
I thread sono processi leggeri, che a differenza dei processi condividono lo spazio degli indirizzi e i dati.
I vantaggi di utilizzo dei thread :
- semplificazione del modello di programmazione : molte applicazioni comportano attività multiple che si svolgono contemporaneamente, decomponendo quindi l’applicazione in thread sequenziali multipli che vengono eseguiti “quasi in parallelo”
- sono più leggeri dei processi e quindi sono molto facili da creare e “distruggere” - lightweight processes
- hanno un migliore utilizzo della CPU (evitano l‘“ozio” della CPU), infatti quando un thread è in attesa di I/O, un altro thread va avanti
Un ambiente che consente a più thread di girare nello stesso processo è chiamato multithreading. Inoltre le CPU moderne che supportano il multithreading, riescono a passare da un thread all'altro in pochissimo tempo (nanosecondi).
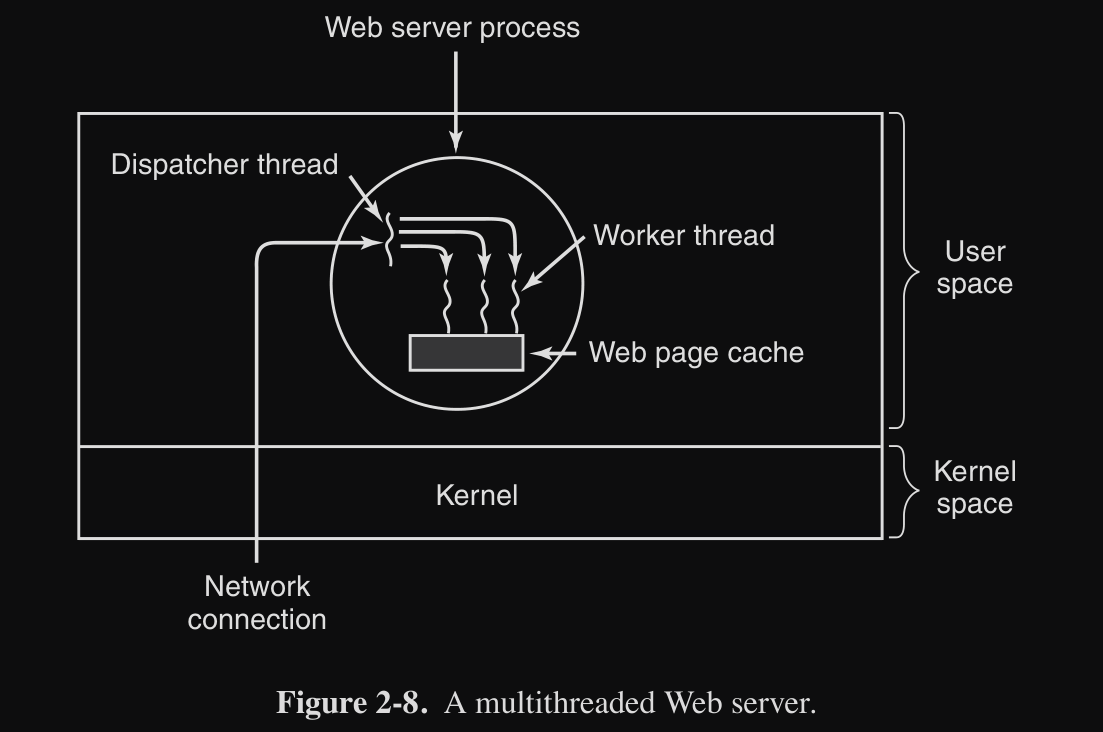
Un esempio di utilizzo dei thread è quello di Web Server :
- le richieste di pagine arrivano dal client
- un dispatcher thread legge le richieste in arrivo dalla rete
- la richiesta passa ad un worker thread che cerca la pagina
- mentre il primo worker thread cerca (operazione I/O), un altro thread può essere eseguito (o dispatcher o un altro worker)
Una possibile implementazione (pseudo-codice) dei due thread potrebbero essere :
- dispatcher
while(TRUE){
get_net_request(&buf);
handoff_work(&buf);
}- worker
while(TRUE){
wait_for_work(&buf);
look_for_page_in_cache(&buf, &page);
if (page_not_in_cache(&page))
read_page_from_disk(&buf, &page);
return_page(&page);
}Processi vs Thread
Più processi che girano in parallelo in un computer è diverso da più thread che girano in parallelo:
- nel primo caso, i processi che girano condividono solo la memoria fisica, i dischi, le stampanti e le altre risorse
- nel secondo caso i thread condividono anche lo spazio di indirizzamento
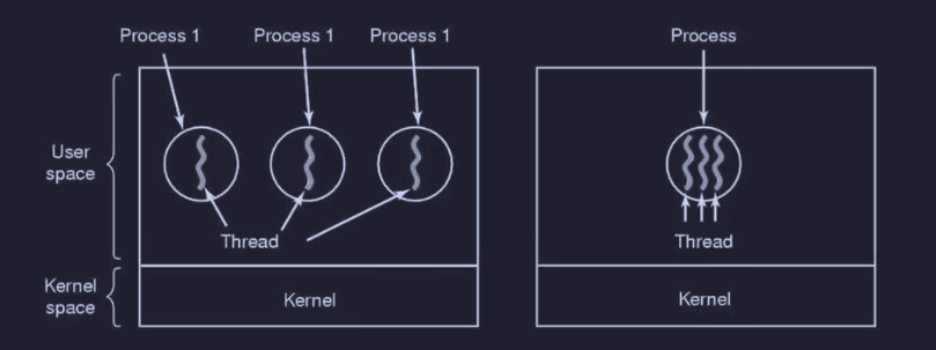
I thread risiedono nello stesso spazio di indirizzi di un singolo processo. Quindi gli scambi di informazioni avvengono tramite la condivisione di dati tra i thread (sincronizzazione con primitive).
Inoltre ogni thread può chiamare system call, per conto del processo a cui appartiene.
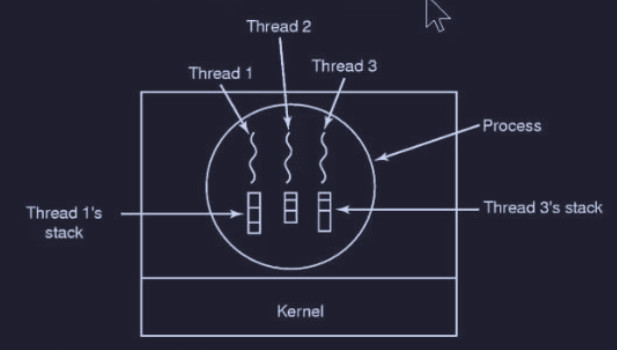
Elementi condivisi e non condivisi di un thread
Ogni thread possiede elementi che non condivide (privati) e altri che sono condivisi con altri thread:
- elementi privati :
- set di registri: per contenere variabili locali e lo stato corrente (pc e sp)
- stack
- attributi: (es. dimensione dello stack)
- stato del thread
- elementi condivisi :
- spazio di indirizzamento (memoria condivisa)
- file aperti
- allarmi in sospeso
- gestore di segnali
- variabili globali e dati
- informazioni account (UID, GID)
I thread possono avere relazioni gerarchiche (padre-figlio) oppure essere allo stesso livello (più comune).
Thread POSIX :luc_layout_dashboard:
Per garantire la scrittura di programmi multithreaded portatili, l’IEEE ha definito lo standard 1003.1c.
I thread definiti con questo standard sono chiamati Pthreads (supportati dai principali sistemi UNIX).
Lo standard definisce più di 60 system call, tra cui:
Pthread_create: crea un nuovo thread (ritorna id del nuovo thread)Pthread_exit: termina il thread che la invocaPthread_join: attende che un thread specifico terminiPthread_yield: concede CPU per un altro threadPthread_attr_init: crea e inizializza la struct con gli attribuiti del threadPthread_attr_destroy: rimuove la struct degli attributi del thread
Vediamo un esempio in C che crea NUMBER_OF_THREADS e poi finisce :
#include <pthread.h> # <-
#include <stdio.h>
#include <stdlib.h>
#define NUMBER_OF_THREADS 10
void *print_hello_world(void *tid){
printf("Hello World. Greetings from thread %d\n", tid);
pthread_exit(NULL);
}
int main(int argc, char *argv[]){
pthread_t threads[NUMBER_OF_THREADS];
int status;
for(int i=0; i < NUMBER_OF_THREADS; i++){
printf("Main here, creating thread %d",i);
status = pthread_create(&threads[i], NULL, print_hello_world, (void *)i);
if (status != 0){
printf("Error creating thread, returned error code %d\n", status);
exit(-1);
}
}
exit(NULL);
}PS : vedi Gestione_pthreads
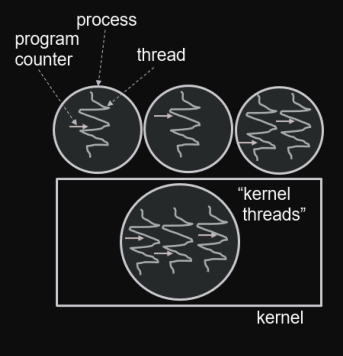
Implementazione dei thread
I thread possono essere implementati :
- a livello utente
- nel kernel
- ibrida
Implementazione dei thread a livello utente
L’implementazione dei thread a livello utente consiste :
- kernel non conosce la loro esistenza
- kernel vede solo il processo che contiene i thread
- gestiti tramite una libreria
- utilizzati dai OS che non supportano i thread
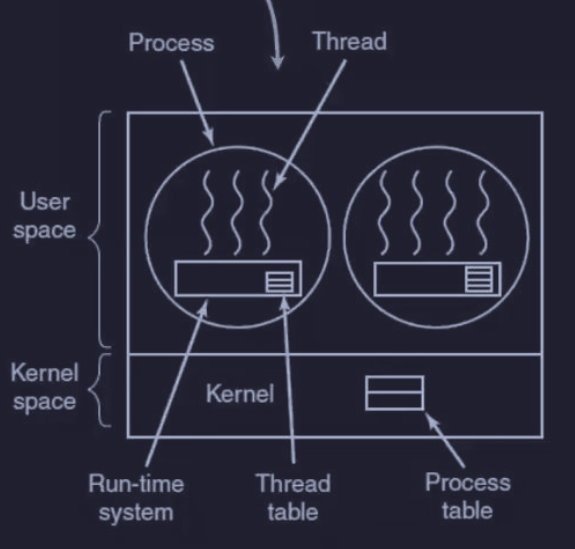
Con questa implementazione, ogni processo necessita di una tabella dei thread per tenere traccia dello stato e altre informazioni dei suoi thread (PC, SP, registri).
Quindi non c’è la necessità di :
- trap del kernel
- cambio di modalità utente/kernel
- niente intervento dello scheduler del OS poter personalizzare l'algoritmo di scheduling per ogni processo
Ci sono però dei problemi :
- siccome il kernel vede i singoli processi :
- se un thread fa una chiamata bloccante, blocca l’intero processo (anche gli altri thread)
- page fault bloccano l’intero processo, quando sono causati da un thread a livello utente
- No preemption: l’interrupt clock (utilizzato nello scheduling preemptive) è gestito dal kernel, che non conosce i singoli thread ma solo il processo. Quindi non esiste un meccanismo per strappare forzatamente la CPU a un thread utente
- meno adatti per applicazioni dove i thread si bloccano frequentemente (es. web server) : quando un thread a livello utente deve fare un’operazione I/O, deve fare una system call al kernel, che mette in attesa quel thread, ma questo vuol dire mettere in attesa l’intero processo (anche gli altri thread)
Implementazione dei thread a livello kernel
In questa implementazione :
- kernel conosce e gestisce tutti i thread
- nessun sistema run-time di gestione e schedulazione dei thread è necessario
- tabella dei thread tenuta a livello kernel
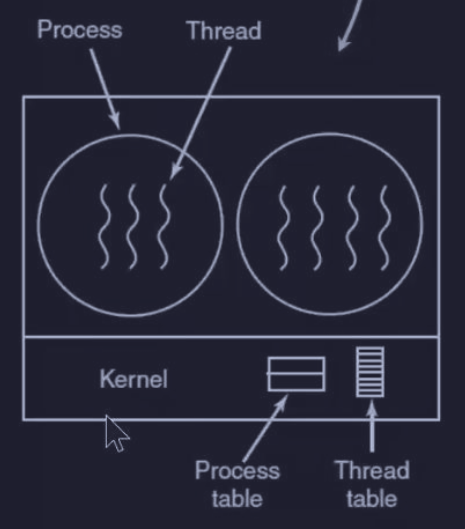
Vantaggio :
- se un thread si blocca, il kernel può scegliere di eseguire un thread pronto dello stesso processo o di un processo diverso
Svantaggi :
- costi maggiori rispetto alle chiamate di procedura dei sistemi run-time
- serve cautela nella programmazione con essi, siccome un errore a livello kernel è un problema.
Per ridurre i costi, alcuni sistemi “riciclano” i thread (kernel moderni non lo fanno) :
- quando un thread deve essere distrutto, viene marcato
- quando c’è bisogno di creare un nuovo thread, si prende uno di quelli marcati
Implementazione ibrida
L’implementazione ibrida permette di unire i due vantaggi :
- funzionalità dei thread a livello kernel
- prestazioni e flessibilità dei thread a livello utente
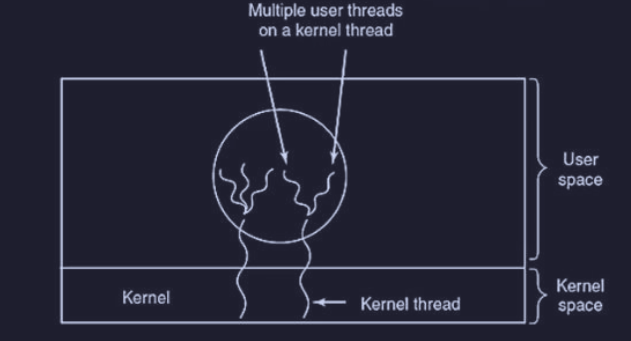
Si utilizzano i thread a livello kernel come “binari” su cui far correre i thread a livello utente in modo multiplexato. Quindi il kernel non vede tutti i thread utente, ma vede e pianifica solo i thread a livello kernel.
I programmatori possono decidere quanti thread del kernel utilizzare e quanti thread utente multiplexare su di essi (maggiore flessibilità).
Thread : problemi aperti
Un problema fondamentale è che molte funzioni di libreria non sono state progettate per essere usate contemporaneamente da più thread.
Per risolvere questi conflitti si usano dei wrappers per le funzioni, che consiste nel impostare un bit per segnalare che la libreria è in uso (limita il parallelismo).
Un altro problema è la gestione dei segnali in un ambiente multithread, siccome il OS non sa a quale thread recapitarli.