Abbiamo visto come possiamo introdurre il parallelismo nel chip. Il passo successivo è la combinazione di più CPU per formare sistemi più grandi ovvero un parallelismo a livello di sistema, che si dividono in due categorie:
- multiprocessori : presenza di una memoria condivisa
- multicomputer : assenza di una memoria condivisa
Questi sistemi sono MIMD (Multiple Instruction, Multiple Data), ovvero dove abbiamo più processori autonomi che lavorano indipendentemente (ognuno esegue le sue istruzioni e i suoi dati). Inoltre la comunicazione avviene tramite lo scambio di messaggi, quindi le principali differenze tra MIMD risiedono nella base del tempo, nella scala delle distanze e nell’organizzazione logica utilizzata.
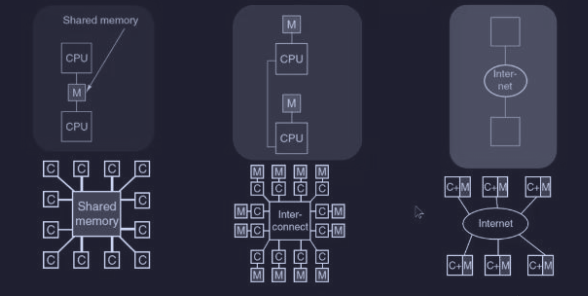
Dove possiamo dire di più sulle tre architetture mostrate :
- multiprocessori a memoria condivisa :
- meno di 1000 CPU
- comunicano con una memoria condivisa
- tempo di accesso ad una word è in media di 2-10 ns
- multicomputer a scambio di messaggi : con tempi di invio di 10-50 µs
- sistemi distribuiti : con tempi di latenza di 10-100 ns
Multiprocessori
Un multiprocessore a memoria condivisa (o semplicemente multiprocessore) è un calcolatore in cui tutte le CPU condividono una memoria comune.
Una proprietà (ovvia) che ha un multiprocessore è che una CPU può scrivere una word in memoria e trovarvi una word diversa nella successiva lettura, siccome un’altra CPU può averla modificata. Inoltre i OS utilizzati nei sistemi multiprocessori sono normali OS.
Esistono due differenti tipologie di multiprocessori :
- UMA - Uniform Memory Access : dove ogni parola di memoria può essere letta alla stessa velocità
- NUMA - Nonuniform Memory Access : dove NON tutte le parole di memoria possono essere lette alla stessa velocità
Multiprocessori UMA
UMA con architettura basata sul bus
I multiprocessori più semplici si basano su un singolo bus che connette tra di loro tutte le CPU alla memoria condivisa.
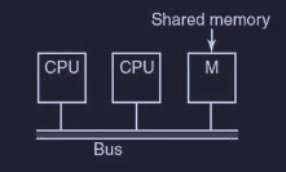
Quando una CPU vuole leggere una parola dalla memoria, deve prima verificare che il bus sia libero, e poi (se libero) inserire nel bus l’indirizzo della parola voluta, mentre se il bus è occupato deve aspettare che si liberi. Se le CPU sono due o tre, la contesa del bus è ancora gestibile, mentre se sono di più, diventa intrattabile il sistema, siccome bisogna aggiungere una cache ad ogni CPU.
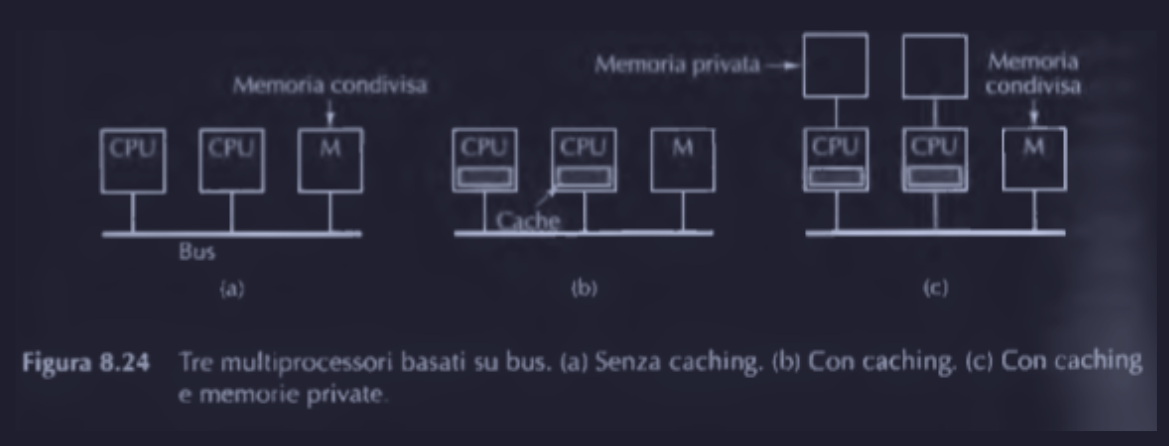
Caching nelle CPU
Il caching in questo caso non viene eseguito sulle singole parole di memoria, ma su blocchi di 32 o 64 byte. Quindi quando una parola è referenziata (cercata), l’intero blocco che la contiene (linea di cache) è caricato nella CPU che l’ha richiesta.
Inoltre ogni blocco di cache è contrassegnato come READ-ONLY oppure READ/WRITE.
Quando una CPU scrive una parola che è contenuta anche in altri blocchi di cache remote, l’hardware del bus rileva la scrittura e lo “segnala” alle altre cache, che possono avere :
- una copia “pulita” del blocco di memoria, quindi la cache la sovrascrive con il valore aggiornato
- una copia “sporca” (modificata) del blocco di memoria, quindi la cache deve prima trascrivere in memoria e poi applicare la modifica
L’insieme di tali regole che gestiscono le cache è chiamato protocollo di coerenza della cache.
CPU dotate di RAM
Una possibile alternativa è l’aggiunta di memorie RAM in un bus interno dedicato per ogni CPU.
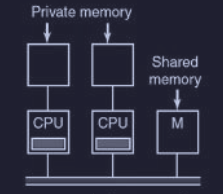
In questo caso la memoria condivisa (shared memory) è utilizzata esclusivamente per scrivere variabili condivise (globali).
Questa soluzione riduce il traffico sul bus ma richiede una collaborazione attiva del compilatore che deve separare gli oggetti locali (programma, stack, variabili locali …) dagli oggetti globali.
UMA con crossbar switch
Con la presenza di un solo bus, si ha un limite al parallelismo dei multiprocessori UMA a circa 16 o 32 CPU. Per superare questo valore è necessario cambiare tipo di interconnessione tra le CPU. Il circuito più semplice che collega CPU a memorie condivise è il crossbar switch :
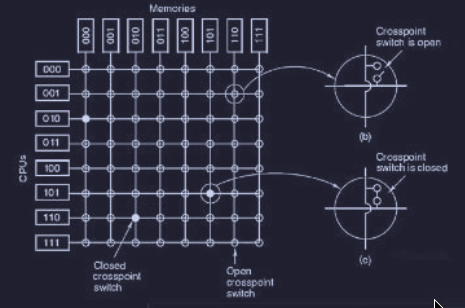
dove ad ogni “incrocio” c’è un crosspoint, che è esso stesso uno switch che può essere aperto o chiuso (elettronicamente) a seconda se si voglia collegare o meno le linee corrispondenti.
Con questo sistema si realizza una rete non bloccante, ovvero che non succede mai che ad una CPU venga negata la connessione di cui ha bisogno per una linea occupata.
Inoltre non c'è bisogno di alcuna pianificazione iniziale, infatti se sono già state stabilite sette connessioni, è sempre possibile collegare un’ottava CPU a una nuova memoria.
Rimane solo il problema nel caso due o più CPU vogliano accedere allo stesso modulo contemporaneamente. Inoltre una delle peggiori caratteristiche è che il numero dei crosspoint (switch) cresce come , infatti se abbiamo 1000 CPU e 1000 moduli di memoria, occorrono un milione di crosspoint (roba non fattibile).
UMA con rete di commutazione (switch) multilivello (a più stadi)
Una progettazione di multiprocessori completamente differente è basato su switch (2 input e 2 output).
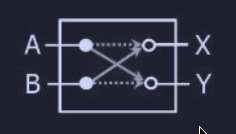
Questo switch ha 2 ingressi e 2 uscite, infatti i messaggi che arrivano da ognuno dei due input possono essere indirizzati verso ognuna delle due uscite.
Mentre ogni messaggio contiene :
- modulo : specifica la memoria da usare
- indirizzo : specifica un indirizzo all’interno di quel modulo
- opcode : stabilisce il tipo di operazione (
READ/WRITE) - valore : valore di un operando Lo switch quindi utilizza il campo modulo per scegliere dove spedire il messaggio se X o Y.
Gli switch possono essere organizzati in vari modi per costruire una più grande rete a commutazione multilivello (o a più stadi).
Una rete economica e semplice è la rete omega :
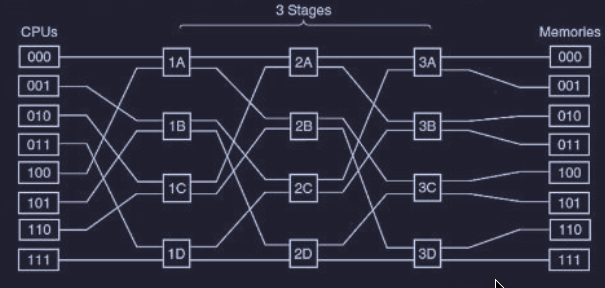
^uma-omega
In questa rete sono state collegate 8 CPU ad 8 memorie utilizzato 12 switch.
Infatti dobbiamo considerare che :
- per CPU e memorie sono necessari stadi (o stage)
- se ogni stage necessita di switch
- abbiamo un totale di switch, che risulta molto meglio di crosspoint
Spesso ci si riferisce alla struttura dei collegamenti di queste reti con il termine di perfect shuffle (mescolamento perfetto).
Per capire il funzionamento di una rete omega, supponiamo che la CPU numero 3 (011) voglia leggere una parola dalla memoria 6 (110), quindi la sequenza sarà la seguente mostrata con le frecce :
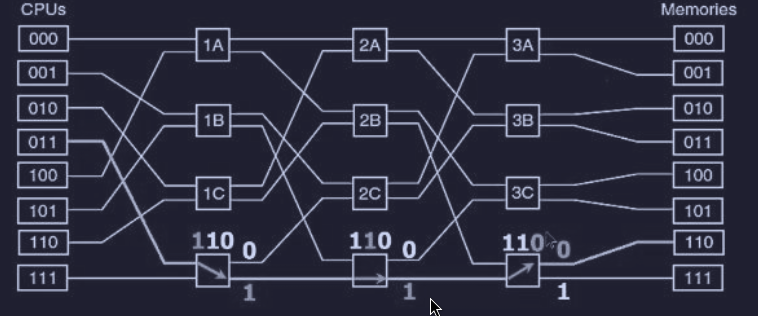
A differenza dell’interconnessione con crossbar switch, la rete omega è una rete bloccante, infatti non è possibile elaborare contemporaneamente qualsiasi insieme di richieste. Quindi è vantaggioso se ci fosse una distribuzione dei riferimenti alla memoria in modo uniforme rispetto ai moduli. Infatti una tecnica comune è quella di utilizzare i bit meno significati come numero di modulo.
Inoltre un sistema di memoria in cui le parole consecutive sono i moduli diversi è detto interleaved.
È sempre possibile reti di commutazione non bloccanti e che offrono cammini multipli da ogni CPU ad ogni modulo di memoria, per distribuire il traffico di rete.
Multiprocessori NUMA
L’architettura NUMA è una tipologia di multiprocessore introdotta per connettere un numero di CPU superiore al limite dei sistemi UMA, accettando però il compromesso che i tempi di accesso alla memoria non siano più uniformi, infatti nei multiprocessori NUMA ogni processore ha una sua memoria privata vicina veloce, mentre per leggere la memoria degli altri processori (memoria remota) ci si impiega più tempo.
Inoltre tutti i programmi che girano su multiprocessori UMA continuano a girare sulle macchina NUMA, ma naturalmente hanno performance degradate.
^numa-car Le macchine NUMA hanno tre caratteristiche chiavi :
- esiste un solo spazio di indirizzamento visibile a tutte le CPU
- l’accesso alla memoria remota si fa attraverso istruzioni
LOADeSTORE - l’accesso alla memoria remota è più lento dell’accesso alla memoria locale
Inoltre ci sono due tipologie di macchine NUMA :
- no-cache o NC-NUMA (No Cache NUMA) : se al processore serve un dato che si trova nella memoria di un altro processore lontano, deve andarlo a prendere ogni singola volta
- cache-coherent o CC-NUMA (Cache-Coherent NUMA) : quando il processore va a prendere un dato lontano, se ne salva una copia nella sua cache locale. La volta successiva che gli serve, lo trova già lì, velocissimo
CC-NUMA
L’approccio utilizzato di più per costruire grandi multiprocessori CC-NUMA è il multiprocessore basato sulle directory - directory-based multiprocessor.
Il concetto di directory-based semplifica molto il sistema a snooping, infatti quando ad un processore serve un dato non disturba tutti gli altri chiedendo se ce l’hanno, ma interroga questo registro speciale (directory o db) che sa esattamente :
- dove si trova il dato (in quale processore)
- “come” sta messo quel dato, ovvero se è aggiornato o se qualcuno lo ha modificato Siccome questa verifica va fatta ad ogni singola istruzione di memoria, questo “registro” è un circuito hardware velocissimo (non software).
L’unione di tutte le memoria dei nodi forma l’intero spazio di indirizzamento.
Tipi di OS multiprocessore
^approcci-os Ci sono tre differenti approcci per gli OS multiprocessori :
- ogni CPU ha un proprio OS
- multiprocessori master-slave
- multiprocessori simmetrici
Ogni CPU ha un proprio OS
Immaginiamo di prendere la memoria RAM del computer e tagliarla a fette fisse, come una torta. Assegniamo la prima fetta alla CPU 1, la seconda alla CPU 2, e così via. Ogni CPU accende il suo “personale” OS dentro la sua fetta di memoria.
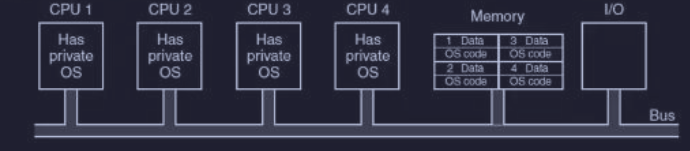
Per non sprecare memoria duplicando lo stesso codice del OS, si può tenere una sola copia del codice in un’area comune.
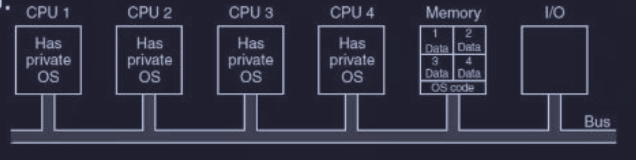
Questo modello però presenta delle problematiche :
- “burocrazia” locale: quando un programma chiede qualcosa al sistema (system call), se la vede solo con la CPU su cui sta girando. Non c’è una visione d’insieme
- non c’è condivisione dei processi, ogni CPU gestisce da sola i propri processi. Quindi non è possibile bilanciare il carico tra CPU (una potrebbe essere scarica e un altra super carica di lavoro)
- se una CPU finisce la sua porzione di RAM, inizia a usare il disco fisso (swap), che è lentissimo. Questo accade anche se la CPU vicina ha gigabyte di RAM vuota, perché non può “prestarla”
- se la CPU A modifica un file ma lo tiene nella sua memoria temporanea (buffer), e la CPU B prova a leggere quel file, la CPU B potrebbe leggere la versione vecchia. Questo crea errori nei dati (letture inconsistenti)
Multiprocessori master-slave
In questo modello si introduce una gerarchia rigida per risolvere il caos del modello precedente (“ogni CPU per sé”). C’è un master (capo) e ci sono dei slave , dove :
- master : è l’unico che ha il potere di toccare la memoria centrale, gestire l’input/output e decidere chi fa cosa
- slave : eseguono solo i calcoli dei programmi (processi utente). Se hanno bisogno di qualcosa (es. leggere un file, allocare memoria), devono fermarsi e chiedere il permesso al master (system call)
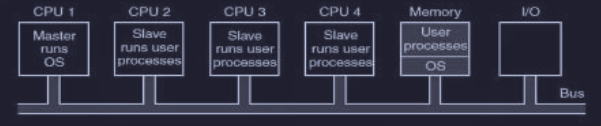
Questo risolve i problemi di incoerenza del modello precedente, siccome essendoci un solo “capo” che tiene la lista dei lavori, non c’è rischio che due CPU cerchino di fare la stessa cosa o che una stia ferma mentre l’altra lavora troppo. Infatti il master può distribuire il carico equamente.
Il problema è che se ci sono troppi slave che chiedono cose continuamente, il master non riesce a star dietro a tutte le richieste e diventa un imbuto (collo di bottiglia), rallentando tutto il sistema. Per questo motivo, questo modello funziona bene solo se le CPU sono poche.
Multiprocessori simmetrici
Il multiprocessore simmetrico (SMP) elimina l’asimmetria del modello master-slave, infatti in questo modello ogni CPU può diventare master.
In questo modello :
- una copia del OS è in memoria e ciascuna CPU può eseguirla
- quando si fa una system call, la CPU che riceve la chiamata esegue una trap nel kernel e processa la richiesta
In questo modo i processi e la memoria sono bilanciati automaticamente.
Viene eliminato il collo di bottiglia dell’altro modello, ma ci sono altri problemi :
- sincronizzazione delle CPU dovuta alla condivisione del OS
- bisogna evitare i deadlock, siccome potrebbe essere impossibile risolverli
- la gestione è critica perché dipende dall’esperienza del programmatore nel contesto del sistema
Sincronizzazione dei multiprocessori
Le CPU in un multiprocessore hanno bisogno di sincronizzarsi, infatti le regioni critiche (risorse) del kernel e le tabelle devono essere protette da mutex.
Infatti se si disabilitano gli interrupt di una CPU, le altre continuano a funzionare normalmente e possono accedere ad una regione critica (risorsa).
Abbiamo visto nei “mono”-processori che l’istruzione TSL (Test Set Lock) impiegata nei mutex, permetteva ad una parola di memoria di essere controllata e impostata in modo atomico.
Ora con più CPU, l’istruzione
TSLdove prima bloccare il bus evitando l’accesso di altre CPU, poi accedere alla memoria e infine sbloccare il bus.
Se la TSL è realizzata efficientemente ci sono tre possibili strade per la CPU che fa la richiesta del bus :
- spin lock : verifica la disponibilità in un ciclo rapidissimo, in modo da non rallentare le altre CPU
- switch dei processi : invece di restare li a girare (spinning), la CPU lascia perdere l’attesa e passa il controllo ad un altro processo
- approccio ibrido : non esiste una soluzione ideale, un approccio ibrido potrebbe essere :
- di attendere per un certo tempo e poi fare uno switch di processo
- memorizzare i tempi medi di attesa e vedere se il tempo attuale rispetta i tempi medi (memorizzati) o è fuori norma
Scheduling dei multiprocessori
Vediamo come si presenta lo scheduling nei due mondi :
- mondo mono-processore (Mono-dimensionale): Qui la vita è semplice. Hai un solo “motore” (CPU). L’unica domanda che il sistema deve farsi è temporale: “Chi è il prossimo?” (“Qual è il prossimo thread da mandare in esecuzione?”)
- mondo multiprocessore (Bi-dimensionale): Qui la faccenda si complica perché hai più motori. Non basta decidere “Chi è il prossimo?”, ma devi decidere anche “Dove lo metto?” (“su quale CPU”). Inoltre, c’è un fattore di complicazione:
- i thread (i pezzetti di programma) non sono tutti uguali.
- in alcuni sistemi sono solitari (non correlati)
- in altri sono “amici” che lavorano in gruppo e vorrebbero stare vicini o essere eseguiti insieme
Per risolvere i problemi nel mondo dei multiprocessori, esistono vari algoritmi di scheduling per ciascuna situazione (thread singoli o gruppi) :
- timesharing
- space sharing
- gang sharing
Timesharing
Lo scheduling a condivisone di tempo (timesharing) è utilizzato quando i thread sono indipendenti.
Il sistema crea una “classifica” unica centrale (vettore), dove i thread sono messi in fila in base alla loro importanza (priorità). Tutte le CPU attingono da questa unica fonte centrale. Quando una CPU si libera, guarda il vettore, prende il compito più importante disponibile e lo esegue. Grazie a questa struttura dati unica, il carico di lavoro (e il tempo) si distribuisce automaticamente tra tutte le CPU disponibili (come in un sistema mono-processore).
^prob-time-sharing Ma presenta 2 problematiche principali:
- Le dispute per l’accesso alla struttura dati di scheduling con il crescere delle CPU
- Il normale sovraccarico che si presenta per fare il cambio di contesto quando un processo si blocca per l’I/O
Smart scheduling
Supponiamo che un thread stia usando una risorsa condivisa (ha lo spin lock). Proprio mentre ha il lock, scade la sua quantum e si viene messo in pausa. In questo modo si porta il lock in pausa e tutte le altre CPU che aspettavano quel lock rimangono bloccate inutilmente finché quel thread non si risvegli. In alcuni sistemi quando questo accade, il thread in questione che ha il lock, se gli finisce la quantum attiva un flag speciale che permette allo scheduler di “regalargli” un tempo extra per finire quello che stava facendo e rilasciare il lock - smart scheduling.
Affinity scheduling
Un altro problema è che spostare un thread da una CPU ad un altra è pesante e ha un costo, per questo alcuni multiprocessori utilizzano la tecnica affinity scheduling, ovvero cercano di far eseguire lo stesso thread sempre nella stessa CPU. Infatti la CPU potrebbe avere nella propria cache dei blocchi già caricati e questo migliora di molto le performance (invece di spostare che pesa).
Per creare questa affinità si utilizza un algoritmo di schedulazione a due livelli :
- top-level scheduling : quando è creato un nuovo thread viene assegnato alla CPU meno carica
- bottom-level scheduling : il reale scheduling è fatto internamente in ogni CPU, dove ognuna deve gestire i suoi thread, in questo modo se una CPU tende a “ripescare” i suoi thread, i dati di quel thread saranno nella cache (affinità)
Questo scheduling presenta vari vantaggi:
- distribuzione del carico tra le CPU in modo equo
- prestazioni migliori con l’affinità della cache
- “dispute” tra CPU sono minimizzate siccome ognuna guarda la sua propria lista privata di thread
Space sharing
Se esiste una correlazione tra i thread si può utilizzare lo scheduling a condivisione di spazio (space sharing). Infatti lo scheduling di molti thread nello stesso momento su più CPU è chiamata space sharing scheduling.
Il funzionamento segue una logica rigida del tipo “tutto o niente”. Infatti quando bisogna avviare un gruppo di thread, lo scheduler conta quanti sono e controlla se ci sono abbastanza CPU libere per ospitarli tutti contemporaneamente.
- se ci sono abbastanza posti liberi, ogni thread riceve la sua CPU personale e il gruppo parte
- se non ci sono abbastanza posti per tutti, nessuno parte e quindi l’intero gruppo rimane in attesa finché non si liberano abbastanza CPU per soddisfare tutti
Inoltre ad ogni istante di tempo, l’insieme delle CPU è partizionato staticamente, dove ciascuna partizione esegue il gruppo di thread a loro assegnati (o niente) :
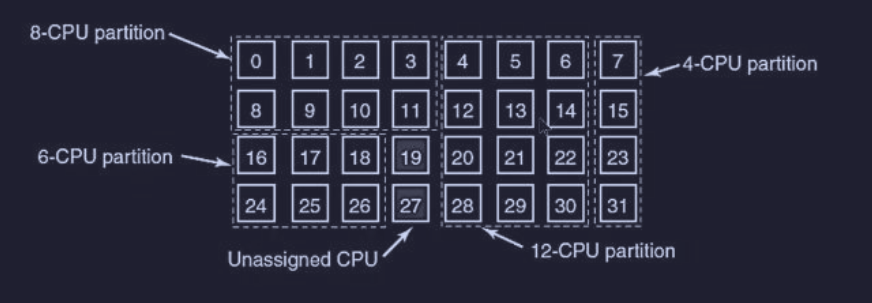
Vantaggio :
- lo space sharing elimina la “multiprogrammazione”, infatti siccome ogni gruppo ha le sue CPU dedicate, non c’è bisogno di salvare e caricare continuamente processi diversi. Questo elimina il costo temporale (overhead) dovuto agli scambi di contesto Svantaggio :
- se una CPU assegnata a un gruppo si blocca (perché “non c’è nulla da fare” in quel momento), quel tempo viene completamente sprecato
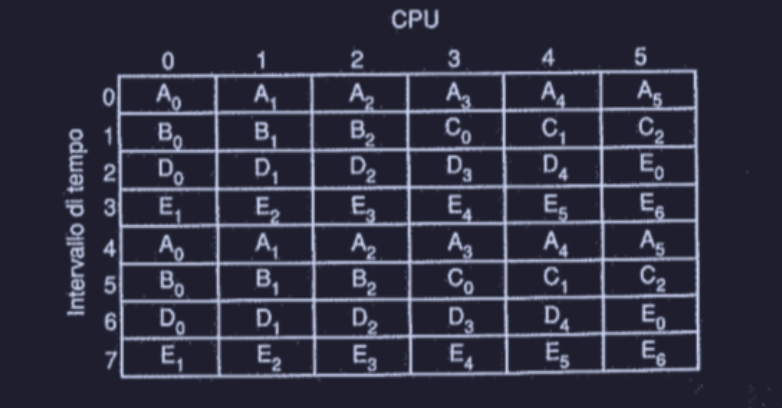
Gang scheduling
Riprendendo lo svantaggio dello space sharing, per risolvere questo spreco, si sono cercati algoritmi che unissero i due mondi di tempo e spazio. Infatti il gang scheduling si compone di tre passaggi :
- prende un gruppo di thread (correlati) e li tratta come un blocco unico (unica gang o squadra)
- ai membri della gang viene dato un intervallo di tempo per l’utilizzo delle CPU (come nel timesharing) ma con la regola del “tutti o niente” (space sharing)
- quando tocca alla gang, tutti i membri iniziamo contemporaneamente, e quando il tempo finisce vengono rimossi tutti insieme
- all’inizio di ciascun nuovo quantum (intervallo di tempo) tutte le CPU sono ri-schedulate.
- se un thread si blocca, la sua CPU rimane inattiva fino allo scadere del quantum