
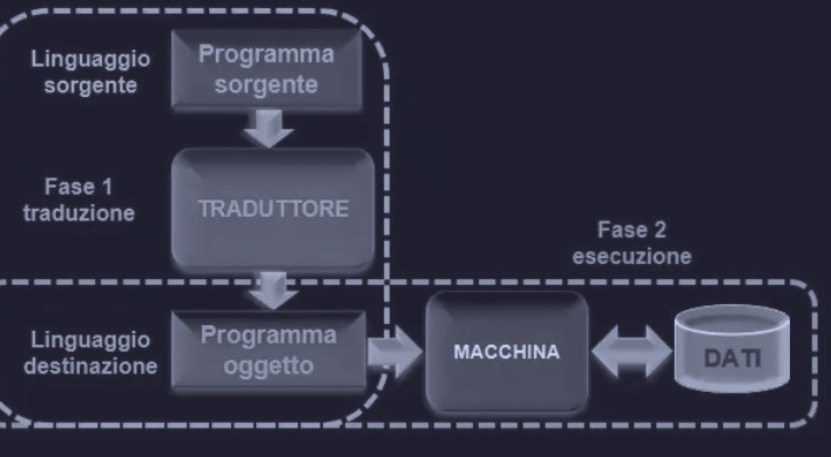
Mentre il livelli di microarchitettura, di macroarchitettura ( ISA ) e del sistema operativo, sono livelli interpretati, il livello del linguaggio assemblativo è realizzato mediante traduzione. Il programma che si occupa di tradurre un programma scritto dall’utente ( linguaggio sorgente - in assembly ) in un particolare linguaggio ( linguaggio destinazione ).
Important
Ricordiamo che nella traduzione il programma originale non viene eseguito direttamente ( a differenza dell’interpretazione ), ma viene convertito in un programma oggetto ( o eseguibile binario ). Infatti nella traduzione ci sono 2 passi da seguire :
- generazione del programma oggetto
- esecuzione del programma oggetto
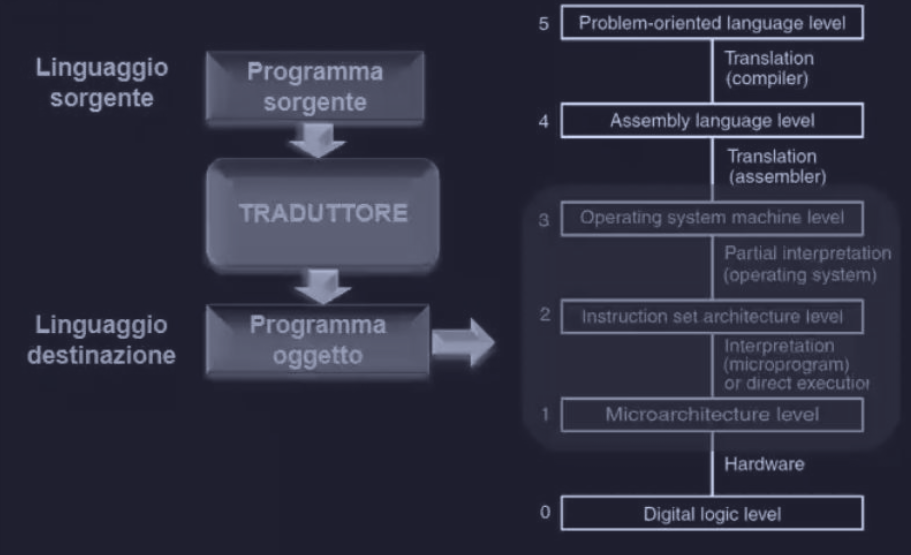
Mentre si esegue il programma oggetto sono coinvolti solamente 3 livelli :
- microarchitettura
- ISA
- macchina del sistema operativo
Inoltre in base al linguaggio sorgente e destinazione, i traduttori si possono dividere in due gruppi :
- assemblatori : dove il linguaggio sorgente è una rappresentazione simbolica di un linguaggio macchina numerico ( linguaggio assemblativo )
- compilatore : dove il linguaggio sorgente è un linguaggio ad alto livello ( es. C o Java ) e il linguaggio destinazione è un linguaggio macchina o un linguaggio assemblativo

Linguaggio assemblativo
Un puro linguaggio assemblativo è un linguaggio dove ciascuna istruzione produce esattamente un’istruzione macchina, ovvero che esiste una corrispondenza one-to-one tra le istruzioni del programma assemblativo e le istruzioni macchina.
Siccome programmare in linguaggio macchina è molto difficile per l’essere umano, siccome è rappresentato in binario o in hex, allora si utilizza il linguaggio assemblativo che è una rappresentazione simbolica ( ADD, SUB, MUL … ). Sarà infatti compito dell’assemblatore tradurre i simboli in istruzioni macchina.
Un’altra caratteristica del linguaggio assemblativo, è che il programmatore ha accesso a tutte le funzionalità e a tutte le istruzioni disponibili nella macchina di destinazione ( es. può lavorare con i registri ) ( il C è trasversale, ovvero che è ad alto livello ma ha delle funzionalità del linguaggio assemblativo ).
Inoltre i programmi in linguaggio assemblativo sono scritti per una specifica famiglia di macchine, mentre i programmi in linguaggio ad alto livello può essere eseguito su molte macchine diverse - machine independent.
Perché programmare in assembly ?
Programmare in assembly è molto più difficile che programmare con un linguaggio ad alto livello. Ma esistono 2 motivi per cui ne vale la pena :
- prestazioni
- possibilità di accesso alla macchina : alcune procedure permettono di accedere in modo completo all’hardware ( non esiste alternativa )
Infatti per alcuni tipi di applicazioni la velocità e la dimensione rappresentano due fattori critici ( es. driver dei dispositivi ).
Formato delle istruzioni del linguaggio assemblativo
La struttura delle istruzioni di un linguaggio assemblativo rispecchia quella delle istruzioni macchina. Vediamo per esempio alcuni frammenti di codice assembly per x86, che esegue l’istruzione :
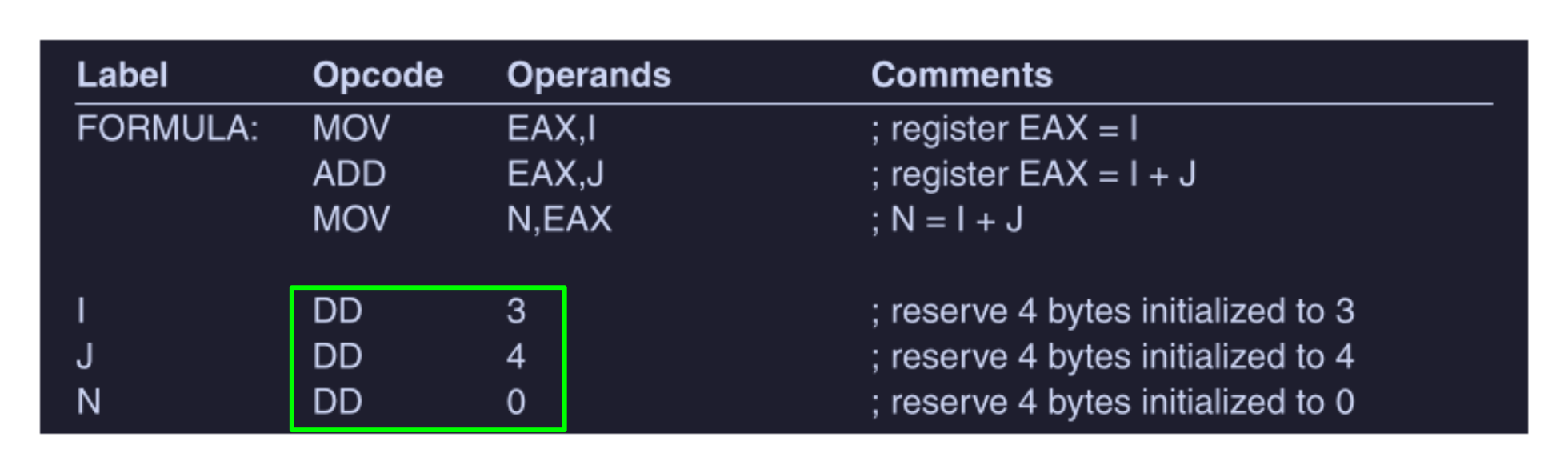
Le istruzioni ( non in verde ) eseguono la computazione, mentre il comando DD ( Define Double ) ( in verde ) indica di riservare spazio in memoria per le variabili e ( non è una istruzione macchina, ma è un comando per l’assemblatore - pseudoistruzione ).
Quindi le istruzioni assembly sono composte da 4 campi :
- label ( etichetta ) : nomi simbolici agli indirizzi ( utilizzata poi dalle istruzioni di salto )
- operazione ( opcode )
- operandi
- commenti
Pseudo-istruzioni
In assembly, oltre a trovare le istruzioni macchina che devono essere eseguite, possiamo trovare anche dei comandi diretti per l'assemblatore ( e non per la CPU ). Questi comandi sono chiamati pseudoistruzioni o direttive dell'assemblatore.
Vediamo alcune pseudoistruzioni dell’assemblatore Microsoft MASM per x86 :
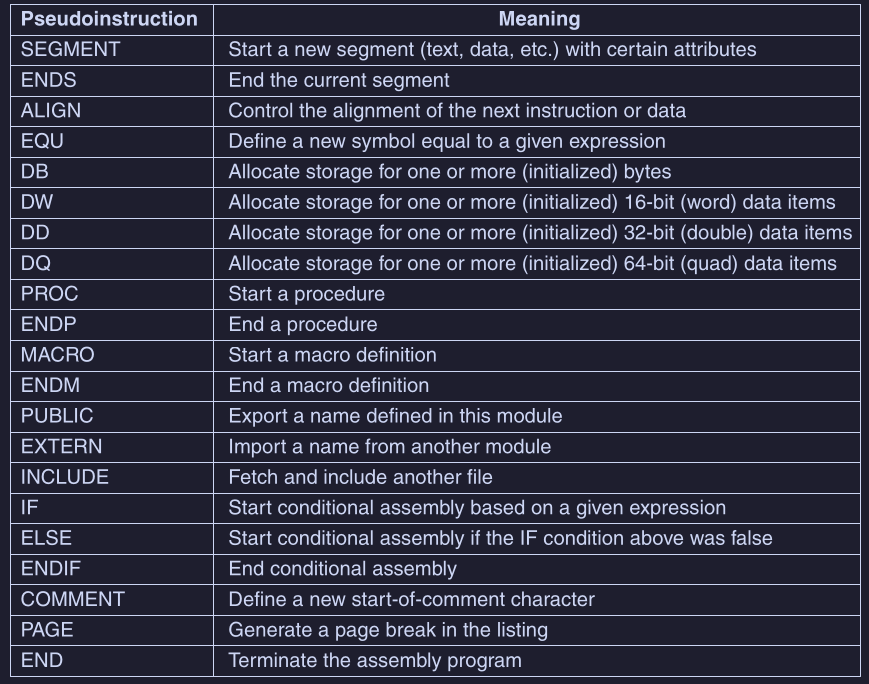
Infatti con SEGMENT è possibile iniziare un nuovo segmento, che può contenere testo, codice o dati; mentre con ENDS lo si termina.
Inoltre per esempio con :
EQUpossiamo definire un nome simbolico a un’espressione :
PI EQU 3.14159 DBpossiamo allocare spazio per 1 byte :
TABLE DB 11,23,49 // alloca spazio per 3 byte, inoltre ora TABLE -> 11 (punta)DWpossiamo allocare spazio per 2 byte ( 16-bit ) :
VALUES DW 2000,1000,3000 // 3 numeri da 2 byte ciascunoPossiamo inoltre in MASM utilizzare l’assemblaggio condizionale, per esempio :
WORDSIZE EQU 32
IF WORDSIZE GT 32
WSIZE: DD 64
ELSE
WSIZE: DD 32
ENDIFche in pratica alloca 32 bit per una word e chiama WSIZE il suo indirizzo.