
La maggior parte dei programmi è composta da più di una procedura ( anche sparse in più file ). Generalmente i compilatori e gli assemblatori traducono una procedura alla volta e memorizzano il risultato della traduzione su disco. Prima che il programma possa essere eseguito è necessario :
- recuperare tutte le procedure e collegarle tra di loro in modo appropriato ( linking ), attraverso il linker
- in assenza di memoria virtuale, occorre caricare in memoria centrale il programma ottenuto dal collegamento delle procedure, attraverso il loader
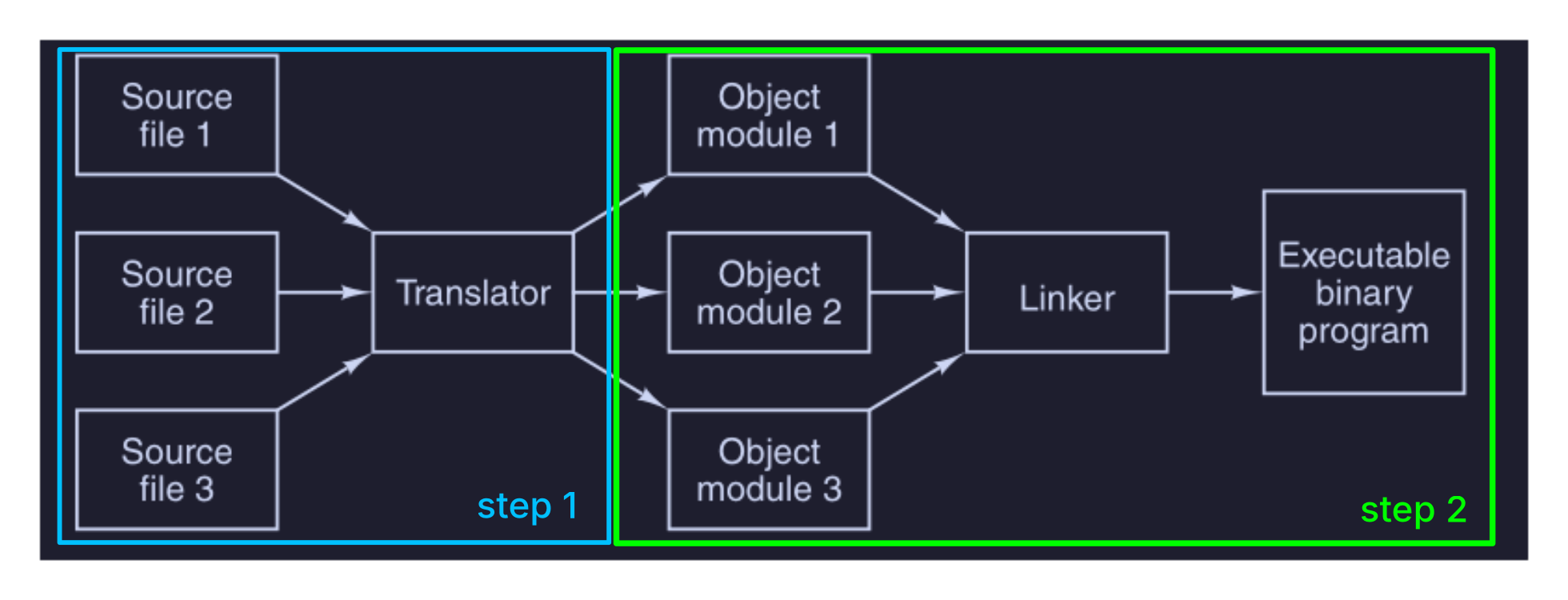
Quindi la traduzione completa di un programma sorgente richiede 2 passi :
- compilazione o assemblaggio dei file sorgente - step 1
- collegamento dei moduli oggetto - step 2
Info
Ricordiamo che per “oggetto” sta per risultato dell’assemblaggio. Infatti il modulo oggetto è il risultato della compilazione/assemblaggio di un singolo file sorgente, che può contenere riferimento non risolti, per questo abbiamo bisogno di collegarli tra di loro. In Windows i file oggetto hanno estensione
.objmentre gli eseguibili hanno estensione.exe. In UNIX abbiamo.oper i file oggetto e nessuna estensione per gli eseguibili.
Quindi la funzione del linker è quella di unire le procedure tradotte separatamente e di collegarle tra di loro in modo da poterle eseguire come un’unica unità chiamata programma eseguibile binario.
Struttura di un modulo oggetto
Spesso i moduli oggetto sono composti da 6 parti :
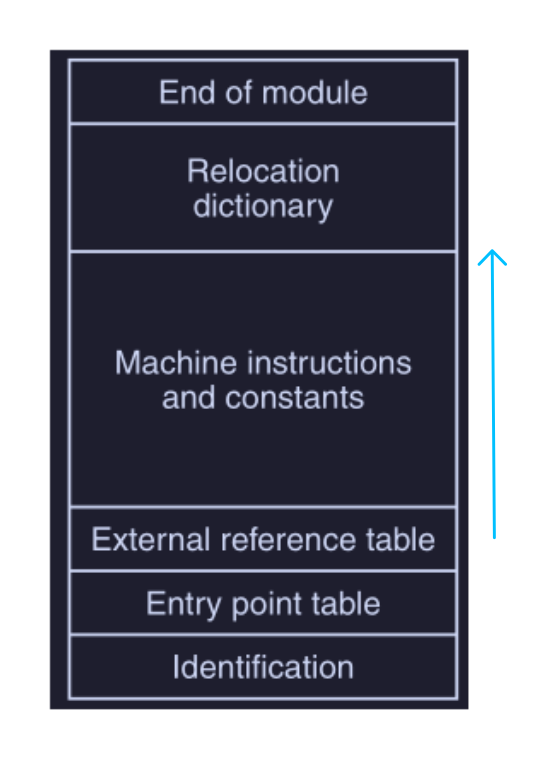
dove ( seguendo la direzione della freccia in blu ):
- identificativo : contiene il nome del modulo e informazioni utili al linker ( lunghezze delle singole parti del modulo )
- tabella entry point : contiene una lista di simboli definiti all'interno del modulo al quale possono fare riferimento altri moduli ( pseudoistruzione/direttiva
PUBLIC- viste in Introduzione al linguaggio assemblativo ) - tabella di riferimento external : contiene una lista di simboli utilizzati nel modulo, ma definiti in un altro ( direttiva
EXTERN) - istruzioni macchina e costanti : contiene il codice assemblativo e le costanti, ed è l’unica parte che viene caricata in memoria per essere eseguita
- dizionario di ri-locazione : fornisce gli indirizzi de dovranno essere ri-locati
- identificativo di fine modulo : contiene :
- indirizzo dal quale bisogna far partire l'esecuzione
- eventuale checksum per rilevare gli errori che possono avvenire durante le lettura del modulo
Ri-locazione a tempo del binding e dinamica
In un sistema multiprogrammato ( dove girano tanti programmi ), un programma può essere letto e portato nella memoria centrale, eseguito per un po’ e poi riportato su disco e poi riletto per essere eseguito un’altra volta.
Il problema è che risulta difficile in un sistema multiprogrammato, avere la certezza che il programma venga letto e caricato sempre nelle stesse locazioni.
Questo problema è connesso al momento in cui viene completato il collegamento finale tra i nomi simbolici e gli indirizzi assoluti della memoria fisica, ovvero tempo del binding ( tempo di collegamento ).
Consideriamo il seguente problema :
- Programma compilato per indirizzo 1000
- Se lo carichi a indirizzo 5000 → NON FUNZIONA
Una prima tecnica risolutiva è l’utilizzo della paginazione :
- Programma sempre compilato per indirizzo 1000
- Tabella delle pagine dice: "indirizzo virtuale 1000 → fisico 5000"
- FUNZIONA PERFETTAMENTE
Nella paginazione si crea una “mappa” ( tabelle delle pagine ) che traduce indirizzi virtuali in fisici.
Una seconda soluzione sarebbe di utilizzare un registro di ri-locazione :
- registro hardware che contiene l’indirizzo base (di quanto spostare il programma)
- tutti gli indirizzi vengono automaticamente aggiustati, infatti la CPU aggiunge automaticamente un offset
- svantaggio: Il programma deve stare tutto insieme, ovvero che tutto il programma deve stare contiguo, in un solo blocco
Una terza soluzione sarebbe di utilizzare gli indirizzi relativi :
- invece di “vai all’indirizzo 100”
- il programma dice “vai 20 posizioni dopo dove siamo ora”
- vantaggio: Il programma funziona ovunque
Gli indirizzi relativi rendono il codice indipendente dalla posizione, ma non risolvono il problema della ri-locazione dei dati; il registro di ri-locazione invece corregge automaticamente tutti gli riferimenti alla memoria.
Dynamic linking - collegamento dinamico :luc_link:
Molti programmatori hanno a disposizione funzioni che usano raramente, ma allora perché caricare anche quelle? Infatti nel collegamento dinamico :
- il programma inizia senza tutte le procedure (niente caricamento delle librerie all’inizio ma solo delle informazioni su dove trovarle etc)
- quando viene chiamata una procedura ancora non caricata in memoria, il sistema la carica al momento e la collega
In questo modo abbiamo alcuni vantaggi :
- risparmio di memoria
- programma parte subito senza caricare tutto
- aggiornamento di una procedura senza ricompilare tutto il programma
Il primo calcolatore che ha utilizzato questa tecnica è stato il MULTICS.
Collegamento dinamico in Windows e UNIX 🪟 🐧
Su Windows vengono utilizzate le DLL ( Dynamic Link Library ) che sono librerie a collegamento dinamico :
- una specie di scatola di strumenti condivise tra programmi
- contengono funzioni, procedure e dati
- non possono essere eseguite da sole, necessitano di un eseguibile di cui ne ha bisogno
Il sistema Unix ha un meccanismo simile alle DLL che si basa su quella che viene chiamata libreria condivisa. Una libreria condivisa è un file archivio che contiene procedure o moduli di dati presenti in memoria nel momento di esecuzione e può essere collegata contemporaneamente a più processi.
La libreria standard di C e gran parte del codice relativo alla comunicazione via rete sono esempi di librerie condivise.
In UNIX la libreria condivisa è composta da 2 parti :
- statica : ponte collegata nel programma che contiene informazioni su dove trovare la libreria condivisa
- destinazione : libreria vera e propria, contenuta in un file separato e chiamato in tempo di esecuzione