In questa sezione vedremo come funziona un assemblatore.
Assemblatori a due passate
Dato che ogni programma in assembly consiste in una serie d’istruzioni, un primo acchito sarebbe di avere un assemblatore che legge ogni istruzione, la traduce in linguaggio macchina e scrive su un file il codice generato ( oltre a creare un altro file con il listato ).
Però questo procedimento non funziona, infatti se consideriamo la seguente porzione di codice :
JMP L
.... // altre istruzioni
....
L: MOV EAX,5 // L è definita qui Infatti quando l’assemblatore legge L non sa a che indirizzo saltare perché L è definita dopo ( problema dei riferimenti in avanti ).
Per risolvere il problema dei riferimenti in avanti, ci sono 2 soluzioni :
- leggere il programma sorgente 2 volte, dove :
- ciascuna “lettura” è chiamata passata
- i traduttori che leggono 2 volte sono detti a due passate
- durante la prima passata questi assemblatori raccolgono in una tabella tutte le definizioni dei simboli e le label delle istruzioni, in questo modo prima della seconda passata si conosce tutto
- leggere il programma 1 volta, convertirlo in un formato intermedio e memorizzare in una tabella in memoria questa forma intermedia. Poi viene effettuata una seconda passata sulla tabella in memoria
In entrambi gli approcci la prima passata ha anche il compito di salvare le definizioni di macro e di espanderle quando si incontrano le loro chiamate.
Prima passata
Una principale funzione della prima passata è quella di costruire la tabella dei simboli, che contiene tutti i valori dei simboli ( es. se abbiamo BUFSIZE EQU 8192 memorizziamo che BUFSIZE = 8192 ).
Durante questa fase l’assemblatore utilizza una variabile ILC ( Instruction Location Counter ) per tenere traccia dell’indirizzo dell’istruzione che sta assemblando in quel momento.
All’inizio ILC è 0 poi viene incrementata della lunghezza dell’istruzione corrente, come mostra la figura di seguito :

in questo modo la tabella dei simboli sarà :
| Simbolo | Valore Indirizzo |
|---|---|
| MARIA | 100 |
| ROBERTA | 111 |
| MARILYN | 125 |
| STEPHANY | 129 |
Nella prima passata, la maggior parte degli assemblatori utilizza 3 tabelle interne :
- simboli
- pseudoistruzioni
- codici operativi
Seconda passata
Durante la seconda passata viene generato il programma oggetto e l'eventuale stampa del listato ( dove mostra tutto il processo ). Inoltre la seconda passata deve generare delle informazioni utili al linker per collegare in un unico file eseguibile le procedure assemblate in momenti diversi.
Le operazioni eseguite sono simili a quelle della prima passata, ovvero che le linee vengono anche qui lette ed elaborate una alla volta.
Tabella dei simboli
Come abbiamo già accennato, durante la prima passata l’assemblatore accumula informazioni sui simboli e i loro valori associati, nella tabella dei simboli, per poi essere utilizzata nella seconda passata.
Vediamo ora alcuni modi per organizzare questa tabella dei simboli, dove in tutti i modi si cerca di simulare una memoria associativa, ovvero un insieme di coppie <simbolo>,<valore>.
Esistono varie tecniche :
- implementare la tabella dei simboli come un vettore di coppie
(<simbolo>,<valore>)e quando si vuole recuperare un simbolo si cerca linearmente finché non si trova l’elemento desiderato. Questo metodo è facile ma lento ( ) - organizzare la tabella dei simboli in modo ordinato rispetto ai simboli, e di utilizzare un algoritmo di ricerca dicotomica ( binary search ) per cercare il simbolo desiderato. Abbastanza veloce ( ) ma va considerato che mantenere ordinata una struttura dati costa dal punto di vista computazionale
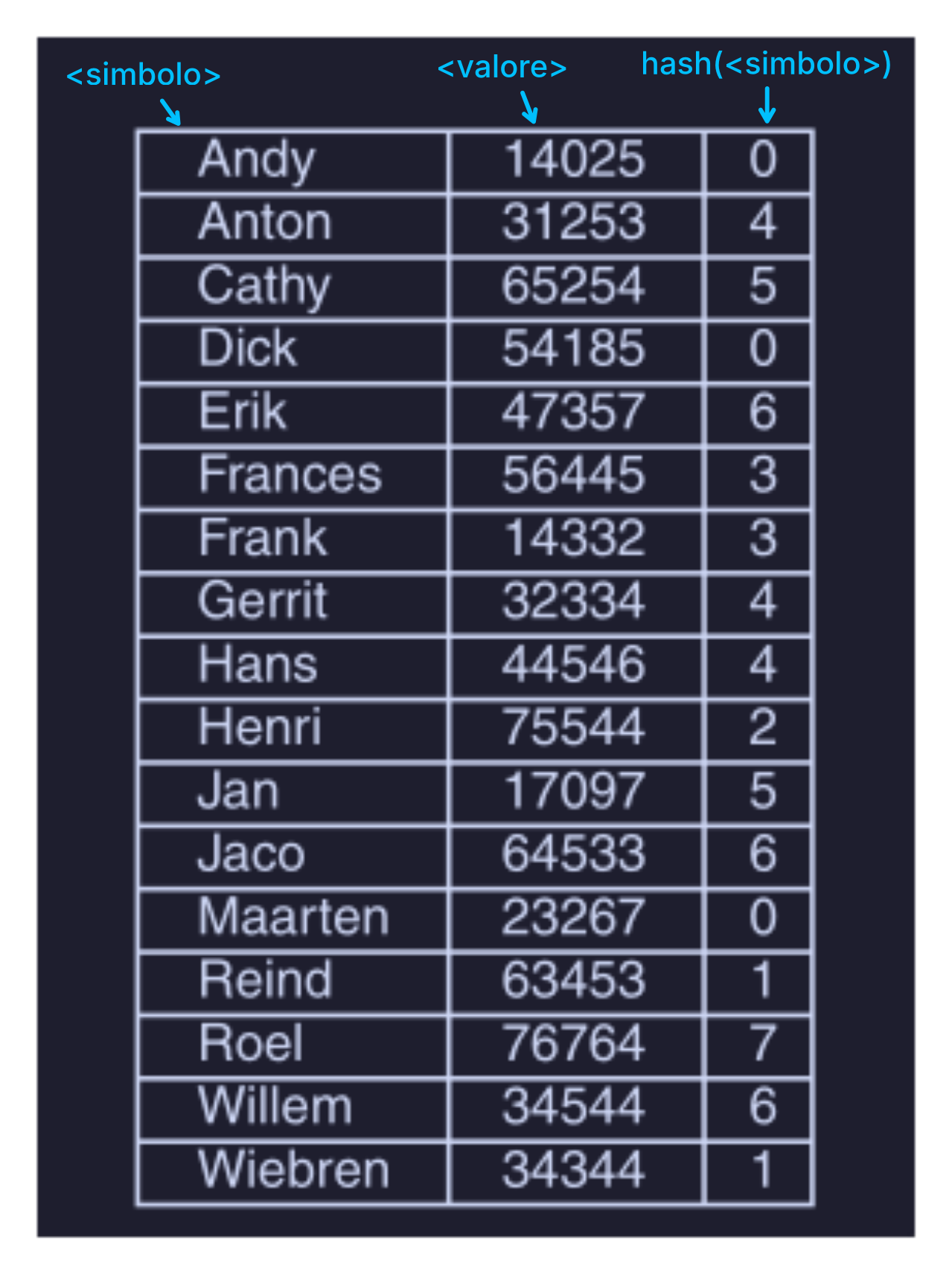
- utilizzo di una codifica hash ( hashing ), dove occorre definire una funzione “hash” che mappa un simbolo a un .
PS: La codifica hash la troviamo anche nel corso di programmazione dei calcolatori
Vediamo come funziona l’ultima tecnica ( hashing ) :
- abbiamo bisogno di una funzione di hashing, questa funzione può essere qualunque, basta che fornisca una distribuzione uniforme dei valori hash
- i simboli possono essere memorizzati in una tabella composta da bucket numerati da a
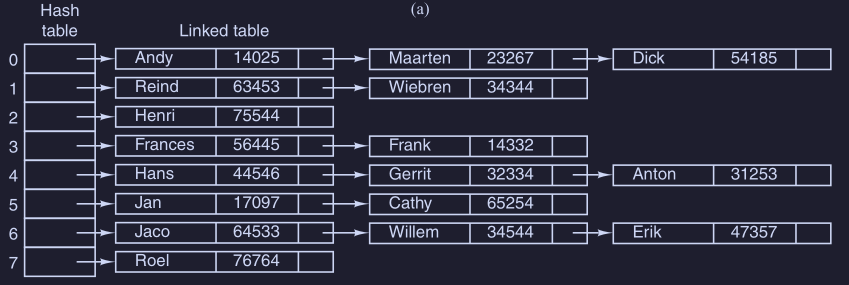
- ogni posizione della tabella hash punta ad una linked list ( lista concatenata )
- la linked list contiene le coppie
(<simbolo>,<valore>), il cui valore hash del<simbolo>vale . - con simboli e una tabella hash con posizioni, una linked list avrà come lunghezza media pari a
- la ricerca sarà costante
Vediamo ora un esempio :