
I multiprocessori avevano un grande vantaggio, ovvero la semplicità di comunicazione, dove tutte le CPU scrivevano sulla stessa memoria comune e la sincronizzazione può essere fatta usando mutex, semafori o monitor. Però costruire multiprocessori con moltissime CPU è tecnicamente difficile e costa troppo.
Per spendere meno e scalare di più, si collegano insieme tanti computer completi. La differenza fondamentale è che qui non c’è una memoria condivisa per scambiare messaggi. Ogni processore ha la sua RAM privata.
Questi sistemi sono anche chiamati cluster di computer (o Cluster of Workstations - COW).
I multicomputer sono facili da costruire, siccome il componente base è un PC con una scheda di rete con alte performance. Quindi in un multicomputer per ottenere alte performance bisogna “spaccare” nel progetto della rete di interconnessione e delle schede di rete.
Nei multicomputer i messaggi sono spediti in un tempo nell’ordine dei µsec (microsecondi), ovvero 1000 volte più rispetto ad un accesso in memoria (ordine dei nanosecondi).
Hardware dei multicomputer
Il nodo base di un multicomputer consiste in :
- CPU
- memoria
- interfaccia di rete
- hard disk (alcune volte) Quindi ogni nodo è collegato ad altri nodi attraverso l’interfaccia di rete e con uno o due cavi (o fibra), oppure agli switch.
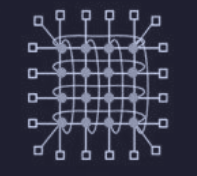
^diametro Ci sono quindi tutte le varie topologie di rete che possiamo avere :
- stella
- anello (non sono necessari switch)
- griglia (o mesh) : struttura bidimensionale che la rende scalabile e il percorso più lungo tra due nodi (diametro) aumenta come la radice quadrata del numero dei nodi

- doppio toro : variante della griglia con i nodi estremi che si congiungono
- più tollerante ai guasti della griglia
- diametro più piccolo della griglia
Schemi di switching
Nei multicomputer sono usati due tipi di schemi di switching :
- store-and-forward packet switching (connection-less) : ogni messaggio è suddiviso in pacchetti che poi sono inviati nella rete
- il pacchetto raggiunge il nodo destinatario attraverso politiche di instradamento che dipendono da vari fattori (es. traffico di dati, priorità etc)
- problema dell’incremento dei tempi di latenza lungo la rete
- circuit switching (connection oriented) : il primo switch stabilisce un collegamento fisico con lo switch del nodo destinatario
- una volta che la connessione è stata stabilita, vengono mandati i bit alla massima velocità
- perdita di tempo all’inizio per stabilire la connessione
Interfacce di rete
Le interfacce di ogni nodo contengono una RAM per memorizzare i pacchetti che entrano ed escono dal nodo.

Inoltre la scheda d’interfaccia può avere uno o più canali DMA oppure una CPU completa - processori di rete. Con l’utilizzo di canali DMA, i pacchetti possono essere copiati tra la scheda d’interfaccia e la RAM principale del computer in modo molto veloce (senza usare la CPU).
Software di comunicazione a basso livello
Il problema principale dei multicomputer è l’eccessiva copia di pacchetti, infatti ogni volta che un programma vuole spedire un messaggio a un altro computer, il dato non vola magicamente a destinazione, ma deve essere copiato dalla memoria del programma a quella del OS, poi a quella della scheda di rete, poi viaggiare sul cavo, e poi fare tutto il percorso inverso sul computer ricevente. Tutto questo è una perdita di tempo enorme e quindi la soluzione intelligente è “tagliare l’intermediario”, ovvero si dà al programma il permesso di scrivere direttamente sulla memoria della scheda di rete, saltando completamente i passaggi attraverso il OS (kernel).
Questa soluzione ha due problemi :
- competizione dei processi concorrenti sullo stesso nodo che vogliono spedire pacchetti, quindi è meglio avere un solo processo per nodo
- condivisione della scheda di rete con il kernel e il processo utente, infatti se il kernel vuole accedere ad un file system remoto è un problema. Per questo è meglio utilizzare due schede di rete per ogni funzione
Software di comunicazione a livello utente
I processi sulle diverse CPU di un multicomputer, come abbiamo già capito, comunicano con lo scambio di messaggi. Infatti il OS fornisce le primitive che permettono ai processi utente di :
- inviare -
send(dest, &msg_pointer); - ricevere -
receive(addr, &msg_pointer);
In un multicomputer statico il numero di CPU è noto, quindi il campo addr (address) si compone di :
- id della CPU
- id del processo o della porta sulla CPU selezionata
Primitive bloccanti e non bloccanti
Le primitive send() e receive() possono essere :
- bloccanti : chiamate sincrone
- non bloccanti : chiamate asincrone
Per esempio se send() fosse asincrona (non bloccante), il controllo viene subito passato al chiamante, subito dopo la sua esecuzione e prima che venga realmente spedito il messaggio. Mentre nel caso fosse sincrona (bloccante) il chiamante rimane in attesa finché il msg non è stato inviato.
Lo svantaggio di quelle asincrone per esempio è che se il processo invocato send(), esso non può accedere al buffer fino a che non è vuoto e il messaggio spedito completamente.
Inoltre non si conosce quando la trasmissione sarà terminata.
Esistono però tre possibili soluzioni per questo problema :
- il kernel copia il messaggio in buffer interno (eccesso di copie)
- finita la spedizione il mittente riceve un interrupt in modo che posso ri-utilizzare il buffer (gestione interrupt a livello utente complessa)
- usare la tecnica del copy-on-write, quindi se il processo prova a scrivere nuovi dati sul buffer mentre la spedizione è in corso, il OS interviene, e fa una copia dei vecchi dati per la scheda di rete, e lascia che il processo scriva i nuovi dati (anche qui eccesso di copie)
Quindi il processo mittente ha le seguenti scelte di spedizione :
- spedizione bloccante e mantenere la CPU bloccata
- spedizione non bloccante con copia (CPU spreca tempo per fare la copia)
- spedizione non bloccante con interrupt (programmazione complessa)
- spedizione non bloccante con copy-on-write (stesso problema della prima)
Possiamo notare che in un sistema multi-thread la prima scelta è la migliore, infatti mentre un thread è bloccato con
send(), gli altri continuano a lavorare.
Mentre il processo destinatario può utilizzare una receive() non bloccante che indica semplicemente al kernel dove è il buffer. Inoltre l’arrivo di un messaggio può essere gestito nei seguenti modi :
- tramite interrupt (complesso)
- richiamando una procedura
poll()che ci dice se ci sono messaggi in attesa di esser letti - creazione automatica di thread pop-up (muore da solo subito dopo)
- messaggi attivi : interrupt che attiva nella ISR il codice di gestione. Questo modo è una versione ibrida che sfrutta l’idea del thread pop-up ma senza creare alcun thread, migliorando le performance
Remote Procedure Call - RPC
Anche se modello a scambio di messaggi è un sistema conveniente per un OS multicomputer, tutte le comunicazioni (e quindi i programmi) utilizzano l’I/O. Mentre un approccio diverso è quello che consente ai programmi di chiamare procedure che si trovano su altre CPU del multicomputer in modo indipendente dell’I/O.
Questa tecnica è chiamata RPC (Remote Procedure Call) ed è alla base del software per i multicomputer.
Per chiamare una procedure remota il programma client deve avere una piccola procedura chiamata client stub. Mentre il programma server ha una procedura chiamata server stub.
I passaggi del funzionamento sono i seguenti :
- programma client chiama il client stub (locale)
- client stub confeziona un msg e chiede al OS di spedirlo - marshaling
- kernel spedisce il msg dal nodo client a quello server
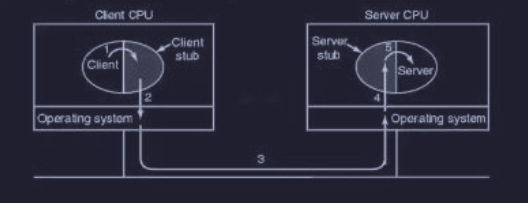
- kernel del server (destinazione) passa il msg al server stub
- server stub chiama la procedura invocata dal client
Tutto fantastico, ma ci sono delle insidie :
- non è possibile utilizzare i puntatori come parametri (siccome siamo su spazio di indirizzi diversi)
- se si utilizzano array come parametri, bisogna specificare le dimensioni
- il ricevente deve sapere in anticipo esattamente che tipo di dato sta arrivando per decodificarlo. Se il tipo non è deducibile, la RPC fallisce (ci si riferisce alle funzioni poliforme)
- non è possibile utilizzare le variabili globali
Distributed shared memory - DSM
Sebbene RPC sia interessante, molti programmatori preferiscono utilizzare il modello di memoria condivisa (come nei multiprocessori) anche sui i multicomputer.
Infatti con la tecnica del DSM (Distributed Shared Memory) è possibile fornire “un’iAssegnazione inizialellusione” che tutti i computer del cluster abbiamo una unica e grande memoria condivisa.
In questa tecnica ogni macchina ha una propria memoria virtuale. Se il dato che cerca si trova in realtà sulla RAM di un altro computer, il sistema operativo blocca tutto, va a prenderlo via rete, lo porta lì e riparte.
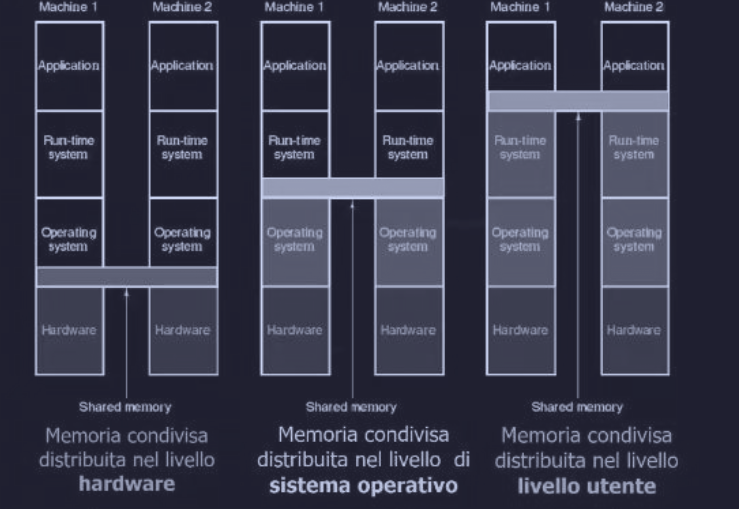
La memoria condivisa distribuita può essere collocata a diversi livello dello stack :
Scheduling sui multicomputer
In un multiprocessore tutti i processi risiedono nella stessa memoria. Quindi quando una CPU finisce il suo task corrente, seleziona un processo e lo esegue: in linea di principio, tutti i processi sono potenzialmente candidati.
Ma su un multicomputer ogni nodo ha una propria memoria e un proprio insieme di processi, quindi la CPU 1 non può improvvisamente decidere di eseguire un processo che si trova sul nodo 4 senza prima fare una certa quantità di lavoro per acquisirlo. Quindi lo scheduling su un multicomputer è simile a quello su un multiprocessore, ma non tutti gli algoritmi per i multiprocessori sono applicabili ai multicomputer.
L’algoritmo più semplice usato per i multiprocessori è quello di mantenere una sola lista centralizzata dei processi pronti, questo non funziona sui multicomputer, siccome ciascun processo si può eseguire solo sulla CPU dove si trova correntemente, e quando si crea un nuovo processo, è possibile scegliere dove metterlo, ad esempio per bilanciare il carico.
Bilanciamento del carico
Una volta che un processo è stato assegnato ad un nodo, funziona qualsiasi algoritmo di scheduling locale (anche il gang scheduling può essere utilizzato).
La scelta di quale processo assegnare ad un nodo è importante, e gli algoritmi per l'assegnazione di un processo al nodo sono conosciuti come gli algoritmi di allocazione dei processi, che differiscono per i requisiti (CPU, memoria, traffico dati, …) e per l’obiettivo.