
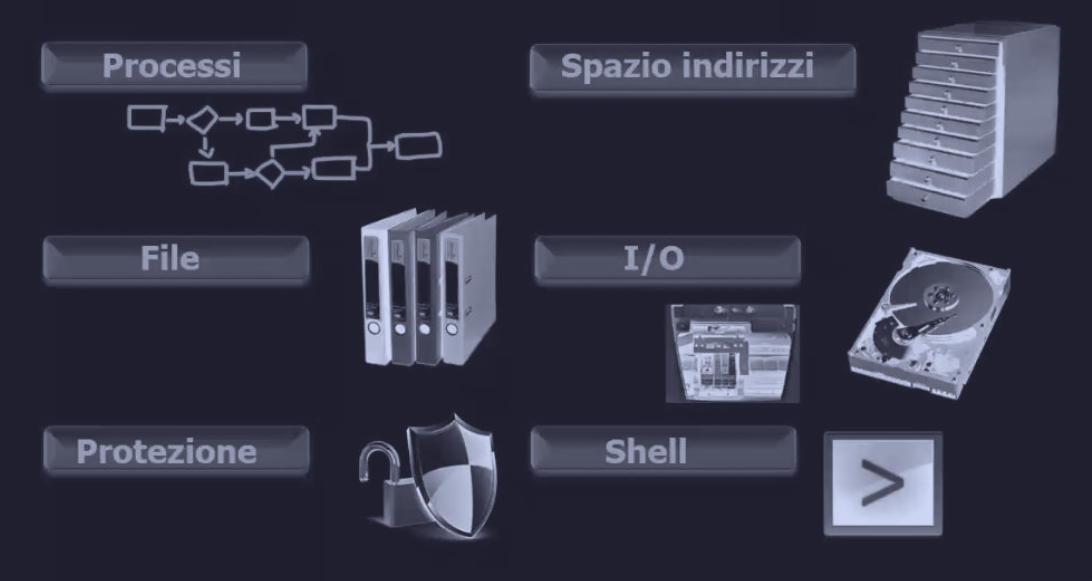
Il ruolo del sistema operativo (OS) è quello di agire come:
- macchina estesa : fornendo astrazioni semplici e pulite dell’hardware complesso
- gestore delle risorse
Le principali astrazioni e concetti base di un OS sono:
- processi : programma in esecuzione
- spazio di indirizzi (address space) : astrazione di memoria che il OS presenta ad un processo Memoria
- file : raggruppare i dati, nascondendo le specificità dell’hardware di memorizzazione (dischi, nastri, etc)
- I/O : fornire una interfaccia semplice e facile da usare tra i programmi utente e i dispositivi
- protezione : sicurezza dei dati e delle risorse del sistema, i file devono essere accessibili solo agli utenti autorizzati
- shell : interprete dei comandi e interfaccia utente che riceve i comandi e non fa parte del OS
Processi
Il processo è l'esecuzione di un programma, ed ad ogni processo è associato :
- spazio degli indirizzi, dove vengono memorizzati :
- il programma eseguibile (codice)
- i dati
- stack
- insieme di risorse :
- registri della CPU (Program Counter e Stack Pointer)
- file aperti
- elenco di processi correlati (padre/figlio)
- allarmi in sospeso
- entry nella tabella dei processi (Process Control Block - PCB) : questa tabella è utilizzata dal OS per memorizzare le informazioni essenziali dei processi per salvare e ripristinare il loro stato in caso di cambio di contesto
Gerarchia dei processi
I processi (sopratutto in UNIX) sono organizzati in modo gerarchico. Infatti l’utente che ha avviato un processo ne è proprietario (User IDentifier - UID) e un processo a sua volta può creare processi figli (con stesso UID) in modo ricorsivo creando una gerarchia.
Comunicazione tra processi - IPC
I processi possono cooperare tra di loro per raggiungere un obiettivo comune e quindi hanno bisogno di comunicare tra di loro (per sincronizzarsi) (InterProcess Communication - IPC), quindi c’è la necessità di gestire 3 problematiche :
- passaggio di informazioni tra processi (
pipein Unix) - mutua esclusione : assicurare che più processi non interferiscano tra di loro (es. accedere ad una risorsa condivisa)
- sincronizzazione : garantire la corretta sequenza di esecuzione quando ci sono dipendenze tra processi
Layout processi UNIX
I processi in UNIX hanno la loro divisione in tre segmenti :
- text (codice programma)
- data (es. variabili)
- stack
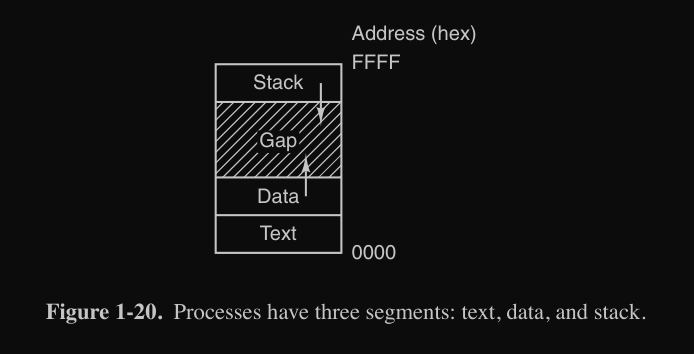
tra lo stack e data c’è un gap di uno spazio di indirizzi non utilizzato, serve per la crescita del segmento data e stack.
Spazio degli indirizzi
Ogni computer ha una memoria principale per contenere i programmi in esecuzione. Nei primi OS solo un programma poteva risiedere in memoria alla volta. Mentre con la multiprogrammazione, gli OS moderni consentono a più programmi di risiedere in memoria contemporaneamente.
Per evitare che questi programmi interferiscano tra di loro è necessario un meccanismo di protezione (implementato nell’hardware ma controllato dal OS).
Lo spazio di indirizzi rappresenta l’astrazione della memoria, infatti la virtualizzazione della memoria permette ad un programma di fare riferimento ad un set privato di indirizzi ( da 0 ad un massimo). Quindi un processo vede uno spazio di indirizzi univoco (virtuale) anche se parte dei dati sono in memoria principale e altri nel disco.
Il sistema operativo quindi tramite la virtualizzazione funge da "maggiordomo" che si assicura che, quando un processo richiede un dato dal suo spazio di indirizzi, questo dato sia caricato nella RAM (se non c’è già).
File
Il file è un modello astratto per raggruppare un insieme di dati, nascondendo le peculiarità dell’hardware che li memorizza (dove e come i dati sono memorizzati).
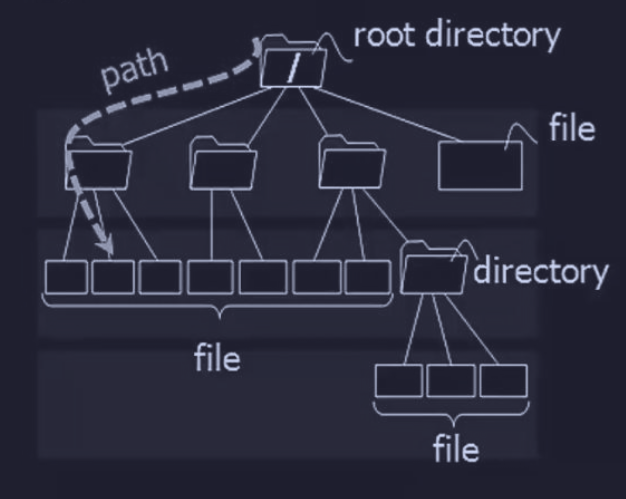
Il file system è l’ambiente che gestisce i file ed è organizzato in modo gerarchico, dove ciascun nodo intermedio è un contenitore di altri file (o directory) in modo ricorsivo.
Per arrivare ad un file si deve attraversare il path name del file, ovvero il percorso assoluto, partendo dalla root directory.
Prima che un file possa essere letto/scritto è necessario aprirlo, una volta aperto verrà restituito un numero intero associato al file chiamato file descriptor (descrittore del file).
Mounted file system
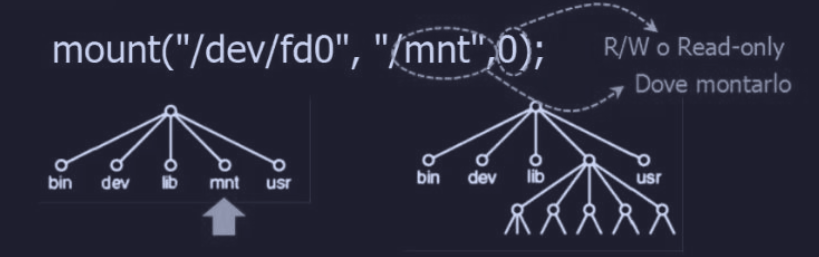
Un concetto importante in UNIX sono i file system “montati”. Infatti molti sistemi hanno porte USB e/o possono essere inseriti CD-ROM, DVD etc.
Quando questi media rimovibili sono inseriti nel sistema, non sono subito accessibili (in UNIX), infatti vanno “montati” nel root file system.
Consideriamo per esempio che abbiamo un USB drive, la situazione iniziale sarà :
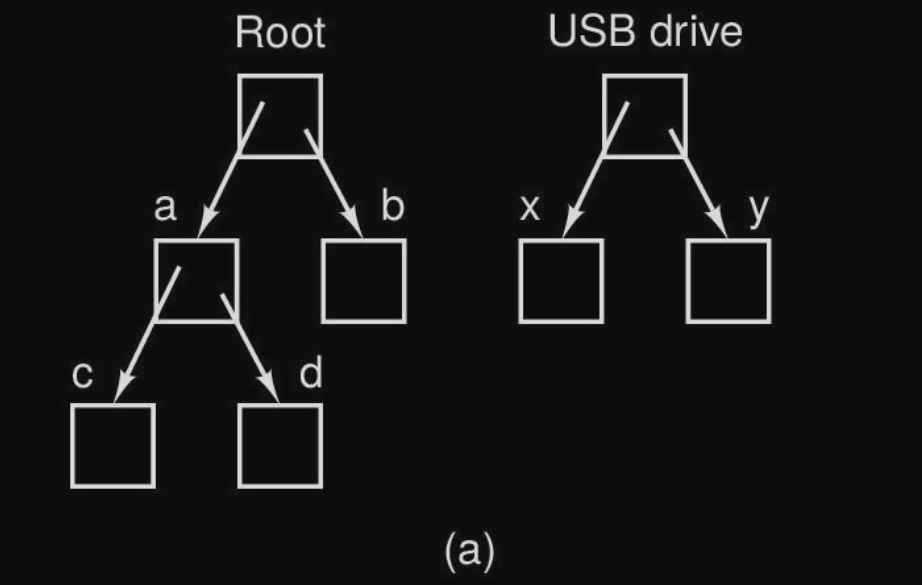
infatti come possiamo vedere non è possibile accedere ai file dell’unità USB.
Dopo avere eseguito l’operazione di mount avremo che :
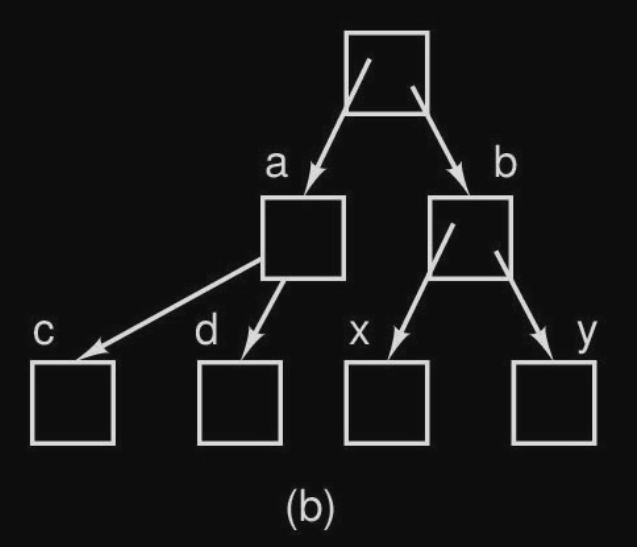
infatti il mount è stato fatto sulla cartella b, e ora è possibile accedere ai file /b/x e /b/y.
File speciali e pipes
In sistemi come UNIX, i dispositivi di I/O possono essere considerati come file speciali (Video interessante) che sono di 2 tipi :
- a blocchi : utilizzati per modellare dispositivi in grado di indirizzare casualmente blocchi di dati (es. dischi)
- a caratteri : utilizzati per modellare dispositivi che gestiscono stream di caratteri (es. stampanti e tastiere)
Un altro tipo di “pseudofile” è la pipe (condotto), che viene utilizzata per connettere serialmente l'uscita di un processo con l'ingresso di un'altro, facilitando la connessione IPC.

Protezione
Nei sistemi come UNIX, i file sono protetti mediante l’assegnazione di un codice di protezione a 9 bit, strutturato in tre ambiti:
- owner
- gruppo owner
- others
Ogni ambito possiede 3 bit di permessi
rwx: r: permesso di letturaw: permesso di scritturax: permesso di esecuzione
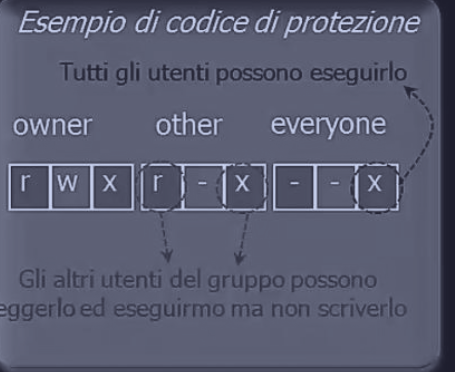
Shell
La shell (interprete dei comandi) è un concetto fondamentale nei OS, sopratutto in quelli UNIX Like (Linux).
È un componente (come editor, compilatori, assemblatori e linker) che non fa parte del OS ed è una interfaccia tra utente e OS.
Quando un utente si autentica in un sistema viene avviata una shell, e quando la shell deve eseguire un comando, vengono utilizzate le system call per la gestione dei processi.
System Call
La system call è il meccanismo che permette ad un programma utente di richiedere servizi direttamente al kernel del OS.
Se un processo utente ha bisogno di leggere un file, deve eseguire una system call, per trasferire il controllo al OS.
Per utilizzare le syscall ci appoggia alle funzioni di libreria (libc) :
- libc : libreria standard che fornisce funzioni di alto livello (es.
printf,fopen,malloc)- diverse implementazioni (es. glibc, musl, uclibc)
- standard POSIX definisce comportamento delle funzioni di libreria, in modo da essere compatibile con i sistemi UNIX-like
Meccanismo di esecuzione delle system call
L’esecuzione di una system call comporta un passaggio dalla modalità utente alla modalità kernel (o modalità supervisore).
Ad esempio:
count = read(file_descriptor, buffer, nbytes);la system call read() restituisce il numero di byte realmente letti nel buffer, ma non è detto che riuscirà a leggere nbytes se per esempio incontra un end-of-file (EOF).
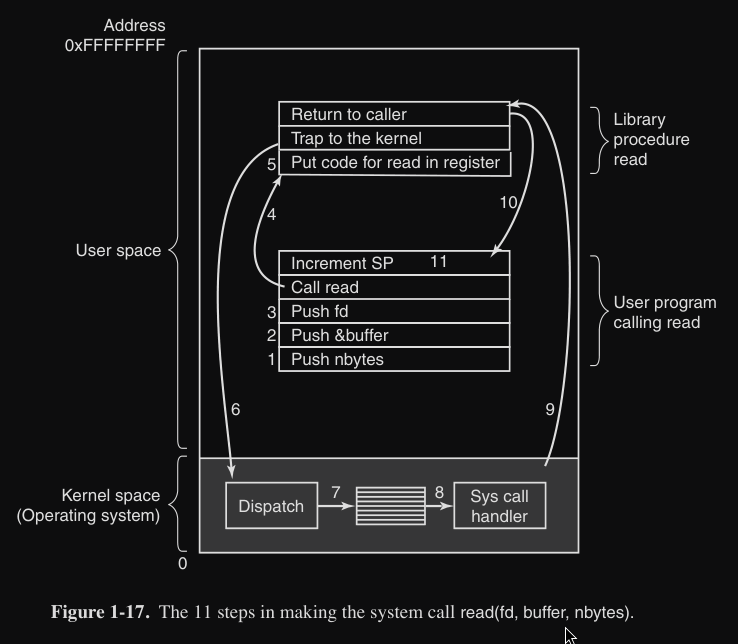
Il funzionamento della system call read() è suddiviso in steps :
- preparazione dei parametri nello stack (1-3)
- chiamata della procedura di libreria
read(4) - la procedura chiamata pone il numero della system call in un registro (es. RAX) (5)
- questo numero identifica quale funzione del kernel deve essere eseguita Linux Sys Call Table
- esecuzione istruzione TRAP (es.
SYSCALLin x86-64) per passare dalla modalità user a kernel (6)- istruzione TRAP è diversa dalle procedure-call perché :
- passa alla modalità kernel
- può saltare solo a un indirizzo specifico o indici di una tabella di memoria
- istruzione TRAP è diversa dalle procedure-call perché :
- scelta del gestore di system call (dispatch) (secondo il numero di sys-call) (7)
- esecuzione del gestore di system call (8)
- controllo ritornato all’istruzione della funzione di libreria successiva all’istruzione TRAP (9) - possibile blocco
- ritorno al programma utente (10)
- il programma utente “pulisce” lo stack (come dopo ogni chiamata di procedura) (11)
Nello step 9 è possibile che il OS non ritorni il controllo alla funzione di libreria, per esempio nel caso in cui l’OS sta cercando di leggere dalla tastiera e niente è arrivato.
System call per la gestione dei processi

fork(): serve per creare un’esatta copia del processo padre (chiamante)- ritorna un valore che è 0 per il figlio e uguale al PID del figlio per il padre (-1 per errore)
Vediamo un esempio per comprendere meglio :
#define TRUE 1
while(TRUE){
type_prompt();
read_command(command, parameters);
if (fork() != 0){
waitpid(-1, &status, 0); // aspetta figlio che finisce
} else {
execve(command, parameter, 0); // esegui il comando
}
}È importante capire che quando il processo padre crea il figlio (fork() != 0), il processo figlio salta direttamente al else perché gli arriva 0 come valore (mentre al padre gli arriva il pid).
System call per le gestione dei file

open: per leggere o scrivere un file, bisogna prima aprirlolseek: molti programmi hanno la necessità di accedere a parti random del file, infatti associato al file esiste un puntatore che indica la posizione all’interno del file (offset). Questa chiamata cambia la posizione del puntatorestat: informazioni sul file (meta-data)fstat: stessa cosa ma per un file aperto
System calls per gestione delle directory/file system

Link - Unlink
link : un uso tipico è la condivisione di un file
Ogni file in UNIX ha un numero chiamato i-number che lo identifica. Questo numero è un indice in una tabella di i-nodes (una per ogni file) che rappresenta le informazioni su quel file (owner, dove è memorizzato etc.). Una directory non è altro che un file che contiene un insieme di coppie (i-number, nome in ASCII).
Quindi quello che fa link è creare una nuova entry nella directory con il nome del file (anche nuovo) ma con lo stesso i-numero del file a cui punta.
Se uno dei file è rimosso, con unlink, l’altro file rimane. Mentre se tutti i file sono rimossi, UNIX vede che non ci sono entry per quel i-number (grazie ad un campo del i-node che tiene traccia di quante directory hanno quel i-number) e quindi rimuove il file dal disco.
Altre system call

System call di Windows
L’approccio alle system call di windows è diverso da UNIX, infatti Windows è guidato dagli eventi (event-driven), ovvero si aspetta che accada un evento (input da tastiera, mouse ecc) e si chiama una procedura per gestirlo.
Microsoft ha definito un insieme di procedure - API Win32 (Application Programming Interface) - che i programmatori possono utilizzare per ottenere servizi dal OS.
Vediamo un confronto tra UNIX e Windows :

Struttura di un OS
Dopo aver analizzato un OS dall’esterno (lato utente e programmatore), vediamo ora una analisi dell’architettura interna dei OS.
Per avere una panoramica degli approcci adottati dai OS, analizzeremo 6 strutture diverse:
- sistemi monolitici
- sistemi a livelli (layered systems)
- sistemi a microkernel
- sistemi client-server
- macchine virtuali (Virtual Machines)
- Exokernel
Sistemi monolitici
Il sistema monolitico è l'approccio più comune nell'organizzazione dei OS, dove l'intero OS viene eseguito come un unico programma binario eseguibile in modalità kernel.
Le caratteristiche sono:
- il sistema è scritto come una collezione di procedure collegate tra di loro in un unico programma eseguibile
- ogni procedura può chiamare un’altra procedura
- la presenza di tante procedure rende il sistema difficile da gestire (un crash in una procedura, porta al blocco dell’intero OS)
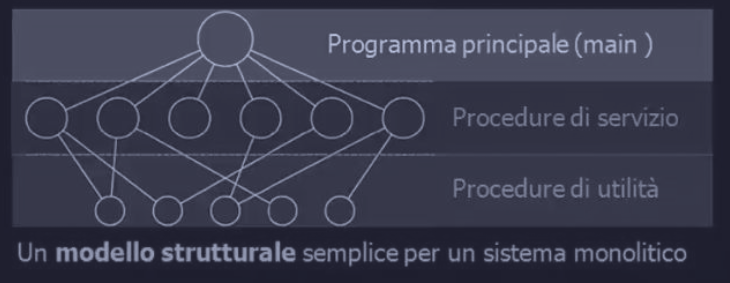
Questa organizzazione ha una struttura tripartita :
- un programma principale che chiama la procedura di servizio richiesta
- un insieme di procedure di servizio che svolgono le chiamate di sistema
- un insieme di procedure di utility che aiutano le procedure di servizio
- compile e linking : tutte le funzioni e procedure del OS devono essere compilate e collegate in unico eseguibile
- mancanza di occultamento : ogni procedura è visibile a tutte le altre procedure, quindi non c’è un vero e proprio “occultamento” o isolamento tra le diverse parti del sistema
- utilizzo di trap : chiamate di sistema in un sistema monolitico vengono richieste e poi eseguendo un’istruzione di trap che fa passare la macchina dalla modalità utente a quella kernel e trasferisce il controllo al OS
- la trap è quindi utilizzata come meccanismo di comunicazioni tra i tre livelli : user mode, kernel mode e hardware
- estensioni caricabili : molti OS permettono di caricare componenti aggiuntivi, come driver I/O o file system, senza riavviare o ricompilare l’intero OS (on demand)
- in UNIX sono chiamate librerie condivise
- in Windows sono chiamate DLL (Dynamic-Link Libraries)
- contengono codice che può essere eseguito da più programmi contemporaneamente, riducendo il numero di copie necessarie in memoria
Sistemi a livelli (Layered Systems)
I sistemi a livelli rappresentano una generalizzazione dell'approccio monolitico, dove l'OS è organizzato come una gerarchia di strati (uno è costruito sopra l'altro).
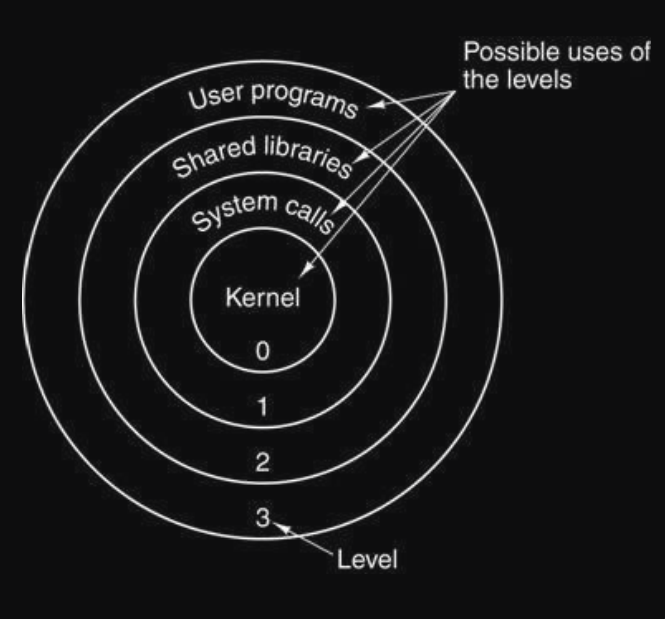
Il primo sistema a livelli fu il THE (Technishe Hogeschool Eindhoven), con sei livelli gerarchici :

Il MULTICS fu invece realizzato come una serie di anelli concentrici, dove gli anelli interni avevano privilegi maggiori rispetto a quelli esterni :
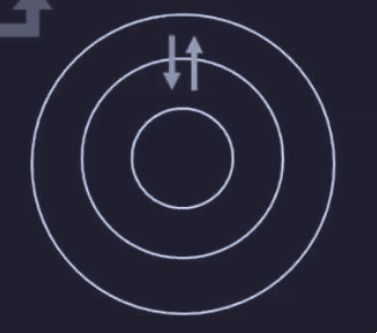
I vantaggi della struttura a “cipolla” sono :
- protezione delle risorse critiche
- separazione chiara dei compiti
Microkernel
L’obiettivo principale della struttura è di ridurre la dimensione del codice che deve essere eseguito in modalità kernel, siccome un crash in quel livello è catastrofico. (es. MINIX)
- si basa sull’idea di suddividere il OS in moduli più piccoli e collaudati
- solo il modulo minimo (microkernel) viene eseguito in modalità kernel
- vengono utilizzati in applicazioni critiche (come ambienti real-time che richiedono affidabilità)
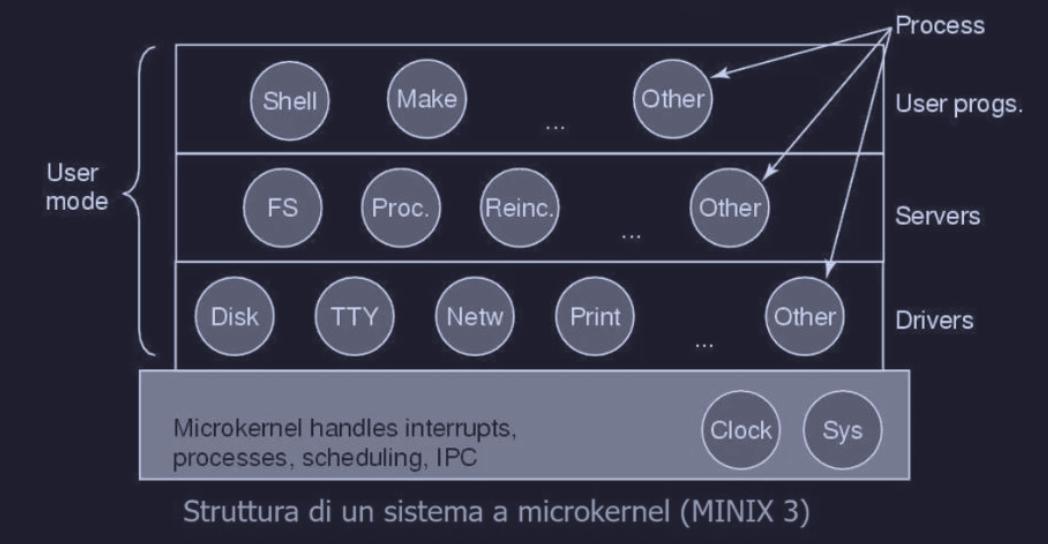
Modello client-server
Il modello client-server è una variante del microkernel che distingue i due i processi:
- server : processi che forniscono servizi
- client : processi che richiedono ed utilizzano i servizi
La comunicazione tra il processo server e quello client, avviene tramite uno scambio di “messaggi” (implementata dal kernel minimale alla base - microkernel). Infatti per richiedere un servizio, il processo client “costruisce” un messaggio con la richiesta e lo invia al server appropriato (es. file server o process manager).
Pro e Contro del microkernel (client/server)
- Pro : facile da aderire al POLA (Principle of Least Authority) :
- implementato con il TCB (Trusted Computing Based) è l’insieme di tutto il codice che deve essere “fidato” per la sicurezza del sistema
- nel microkernel, solo il kernel minimale è nel TCB
- Contro : il passaggio di messaggi è più lento di una chiamata di funzione (come nel monolitico)
Macchine virtuali
La virtualizzazione è l’idea di base da cui nascono i sistemi time-sharing TSS/360 di IBM, dove più utenti potevano lavorare nei terminali collegati alla stessa macchina.
VM/370
Questo sistema (anni 70’) è stato uno dei primi sistemi a implementare macchine virtuali, creando ambienti virtuali identici all’hardware fisici e che permetteva quindi :
- isolamento : ogni vm opera indipendentemente
- flessibilità : eseguire diversi OS (es. OS/360 e CMS)
- gestione semplificata : gestione e manutenzione semplificate separando la multiprogrammazione e risorse hardware
Il cuore del sistema è il virtual machine monitor (interfacce), che permette la multiprogrammazione e permette l’esecuzione di più vm :
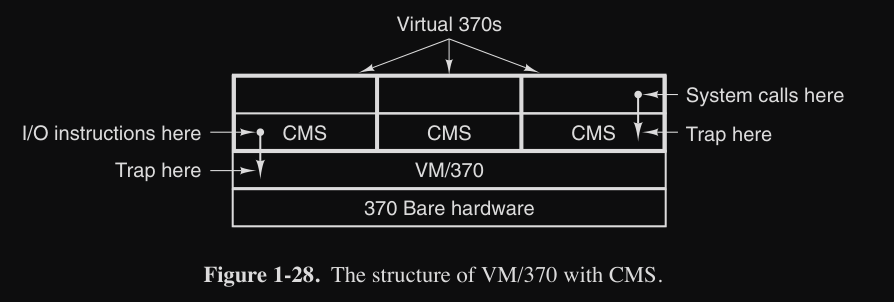
Il sistema z/VM (utilizzato sugli attuali mainframe IBM zSeries) è il discendente diretto del TSS/360 e permette di far girare più OS completi, come Linux, in ambienti con tante transazioni e dati.
VM rediscovered
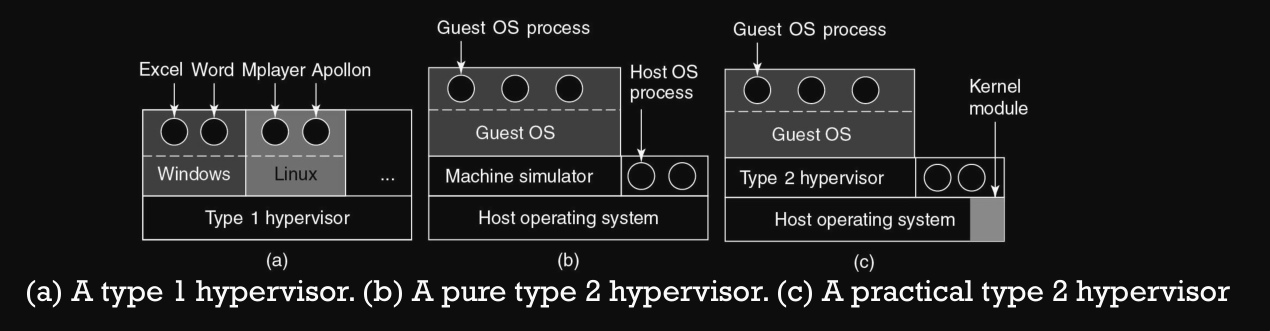
Le vm funzionano sopra quelli che sono chiamati hypervisor (o virtual machine monitor) che possono essere di due tipi :
- tipo 1 : eseguito sul hardware direttamente (senza supporto del OS) (es. Xen)
- tipo 2 : utilizza il OS host (e tutte le sue risorse) per creare processi, memorizzare file etc. (es. QEMU)
- in teoria non c’è nessuna specializzazione del OS host (b)
- nella pratica esiste un modulo kernel utilizzato per ottimizzare il processo di simulazione (c)
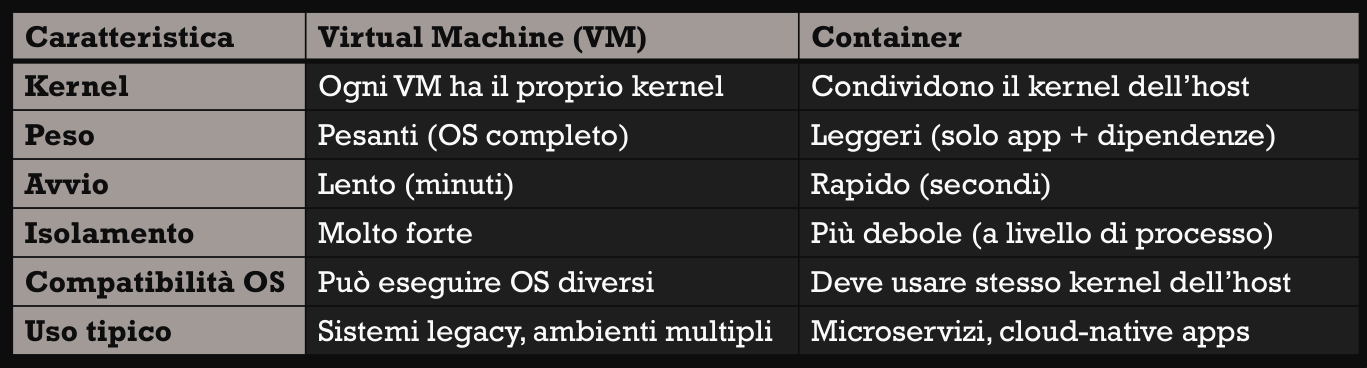
VM vs Container
Le VM :
- includono un OS completo, +memoria e +cpu → avvio lento
- ottimo per isolamento forte, ma abbiamo poche istanze per host
- operazioni lente per ambienti dinamici
Le esigenze moderne infatti richiedono :
- ridurre overhead per aumentare il numero di istanze
- avvio rapido e rollback facili per rilasci frequenti
- portabilità dell’ambiente
Per questo sono stati sviluppati i container, che hanno la stessa logica dell’isolamento ma senza un OS per istanza.
I container permettono di eseguire più istanze isolate di applicazioni (servizi) sopra lo stesso kernel del OS host.
Ogni container condivide il kernel e le librerie di base con l'host, ma mantiene il file system, librerie e configurazioni proprie.
Pro :
- veloci da avviare e leggeri
- ideali per deploy veloci e scalabile (es Docker e Kubernetes)
- utilizzo più efficiente delle risorse rispetto alle VM
Contro :
- non è possibile eseguire più OS
- isolamento meno forte delle VM (se il kernel viene compromesso, anche gli altri container ne soffrono)
Exokernel
L’approccio Exokernel costituisce una strategia alternativa alla clonazione di macchine reali, concentrandosi sulla partizione della macchina per assegnare ad ogni utente un sottoinsieme specifico di risorse.
Ad esempio si possono assegnare ad una macchina virtuale i blocchi del disco da 0 a 1023, ad un’altra quelli successivi (da 1024 a 2047) e così via.
L’exokernel viene eseguito in modalità kernel, e il suo compito è allocare le risorse alle macchine virtuali e gestendo l’utilizzo, garantendo che ogni VM utilizzi solo le risorse a essa assegnate.
Unikernel
Gli unikernel sono sistemi molto minimi basati su LibOS, dove viene eseguita una sola applicazione su una macchina virtuale (es. server web). Infatti questi sistemi hanno solo le funzionalità necessarie per eseguire l’applicazione specifica.
Questi sistemi sono altamente efficienti, siccome non richiedono la protezione tra le applicazione (vi è solo una).
Questo concetto degli unikernel è stato recentemente riscoperto e riutilizzato per una soluzione efficiente per eseguire applicazioni isolate sulle macchine virtuali.
