
Separazione tra politica e meccanismo
Fino ad ora abbiamo assunto che tutti processi appartengono a diversi utenti, tuttavia nella realtà, un processo può avere molti processi figli eseguiti sotto il suo controllo. Il problema è che lo scheduler che opera al livello più basso, vede tutti i processi come equivalenti. Di conseguenza, il processo genitore, che conosce molto bene quali priorità dare ai suoi “figli”, non ha la capacità di applicare questa conoscenza in modo diretto allo scheduler siccome gli scheduler tradizionali che operano a livello kernel non accettano nessun input dai processi utente riguardo le decisioni di scheduling.
La soluzione a questo problema consiste nel separare il meccanismo di scheduling dalla politica di scheduling:
- meccanismo: parte del sistema che implementa le procedure di base per lo scheduling, come il cambio di contesto
- politica: si riferisce alle regole di alto livello che decidono quale processo (o thread) debba essere eseguito e per quanto tempo
Questo vuol dire che l’algoritmo di scheduling viene parametrizzato, permettendo ai processi utente di fornire i parametri necessari per il suo funzionamento.
Quindi per esempio possiamo avere :
- kernel con algoritmo di scheduling a priorità
- una chiamata di sistema permette ad un processo di passare dei parametri per configurare le priorità dei figli in questo modo il processo padre influenza lo scheduling dei suoi figli senza controllarlo direttamente.
Scheduling a thread
Quando i processi hanno più thread possiamo definire due livelli di parallelismo:
- sui processi
- sui thread
La schedulazione in questi ambienti dipende se i thread siano implementati a livello utente o a livello kernel (o entrambi).
Scheduling dei Thread a livello utente :luc_user:
Nei sistemi che utilizzano thread a livello utente, il kernel non è a conoscenza della loro esistenza, infatti esso gestisce e vede solo i processi che contengono i thread.
Supponiamo che:
- il processo A ha tre thread :
A1,A2,A3 - il processo B ha tre thread :
B1,B2,B3 - lo scheduler (a livello kernel) sceglie il processo A e gli da il controllo per un certo quantum di tempo
- ora lo scheduler interno di thread di A decide quale thread eseguire (es.
A1) - se
A1consuma tutto il quantum di A, lo scheduler (kernel) sceglie un altro processo
Quindi la sequenza di attivazione: A1 B1 A2 B2 A3 B3 NON è possibile siccome lo scheduler (kernel) non conosce l’esistenza di questi thread.
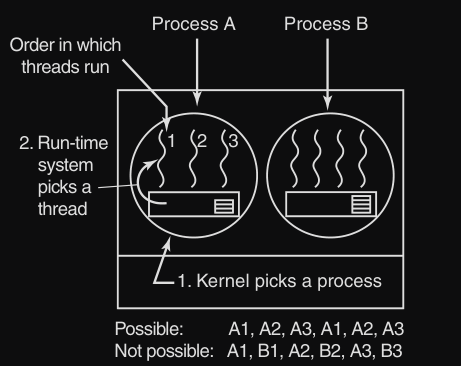
Questo siccome per esempio se il kernel assegna una quantum di 50 ms al processo A, il suo sistema run-time deciderà quale thread eseguire (A1 o A2 o A3). Supponiamo decide A1, A1 spreca 5 ms, ma poi il controllo ripassa al sistema run-time, finché non saranno consumati 50 ms totali del processo A. Quindi non è possibile per esempio il salto a B1 una volta che A1 ha sprecato i suoi 5 ms.
Scheduler dei Thread a livello kernel
Lo scheduler kernel conosce adesso i thread e ne prende uno per l’esecuzione.
Al thread è assegnato una quantum di tempo, e se il thread supera questo valore, viene sospeso forzatamente dal kernel.
Quindi ora la sequenza : A1 B1 A2 B2 A3 B3 è ora possibile.
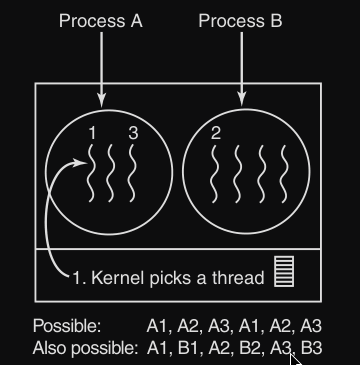
Ora è possibile siccome per esempio, una volta che A1 ha sprecato i suoi 5 ms (che poi fanno parte della sua quantum di 50 ms), il controllo ritorna allo scheduler che decide un altro thread (tra tutti quelli disponibili).