
La memoria virtuale, nella sua forma più semplice è monodimensionale, con indirizzi virtuali che partono da 0 fino ad un massimo in una singola sequenza lineare.
Ma avere più spazi di indirizzi virtuali può essere utile, per esempio un compilatore utilizza molte tabelle distinte (testo sorgente, la tabella dei simboli, le costanti etc.) e queste tabelle hanno spesso comportamenti di crescita diversi e se fossero nello stesso spazio lineare, rischierebbero di scontrarsi.
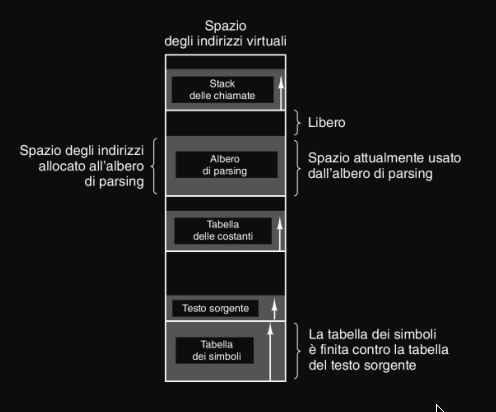
Quindi la soluzione è fornire più spazi di indirizzi indipendenti, chiamanti segmenti.
Ogni segmento consiste in una sequenza lineare di indirizzi, da 0 ad un massimo. Inoltre i segmenti possono essere di lunghezza diversa, siccome possono modificarsi durante l’esecuzione.

In questo modello di memoria per specificare un indirizzo sono necessari due elementi :
- numero del segmento
- indirizzo all’interno del segmento (
offset)
Vantaggi della segmentazione
- gestione dinamica delle strutture dati : siccome ogni segmento è indipendente, può crescere o ridursi senza problemi
- lo stack può espandersi o contrarsi senza influire le altre tabelle
- semplificazione del linking : se si assegna un segmento separato ad ogni procedura, il linking delle procedure diventa più semplice
- in caso di modifica, non è necessario aggiornare gli indirizzi di altre procedure non correlate
- condivisione : la segmentazione semplifica la condivisione di codice o dati tra processi (es. per le librerie condivise è molto utile)
- protezione logica : i segmenti possono avere diverse protezioni, come solo esecuzione e non scrittura
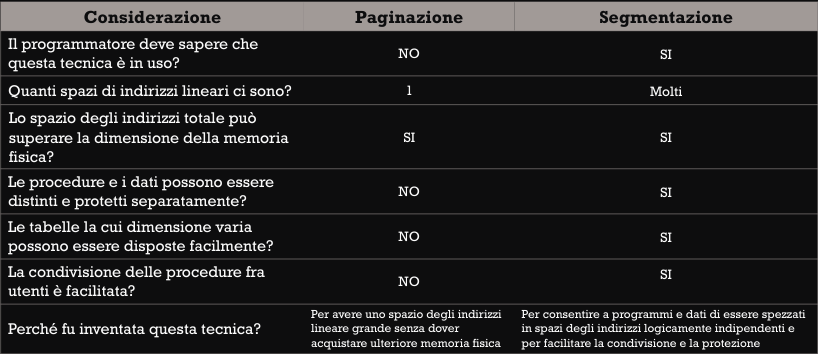
Paginazione vs segmentazione

Problema nella realizzazione della segmentazione
L’implementazione della segmentazione è difficile sopratutto per il fatto che i segmenti hanno lunghezze variabili (al contrario delle pagine che hanno lunghezza fissa).
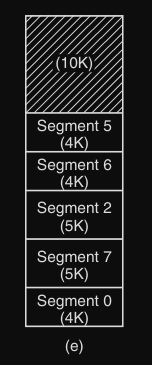
Dopo che il sistema è stato in esecuzione per un po e i segmenti vengono caricati e scaricati, la memoria fisica si divide in segmenti occupati e “buchi” di memoria libera di dimensioni irregolari. Questo spreco di memoria è noto come frammentazione esterna (come nella figura qua sotto).
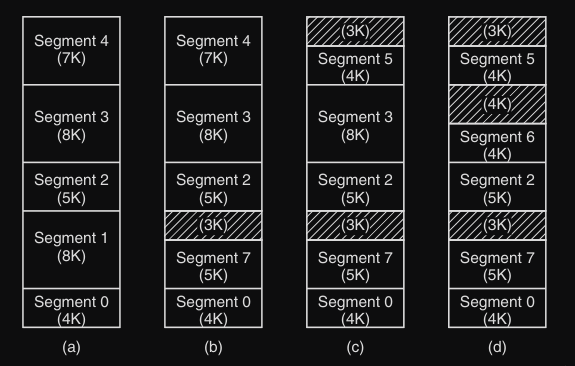
Una soluzione sarebbe la compattazione, ovvero lo spostamenti di tutti i segmenti per unire i buchi.
Segmentazione con paginazione (MULTICS)
A causa dei problemi di frammentazione della segmentazione che abbiamo visto prima, i sistemi come MULTICS e Intel x86 hanno combinato la segmentazione e l’efficienza fisica della paginazione.
L’idea di base è quella che siccome i segmenti sono grandi, è inefficiente caricarli interamente in memoria, quindi la soluzione è “paginare” i segmenti, in modo che solo le pagine necessarie del segmento siano nella memoria fisica.
Ogni programma aveva una tabella dei segmenti, che conteneva un descrittore per ogni segmento, a sua volta se un segmento era in memoria, il suo descrittore puntava alla sua tabella delle pagine.
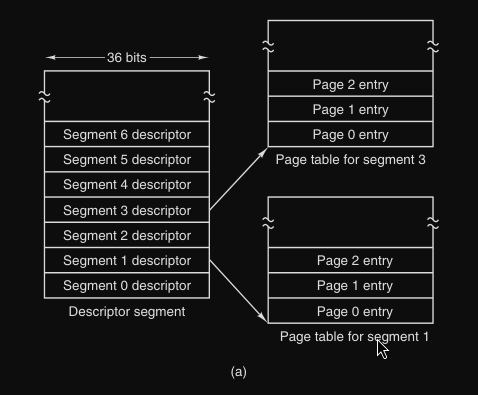
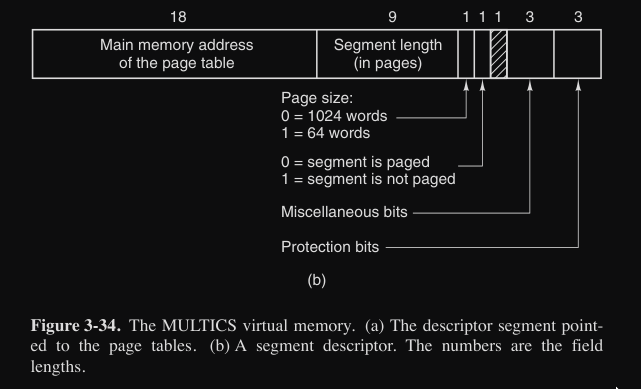
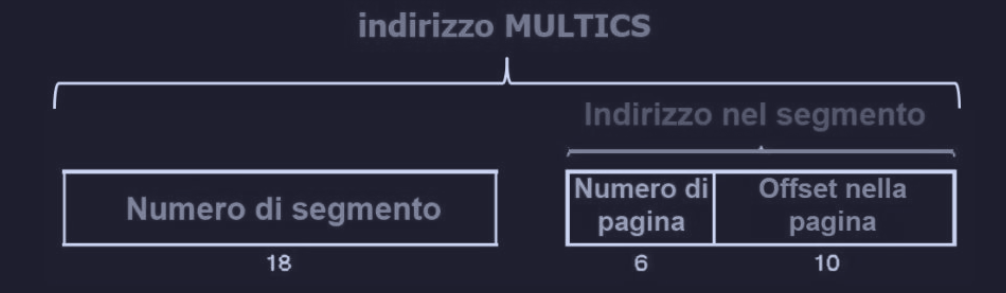
Nel MULTICS l’indirizzo consiste in due parti :
- numero del segmento
- indirizzo del segmento, che a sua volta aveva due parti :
- numero pagina
- offset all’interno della pagina
Processo di traduzione
Per ogni riferimento alla memoria, il processo di traduzione prevedeva :
- numero del segmento viene usato per trovare il descrittore del segmento
- tabella delle pagine del segmento è in memoria?
- si lo localizza
- no viene generato un errore di segmento
- viene esaminata la riga della tabella delle pagine del segmento, è in memoria?
- si viene estratto l’indirizzo della pagina in memoria
- no viene generato un page fault
- una volta che si ha la pagina, si aggiunge l’offset all’indirizzo di inizio del frame per ottenere l'indirizzo fisico
- si legge o scrive la pagina
review
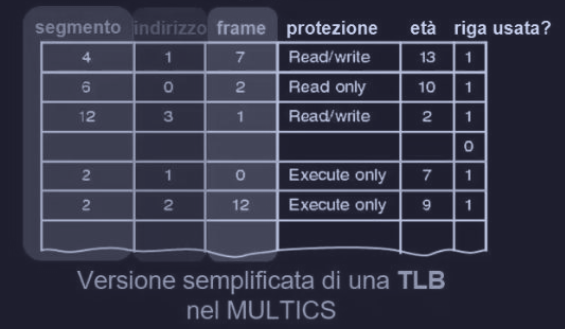
Ripetere tutti questi passaggi ad ogni riferimento di memoria, può rallentare il sistema, quindi il MULTICS utilizza una TLB (da 16 word) che mappa le coppie (<segmento>,<indirizzo>) = <frame> usate di recente, in modo da trovare direttamente il frame, senza andare a guardare nel descrittore del segmento e poi nella tabella delle pagine.
Segmentazione con paginazione in Intel x86

Il comando “free”
In linux esiste il comando free per poter monitorare l’utilizzo della memoria e dello swap.
L’output del comando è cosi costituito :
total: quantità totale di memoria fisica disponibileusedfreeshared: memoria condivisa (presente solo per compatibilità)buff/cache: memoria utilizzata per buffer/cache/slab (recuperabile se necessario)available: stima memoria disponibile per nuovi programmi (+ buffer/cache)
Tra le opzioni abbiamo :
-h: formato leggibile (MB o GB)-b,--kilo,--mega,--giga: specifica unità di misura-t: per avere un totale delle colonne citate sopra tra memoria e swap (memoria+swap)-s: watch continuo (megliowatch -n <sec> "free <opzioni>")