
I sistemi interattivi sono quelli tipici dei PC, server e altri sistemi dove ci sono utenti impazienti di risposte rapide.
L’obiettivo principale è il tempo di risposta, ovvero minimizzare il tempo che percorre tra l’invio del comando da parte dell’utente e l’ottenimento del risultato, per questo motivo si utilizzano algoritmi preemptive:
- Round-Robin (RR)
- scheduling con priorità
- Shortest Process Next - SPN
- scheduling garantito
- lottery scheduling (a lotteria)
- fair-share scheduling (a quota equa)
Round-Robin
L’algoritmo Round-Robin è uno degli algoritmi :
-
- vecchio
-
- semplice
-
- equilibrato
-
- utilizzato
È un algoritmo dove ad ogni processo viene assegnato un intervallo di tempo (quantum), durante il quale può essere eseguito.
La logica dell’algoritmo è semplice:
- i processi in stato ready sono mantenuti in una coda
- quando un processo termina la sua quantum, si rimette in coda
- se il processo si blocca (es. attesa I/O) non si aspetta che finisce la quantum, ma la CPU viene assegnata al processo successivo in coda

Dobbiamo inoltre considerare che la scelta della quantum assegnata è un fattore critico:
- quantum troppo breve troppe interruzioni dei processi + overhead per il context switch
- quantum troppo alta attesa eccessiva
Un quantum di 20-50 ms è spesso ragionevole e un buon compromesso tra efficienza e reattività.
Scheduling con priorità :luc_chevron_up:
Nello scheduling round-robin c’è l’assunzione è che tutti i processi sono ugualmente importanti, ma in molti contesti reali questa ipotesi è troppo restrittiva (es. università con differenti ruoli).
Un approccio differente è quello di assegnare una priorità a ciascun processo e lo scheduler tiene conto della priorità nel momento in cui deve scegliere il processo da mandare in esecuzione.
Per esempio un daemon mail avrebbe meno priorità di un video in tempo reale. #review Inoltre per evitare che i processi ad alta priorità girino per troppo tempo, lo scheduler può:
-
diminuire la priorità del processo in esecuzione ad ogni ciclo di clock
- se scende sotto quella del processo successivo, avviene uno scambio
-
utilizzare un quantum di tempo massimo
L’assegnazione delle priorità può essere:
- statica: assegnate all’inizio dell’esecuzione e mantengono un valore fisso (es. priorità basate sull’utente)
- dinamica: assegnate o modificate dal sistema in modo dinamico per raggiungere obiettivi di sistema (es. basata sull’utilizzo della CPU)
Priorità + Round-Robin
Una configurazione comune combina la priorità con il Round-Robin, dove si raggruppano i processi in classi di priorità e si usa lo scheduling con priorità tra le classi (piuttosto che tra singoli processi), ma all’interno di ciascuna classe si applica l’algoritmo Round-Robin.
Per esempio consideriamo un sistema con 4 classi di priorità :
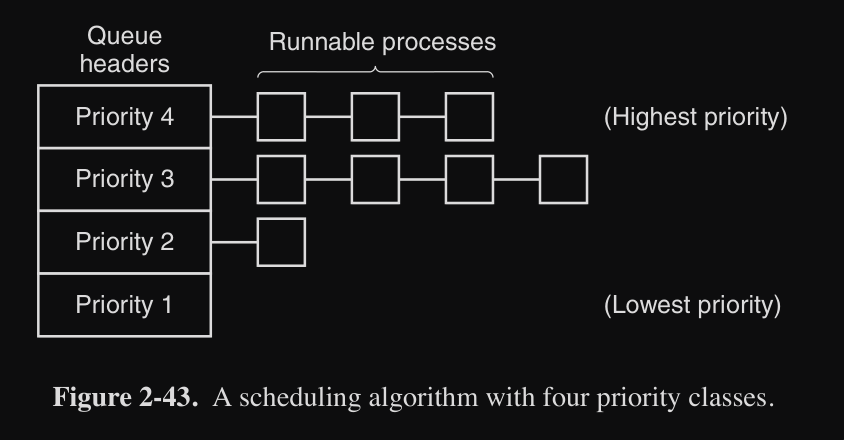
- finché ci sono processi nella classe 4, esegui ognuno di questi processi con round-robin e fregatene delle altre classi
- se la classe 4 è vuota, passa alla 3, se la 3 è vuota, passa alla 2 e cosi via
review Bisogna però tenere in considerazione che se le priorità non cambiano occasionalmente, i processi delle classi di priorità bassa potrebbero “morire di fame” (starvation).
Shortest Process next - SPN
Poiché l’algoritmo SJF fornisce il tempo medio di risposta nei sistemi batch, sarebbe ideale applicare un principio simile anche ai processi interattivi per minimizzare il tempo medio di risposta totale.
Il principio di misura quindi si basa sull’idea di misurare quanto durerà la prossima esecuzione in base al tempo effettivo delle esecuzioni precedenti.
dove :
- è un fattore di peso compreso tra 0 e 1, che decide quanto rapidamente la stime “dimenticano” il passato (di solito è buono 0.5)
- : tempo effettivo di esecuzione
- : stima tempo di esecuzione
Facciamo un esempio, supponiamo di avere i tempi (esatti) di esecuzione dei 4 processi precedenti:
e vogliamo calcolare la stima del 5 processo utilizzando :
Osserviamo quindi che :
- non potremmo calcolare se non conosciamo
- il peso di è calato di (pesa meno)
Scheduling garantito :luc_check_circle:
Un approccio completamente diverso per lo scheduling è quello stipulare promesse reali agli utenti riguardo alle prestazioni del sistema e poi rispettarle.
Il funzionamento per mantenere la promessa :
- il sistema memorizza quanta CPU ciascun processo ha effettivamente utilizzato dalla sua creazione =
- il tempo che un processo ha diritto (promessa) è calcolato come il tempo trascorso () dalla sua creazione diviso per (il numero di utenti o processi concorrenti)
- poi si calcola il rapporto tra il tempo effettivo utilizzato e la promessa
- l’algoritmo assegna la CPU al processo che presenta il rapporto più basso
Un rapporto quindi di 0.5 indica che il processo ha avuto solo metà di ciò che gli spetta.
Per esempio :
1 : creato da 20 sec, usato 10 sec
2 : creato da 10 sec, usato 3 sec
3 : creato da 50 sec, usato 40 sec
promessa1 = 20/3 = 6.6
promessa2 = 10/3 = 3.3
promessa3 = 50/3 = 16.6
rapporto1 = 10/6.6 = 1.5 -> secondo
rapporto2 = 3/3.3 = 0.9 -> primo
rapporto3 = 40/16.6 = 2.4 -> terzo
Analogia per capire meglio :

Scheduling a lotteria :luc_ticket:
Fare promesse agli utenti è una bella idea ma è difficile da realizzare.
Per questo viene introdotto un algoritmo più semplice che assegna un “biglietto della lotteria” per ottenere le varie risorse del sistema, come il tempo della CPU.
Ogni volta che deve essere presa una decisione dello scheduler si “pesca” a caso un biglietto della lotteria e il processo che ha quel biglietto si “aggiudica” la risorsa (es. un quantum di tempo CPU)
A processi più importanti possono essere dati biglietti extra per incrementare la probabilità di vincere. Infatti per esempio se un processo possiede 20 biglietti su 100 biglietti totali, allora ha il 20% di probabilità di ottenere la risorsa ad ogni “estrazione”.
Le proprietà interessanti di questo algoritmo sono:
- reattività : appena un processo arriva gli vengono assegnati dei biglietti e quindi ha già la possibilità di vincere alla prossima “estrazione”
- cooperazione : i processi possono scambiarsi i loro biglietti, alterando dinamicamente le priorità
Scheduling fair-share
Consideriamo la seguente situazione: se un utente x avvia 9 processi ed un altro utente y ne avvia 1 soltanto, con round-robin o priorità uguali, il primo utente si prenderà il 90% del tempo CPU, mentre il secondo solo il 10%.
Quindi l’obiettivo dell’algoritmo fair-share è quello di impedire questa in-equità, ovvero che un utente “ricco di processi” possa dominare.
Il funzionamento :
- a ciascun utente viene assegnata una frazione della CPU (la quota equa)
- lo scheduler agisce in modo da rispettare tale quota, con un “altro algoritmo” di scheduling (indipendentemente dal numero di processi posseduti)
Consideriamo per esempio due utenti :
- utente x con 4 processi : A, B, C e D
- utente y con 1 processo : E
- a entrambi gli utenti viene assegnata una quota del 50% di utilizzo, se lo scheduler utilizza il round-robin avremo :
oppure è possibile che l’utente x abbia una quota maggiore (es. 66.7%) e l’utente y una quota minore (es. 33.3%), si potrebbe ottenere una sequenza come la seguente (sempre round-robin) :
Tabella di riepilogo
