
review Inoltre in molte implementazioni, i 2 registri sono modificabili solo dal OS.
Lo svantaggio di questo meccanismo è che ad ogni accesso alla memoria viene fatta eseguire un'addizione e un confronto, ma le addizioni sono lente a causa della propagazione dei riporti (a meno che non si utilizzano circuiti sommatori speciali).
Vedremo una soluzione migliore con il paging + MMU.
Gestione del sovraccarico di memoria - swapping & allocazione
Se la RAM del computer è abbastanza grande da contenere tutti i processi, gli approcci descritti fino ad ora sono validi, altrimenti se la RAM non è sufficiente, si ricorre a due approcci generali:
- swapping
- memoria virtuale: consente ai programmi di essere eseguiti anche se sono parzialmente in memoria principale (vedremo molto bene con Paging)
Swapping
Lo swapping consiste nel spostare temporaneamente i processi non in esecuzione sul disco, in questo modo i processi “inattivi” non occupano la memoria principale quando non sono in esecuzione, ma sono sul disco.
Vediamo il funzionamento con un esempio:
- inizialmente il processo A è in memoria

- vengono creati (o caricati) i processi B e C
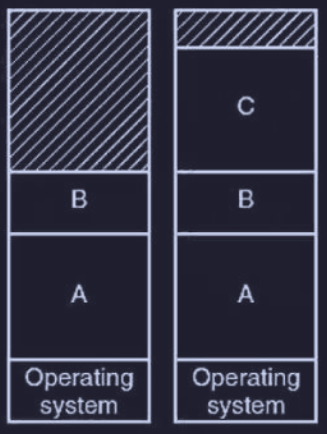
- A è terminato e viene salvato su disco

- quando A è salvato su disco, viene creato (o caricato) il processo D

- quando D entra in memoria, B viene salvato su disco

- A viene ricaricato in memoria

Lo swapping porta alla creazione di buchi nella memoria (frammentazione).
È possibile combinare tutti questi buchi in un unico grande buco (spazio libero), spostando tutti i processi verso il basso (o l’alto) della memoria. Questa tecnica è raramente utilizzata perché richiede una grande quantità di tempo CPU.
Allocazione dinamica
Normalmente i processi crescono di dimensione, attraverso l’allocazione dinamica della memoria heap o dello stack. Quindi è considerata buona norma riservare uno spazio aggiuntivo (area per la crescita) per il processo quando viene caricato per evitare overhead associato con lo spostare il processo, siccome non c’è più spazio e il processo vuole crescere.
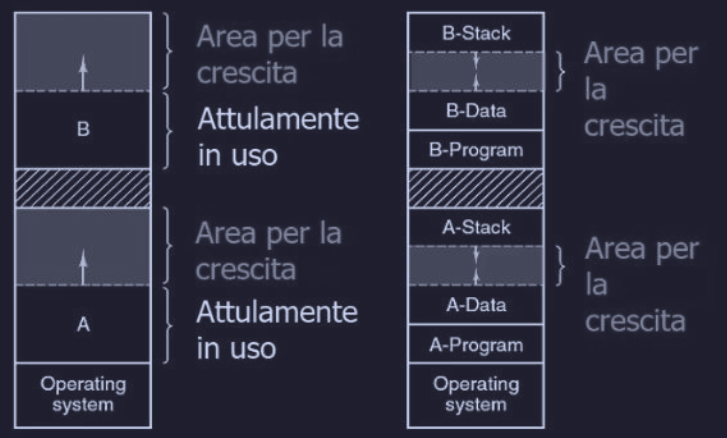
Se non ha più spazio infatti il processo può essere :
- ucciso
- swappato (swap) finché un nuovo “buco” sufficiente potrà essere creato.
Gestione della memoria libera :luc_feather:
La gestione della memoria libera è un compito essenziale del OS quando la memoria viene allocata dinamicamente (come quando si utilizza lo swapping). Infatti per tenere traccia del utilizzo della memoria e degli spazi disponibili (i buchi) esistono due approcci principali:
- bitmap
- liste collegate in allocazione
Questo tracciamento non riguarda solo la memoria, ma anche le risorse come i file system.
Gestione della memoria con bitmap :luc_map:
Con una bitmap (mappa di bit) la memoria fisica viene concettualmente divisa in unità di allocazione (o blocchi), dove la dimensione di un’unità di allocazione può variare da poche word a diversi KB.
Quindi una bitmap tiene traccia di ogni unità:
- se il bit è 0 l’unità è libera
- se il bit è 1 l’unità è occupata
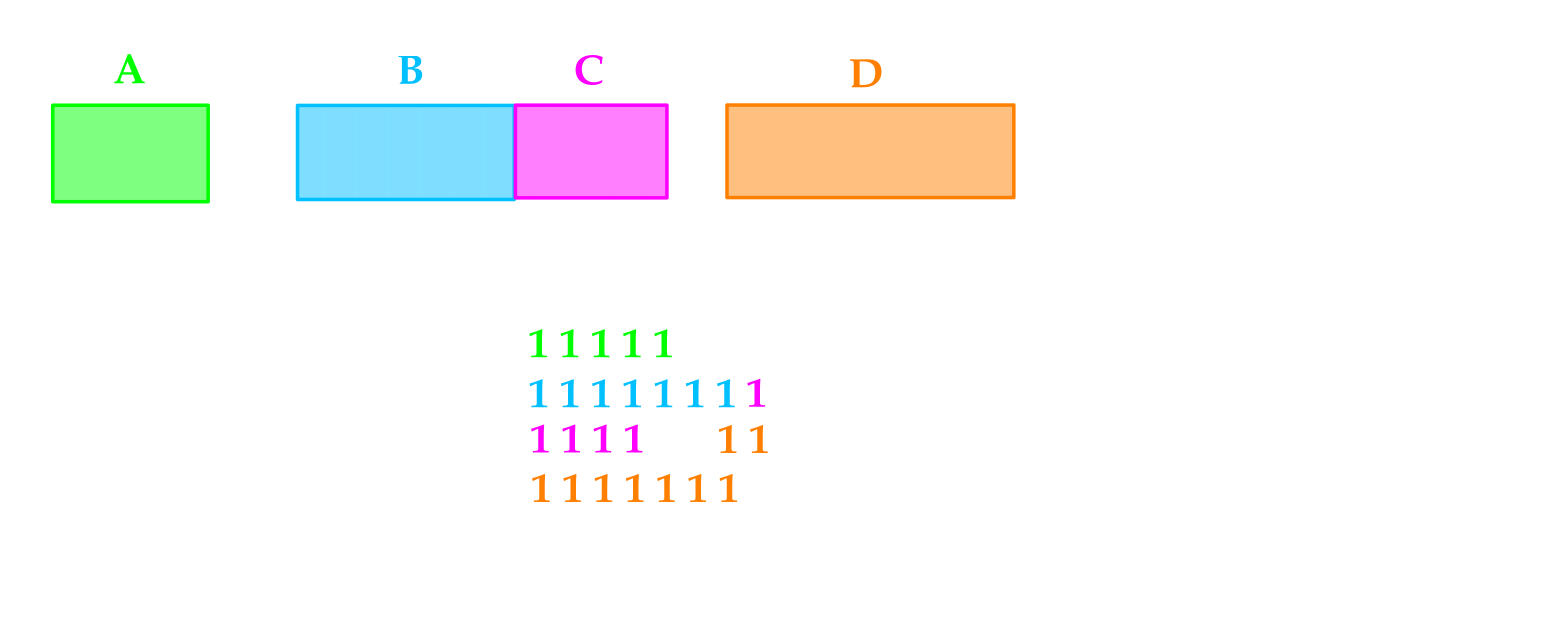
Inoltre la dimensione dell’unità di allocazione gioca un ruolo chiave, siccome influenza la dimensione della bitmap.
Il problema vero e proprio è quando dobbiamo caricare in memoria un processo di unità, infatti il gestore deve cercare nella bitmap bit liberi consecutivi, ma ricordiamo che la ricerca sequenziale è un'operazione lenta.
Gestione della memoria con liste collegate :luc_link_2:
Un altro modo per gestire la memoria è attraverso una lista collegata (linked list) che memorizza le posizioni dei segmenti occupati dai processi (P) e quelle dei segmenti liberi (H per Holes - buchi).
Ogni elemento della lista contiene (in ordine):
- buco o processo (H/P)
- indirizzo di inizio segmento
- lunghezza del segmento
- puntatore all’elemento successivo
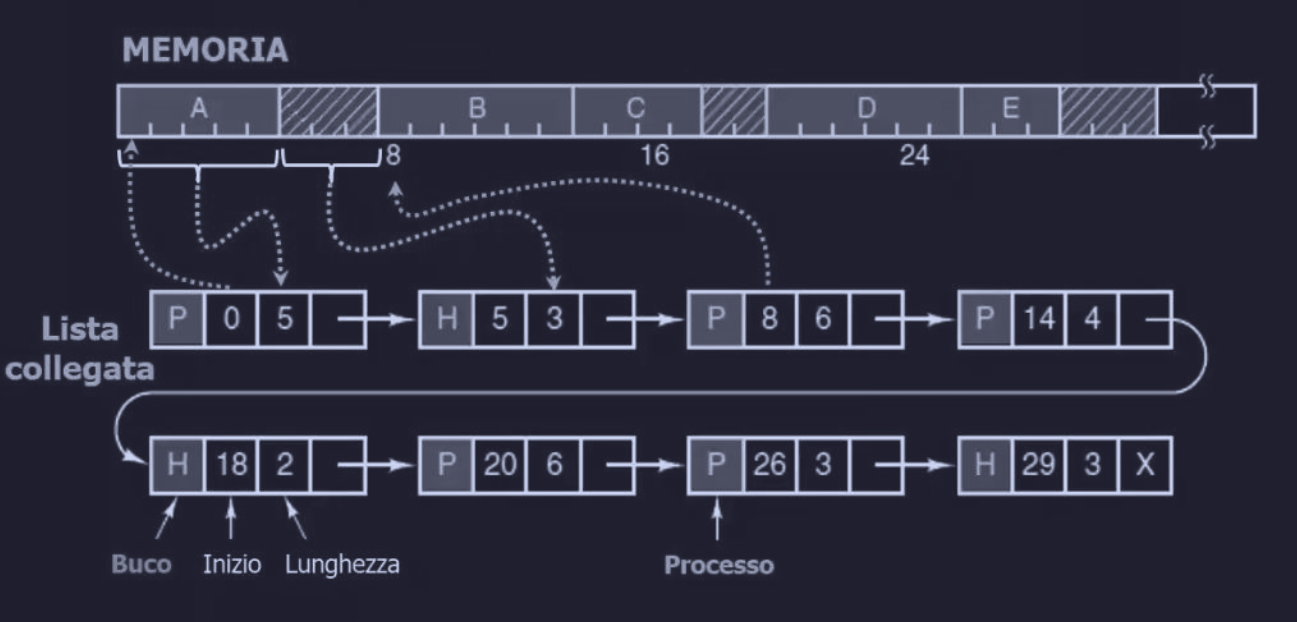
In questo esempio (figura sopra) la lista collegata è ordinata secondo l’indirizzo di inizio di ogni segmento.
Il vantaggio principale è che quando un processo termina o viene fatto lo swap su disco, aggiornare la lista risulta facile.
Infatti quando un processo termina, il segmento occupato (P) dal processo viene “convertito” in un buco (H). Inoltre se il segmento adiacente è anche lui un buco (H), le entrate possono essere fuse, per formare un unico grande buco, accorciando la lista (come mostrato nella figura qui sotto) :
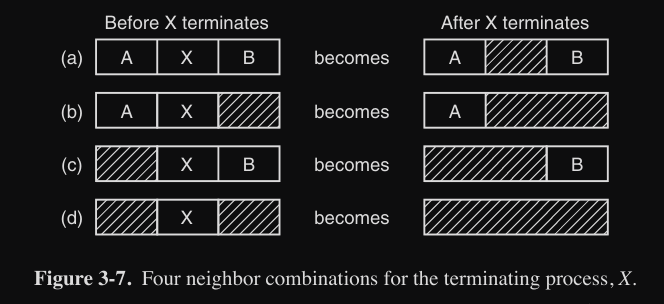
Siccome per conoscere chi c’è prima di X bisogna riscorrere la lista, è più conveniente utilizzare una double-linked list, dove ogni nodo ha due puntatori : next (nodo successivo) e previous (nodo precedente). In questo modo quando il processo X termina il OS guarda direttamente i due puntatori, next e previous, per fare l’unione in caso di presenza di buchi.
Algoritmi di allocazione della memoria
Quando viene creato un nuovo processo o viene caricato dal disco, il gestore della memoria utilizza diversi algoritmi per trovargli una posizione adeguata nello spazio libero disponibile (i buchi H) (assumendo che si conosca la quantità di memoria necessaria da allocare al processo) :
- first fit
- next fit
- best fit
- worst fit
- quick fit
First fit
È l’algoritmo più semplice, dove il gestore di memoria scorre la lista finché non becca uno spazio libero abbastanza grande da contenere il processo :
- se lo spazio libero è maggiore dello spazio richiesto, viene suddiviso in due parti :
- una per il processo
- una per la memoria non utilizzata (buco rimanente)
- altrimenti viene utilizzato l’intero spazio
Il first fit è un algoritmo veloce perché cerca di non scorrere tutta la lista, fermandosi al primo spazio valido.
Next fit
Una piccola variante del first fit è il next fit, che funziona allo stesso modo, con l’unica differenza che tiene traccia della posizione dove ha trovato l'ultimo spazio libero. In questo modo la prossima volta che verrà “chiamato” per cercare uno spazio libero, inizierà a cercare dalla posizione salvata, anziché ricominciare dall’inizio.
Le simulazioni indicano che il next fit da performance leggermente peggiori del first fit.
Best fit
Il best fit scorre tutta la lista collegata dei segmenti in memoria, alla ricerca del buco che si adatta meglio alla dimensione richiesta del processo.
Svantaggi :
- lentezza : deve scorrere tutta la lista, per trovare il “miglior” buco
- frammentazione : tende a riempire la memoria con molti spazi vuoti piccoli e inutilizzabili, quindi spreca più memoria del first e next fit (first fit genera buchi più grandi)
Worst fit
L’algoritmo del worst fit opera con una logica inversa rispetto al best fit, infatti l’algoritmo cerca sempre il buco più grande disponibile che possa contenere il processo richiesto.
Le simulazioni mostrano che anche il worst fit non è un buon algoritmo di allocazione di memoria, siccome lascia dei piccoli frammenti vuoti inutilizzabili e spreca memoria.
Quick fit
L’algoritmo quick fit è un metodo specializzato per rendere la ricerca dello spazio libero estremamente rapida.
Questo algoritmo mantiene elenchi separati per alcune delle dimensioni di buchi più richieste.
Per esempio possiamo avere :
- una lista (elenco) per i buchi da 4 KB
- una lista (elenco) per i buchi da 8 KB
- e cosi via
Con questo approccio trovare uno spazio libero della dimensione desiderate è molto veloce.
review Lo svantaggio è che quando un processo termina o viene rimosso tramite swap su disco, l’operazione di unione degli spazi vuoti adiacenti diventa un processo molto dispendioso.
Buddy Memory allocation (Linux)
Linux supporta vari meccanismi per l’allocazione della memoria. Quello principale è una allocazione delle pagine basato sull’algoritmo di buddy memory allocation.
Il funzionamento :
- la memoria inizialmente è vista come un singolo pezzo contiguo di pagine (potenza di 2)
- ad ogni richiesta, la parte più bassa e disponibile della memoria viene divisa secondo una potenza di 2
- blocchi di memoria adiacenti vengono uniti quando rilasciati (coalescenza)
Consideriamo un esempio dove inizialmente abbiamo la memoria vista come un singolo pezzo da 64 pagine contigue (a) :
- arriva una richiesta per 8 pagine (arrotondata a potenza di 2)
- la memoria da 64 viene divisa in 2 (b)
- siccome i pezzi sono ancora troppo grandi (32), si divide l’ultimo pezzo (c) e poi ancora (d)
- ora abbiamo un pezzo da 8 che possiamo allocare per il chiamante (grigio scuro in (d))
- arriva poi un altra richiesta da 8, che possiamo subito soddisfare (grigio chiaro in (e))
- arriva una richiesta da 4 pagine, allora dividiamo in 2 il pezzo più in basso (e piccolo) e disponibile (pezzo da 16 in (e)) (f)
- poi dividiamo ancora e viene assegnata la metà (grigio scuro in (g))
- un pezzo da 8 viene rilasciato (h)
- anche un altro pezzo da 8 viene rilasciato, in questo caso siccome abbiamo due pezzi da 8 adiacenti liberi e che provengono dallo stesso pezzo da 16 pagine, vengono uniti per riottenere il pezzo da 16 pagine (i)

Slab allocator
Il buddy algorithm gestisce la memoria in blocchi di 2, questo però porta ad una frammentazione interna. Supponiamo per esempio di aver bisogno di un blocco da 65 pagine, il buddy algorithm è “costretto” ad allocare un blocco da 128 pagine (potenza di 2 più vicina). Quindi avremo 63 pagine di memoria sprecate.
Il kernel Linux crea e distrugge strutture di dati di piccole dimensioni (es. descrittori di un processo task_struct, inode etc.). Quindi affidare queste piccole allocazioni al buddy algorithm non è una buona idea.
Per questo motivo la Sun ha introdotto lo slab allocator, che si posiziona ad un livello superiore rispetto al buddy, e agisce come “cliente” del buddy, richiedendo blocchi di memoria (slab) e suddividendoli a sua volta (slot).
L’architettura dello slab allocator è cosi composta :
- slab : blocco di memoria (presa dal buddy) contigua che viene suddiviso in slot
- slot : locazioni fisiche dove risiederà l’oggetto (es. il
task_struct) - cache : contiene uno o più slab che contengono oggetti dello stesso tipo, quindi avremo una cache per i
task_struct, una per i file descriptor etc.- questo è fondamentale siccome il kernel quando ha finito con un processo per esempio, non rilascia la sua memoria, ma considera i suoi dati non validi e libera quello slot specifico nello slab dei processi. In questo modo si evita di fare tutto il giro di allocazione memoria etc (overhead di inizializzazione).
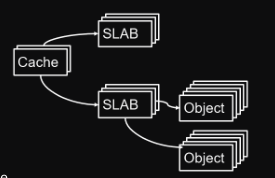
Struttura interna di uno slab
Per ottimizzare le ricerca di uno slot libero, il sistema tiene gli slab di una cache in tre liste basate su loro stato :
- partial : slab che contengono sia oggetti allocati che slot liberi
- empty : slab con tutti slot liberi
- full : slab con tutti slot occupati (oggetti allocati)
Per esempio uno slab potrebbe essere così composto, per la ricerca ottimizzazata () di slot nello slab :
- slab descriptor (capo che ti dice dove trovare posti liberi) :
- puntatore
free: indica il primo slot libero - array
bufctl: array di indici dei prossimi slot liberi, nella posizioneici sarà il puntatore al prossimo slot libero dopoi(es. 1° slot libero → 1, 2° slot libero →bufctl[<1° slot libero>]=bufctl[1]=5)
- puntatore
- slot per gli oggetti
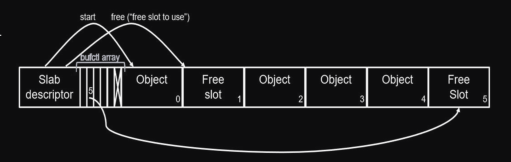
PS: ripasso Slab_allocator