
Il cervello del computer è la CPU (Central Processing Unit) e il suo compito è di eseguire i programmi contenuti nella Memoria-principale prelevando le loro istruzioni.
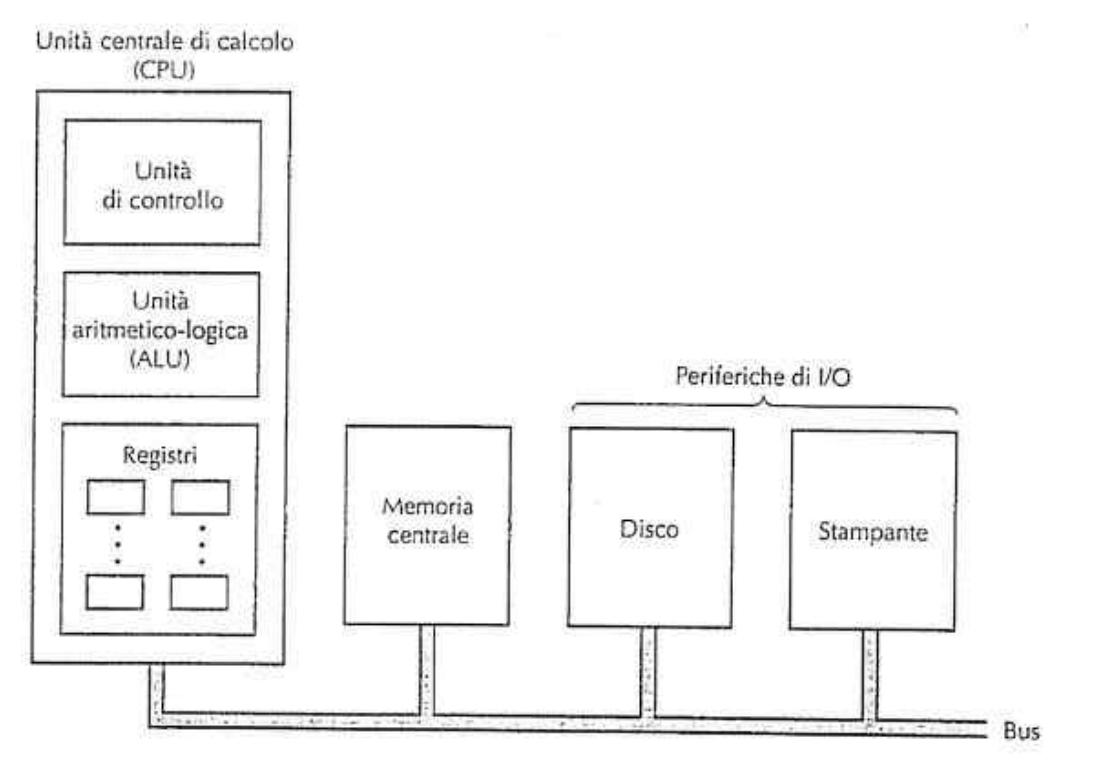
La CPU è composta da parti distinte connesse tra di loro mediante un BUS :
-
Central Unit (CU)
- preleva istruzioni dalla memoria
- determinare il tipo di istruzione
-
Arithmetic Logic Unit (ALU)
- esegue operazioni (somma, AND, …) per portare a termine l’esecuzione delle istruzioni
-
numero di Registri (memorie ad altissima velocità)
- memorizzati risultati temporanei
- memorizzati informazioni di controllo
Program Counter
Il PROGRAM COUNTER (PC) ha il compito di puntare alla istruzione successiva che dovrà essere prelevata (fetch) per l’esecuzione.
Instruction Register
Il INSTRUCTION REGISTER (IR) contiene l’istruzione corrente ovvero in fase di esecuzione.
Organizzazione della CPU
Una tipica CPU di von Neumann contiene il ==data path== (percorso dati) costituito da :
- registri (da 1-32 bit)
- ALU
- bus di collegamento
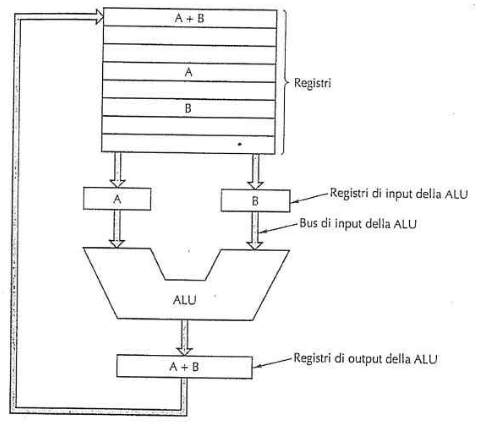
La ALU esegue, su i registri di input A e B , semplici operazioni come addizioni e sottrazioni e il risultato è posto in un registro di output. Inoltre ora il risultato nel registro di output PUÒ essere memorizzato nei registri e può essere anche copiato in memoria.
Le istruzioni sono divise in due categorie principali:
- REGISTRO-MEMORIA
- prelevare parole di memoria ( dalla memoria ) ( unità di dati spostati tra memoria e registri , es. un intero ) all’interno dei registri, che poi possono essere utilizzati come input dalla ALU , per effettuare istruzioni successive.
- copiare valori dei registri nella memoria
- REGISTRO-REGISTRO
- prelevare operandi (A,B) dai registri e li porta all’interno dei registri di input della ALU.
- memorizzare il risultato nei registri di output.
Il ciclo che si può formare , prendere gli operandi nella ALU → memorizzare il risultato , è chiamato ciclo del percorso dati.
I moderni computer hanno infatti piu ALU che operano in parallelo , e quindi più è veloce il ciclo del percorso dati , maggiore sarà la velocità del calcolatore.
Esecuzione delle istruzioni
La CPU per eseguire ogni istruzione compie degli step (passaggi) ( ciclo FETCH-DECODE-EXECUTE ) :
- Preleva l’istruzione successiva dalla memoria per inserirla nell’ IR ( Instruction Register ).
- Aggiorna il PC ( Program Counter ) per farlo puntare alla prossima istruzione.
- Identifica il tipo di istruzione che è stata caricata.
- Se l’istruzione richiede l’accesso ad un dato (parola) in memoria, la CPU la cerca in memoria (grazie all’indirizzo).
- Se necessario porta il dato in un registro della CPU.
- Esegue l’istruzione.
- Ritorna allo step 1 per iniziare l’esecuzione dell’istruzione successiva (siccome ora il PC punta a quella successiva).
RISC contro CISC
CISC
Nelle architetture CISC (Complex Instruction Set Computer) la CPU è in grado di comprendere molte istruzioni complesse nativamente (più alto livello di astrazione riconosciuto dalla macchina).
Infatti le CPU CISC sono progettate per eseguire istruzioni molto sofisticate, che possono compiere operazioni complesse in un solo comando. Questo riduce la quantità di codice da scrivere e può semplificare lo sviluppo software. Le istruzioni CISC sono spesso interpretate e questo può rallentare l’esecuzione.
RISC
Nel 1980 un gruppo cominciò la progettazione di chip VLSI per CPU che non utilizzavano l’interpretazione , per indicare il progetto venne coniato l’acronimo RISC (Reduced Instruction Set Computer), significa infatti computer con un inseme ridotto di istruzioni.
Le architetture RISC erano basate sull'idea che se le istruzioni erano poche e semplici, allora esse potevano essere eseguite più velocemente.
Infatti le istruzioni RISC sono progettate per essere eseguite in un solo ciclo di clock (un solo ciclo nel data-path), per esempio un’istruzione RISC potrebbe leggere due registri , sommarli e memorizzare il risultato in un’altro registro , tutto solo in un solo ciclo nel data-path.
Anche se un’istruzione complessa potrebbe richiedere più istruzioni RISC , rispetto ad una sola CISC , le istruzioni RISC sono più veloci perché NON INTERPRETATE.
Principi di progettazione dei calcolatori moderni
Dopo piu di due decenni , alcuni principi di progettazione sono stati accettati come un buon modo di progettare i calcolatori che i progettisti di CPU cercano di seguire : PRINCIPI DI PROGETTAZIONE RISC.
1. Tutte le istruzioni sono eseguite direttamente dall’hardware
Tutte le istruzioni comuni devono essere eseguite dall’hardware. Quindi non sono interpretate il che elimina un livello di interpretazione e si garantisce più velocità. Per le architecture CISC, quelle istruzioni piu complesse e più rare (utilizzate con minor frequenza), devono essere divise in parti ed eseguite come una sequenza di microistruzioni (istruzioni più semplici che l’hardware può eseguire direttamente).
2. Massimizzare la frequenza di emissione delle istruzioni
Nei calcolatori moderni si usano molti trucchi per massimizzare le loro prestazioni , tra qui iniziare a eseguire più istruzioni al secondo. Questo principio ci dice che il parallelismo gioca un ruolo essenziale nelle prestazioni di un computer.
Infatti è possibile emettere tante istruzioni (anche lente) in un poco tempo solo se si riescono a eseguire più istruzioni allo stesso tempo.
Questo porta a tenere conto di molti aspetti , come per esempio: se l’istruzione 1 imposta un valore di un registro e l’istruzione 2 usa lo stesso registro, occorre prestare attenzione che l’istruzione 2 legga il registro dopo che l’istruzione 1 ci ha impostato il valore giusto.
3. Istruzioni facili da decodificare
Un limite critico sulla frequenza di emissione delle istruzioni è dato dal processo di decodifica di una istruzione, necessario per determinare le risorse necessarie per quella istruzione.
Quindi bisogna rendere le istruzioni:
- regolari
- lunghezza fissa
- pochi campi/variabili
4. Solo le istruzioni LOAD e STORE fanno riferimento alla memoria
Siccome l’accesso alla memoria può richiedere un tempo considerevole, allora la maggior parte delle istruzioni dovrebbe operare sui registri, mentre l’operazione di spostamento può essere compiuta separatamente. Quindi solo le istruzioni LOAD (memoria → registro) e STORE (registro → memoria) dovrebbero far riferimento alla memoria, mentre le altre devono operare esclusivamente sui registri.
5. Molti registri disponibili nelle CPU (min 32)
Siccome l’accesso alla memoria è lento , occorre prevedere che ci siano molti registri (almeno 32) in modo che una volta prelevata una WORD (parola), questa può rimanere nel registro finché non serve più. Questo anche perché risulterebbe molto inefficiente trovarsi senza registri liberi che porta a → scaricare in memoria tutti i valori dei registri → ricaricarli dalla memoria.
Parallelismo: più istruzioni nell’unità di tempo
I progettisti di calcolatori tendono costantemente a migliorare le prestazioni delle loro CPU , aumentando la velocità di clock. Ma questo ha raggiunto un limite fisico , per questo i progettisti di CPU vedono nel parallelismo un modo per ottenere prestazioni più elevate con una certa velocità di clock.
Il parallelismo si può ottenere in due modi:
- A LIVELLO DI ISTRUZIONE:
- parallelismo sfruttato all’interno delle singole istruzioni per ottenere un maggior numero di istruzioni al secondo.
- A LIVELLO DI PROCESSORE
- sono presenti più CPU che collaborano per risolvere lo stesso problema.
PARALLELISMO A LIVELLO DI ISTRUZIONE
PIPELINING
Da anni oramai si sa che il principale collo di bottiglia nella velocità di esecuzione delle istruzioni è rappresentato dal prelievo (fetch) delle istruzioni dalla memoria.
Inizialmente per alleviare questo problema, i calcolatori sono stati dotati della capacità di poter prelevare in anticipo le istruzioni dalla memoria, in modo da averle già a disposizione. Le istruzioni venivano memorizzate in un insieme di registri chiamati PRE-FETCH BUFFER.
Con il PIPELINE questa tecnica viene spinta ancora di più, invece di dividere l'esecuzione di un'istruzione solamente di due fasi (prelievo, esecuzione), viene divisa in gran numero di parti (processi o stage) che possono essere eseguite in parallelo da unità hardware dedicate, dove ogni stage della pipeline esegue una parte dell'istruzione.
Esempio con 5 stage :
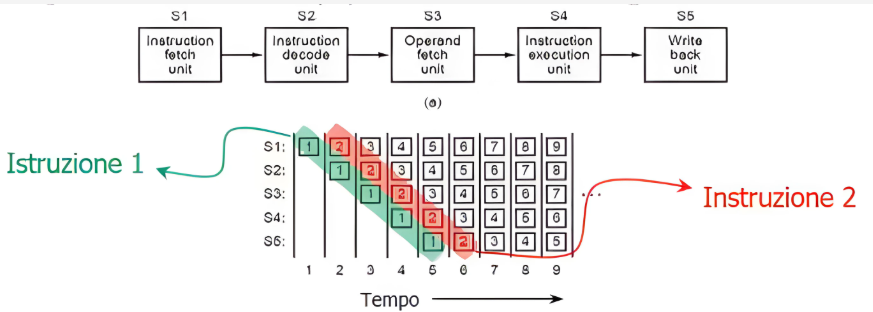
(lista in corrispondenza ai clock (tempo) es. 1 → primo clock)
- S1 preleva l’istruzione dalla memoria nel buffer di prefetch.
- S2 decodifica l’istruzione 1 , mentre (parallelismo) S1 preleva l’istruzione 2.
- S3 preleva gli operandi per l’istruzione 1, mentre S2 decodifica istruzione 2 e S1 preleva l’istruzione 3.
- S4 esegue istruzione 1, S3 preleva gli operandi per istruzione 2, S2 decodifica l’istruzione 3 e S1 preleva l’istruzione 4.
- S5 scrive il risultato dell’istruzione 1 nei registri (compreso risultato di stato), mentre gli altri S lavorano per le altre istruzioni successive.
Insomma come il processo di fabbricazione di una torta, ogni istruzione (torta) attraversa vari passi (stage) di elaborazione prima di uscire.
Incremento della banda del processore con pipeline
L’uso della pipeline permette di bilanciare la latenza(tempo di esecuzione di un’istruzione) e la larghezza di banda del processore (ovvero i MIPS - Million Instructions Per Second della CPU).
Supponiamo di avere una CPU senza pipeline, che opera con un ciclo di clock di ns (nanosecondi), allora se la CPU emette un’istruzione per ciclo di clock, la banda del processore è MIPS ( perché ci sono milioni di ns in un secondo).
Invece una CPU con pipeline a stage (dove ogni stage richiede un ciclo di clock per essere completato) e ciclo di clock di ns.
- latenza totale: siccome ogni istruzione deve attraversare stage , la latenza totale = ns
- banda : MIPS ovvero volte rispetto alla banda di una CPU senza pipeline.

Processori con più pipeline
Avere una sola pipeline è buono, ma averne 2 è sicuramente meglio.
Questa è l’architettura utilizzata inizialmente dal Intel x486
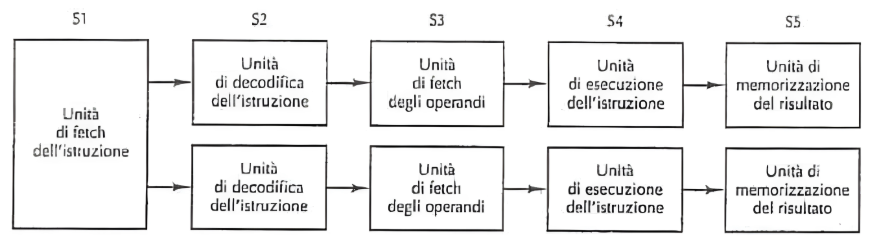
In questa situazione, una singola unità di fetch preleva le due istruzioni alla volta e le inserisce nelle pipeline (ognuna con ALU). Però dobbiamo considerare che:
- non tutte le istruzioni possono essere eseguite in parallelo perché magari una dipende dal risultato dell’altra (precedente)
- non devono esserci conflitti nell’uso dei registri (risorse)
- sarebbero necessarie componenti hardware ad hoc per le varie unità di sincronizzazione
Per esempio il primo Pentium aveva 2 pipeline (da 5 stage):
- u : eseguiva qualsiasi istruzione Pentium
- v : eseguiva solo istruzioni semplici su interi
Una tecnica che adottano alcune CPU di alta gamma è di usare una singola pipeline ma con più unità funzionali (ovvero parti specializzate per eseguire compiti specifici) collegate ARCHITETTURA SUPER-SCALARE.
PARALLELISMO A LIVELLO DI PROCESSORE
La richiesta di calcolatori sempre più veloci è sempre più alta (gaming,simulazioni spazio,economia) ma il problema è la dissipazione di calore.
Il parallelismo a livello di istruzione permettono di eseguire più istruzioni contemporaneamente in una singola CPU. Questo può migliorare le prestazioni di un fattore da 5 a 10, ma non di più.
Per ottenere guadagni di > 50 o 100 , l’unica soluzione è quella di progettare calcolatori con più CPU, infatti esistono tre differenti approcci:
- COMPUTER CON PARALLELISMO SUI DATI
- MULTI-PROCESSORI
- MULTI-COMPUTER
Computer con parallelismo sui dati
Per eseguire programmi in ambiti computazionali come la fisica, l’ingegneria e la computer graphic in modo rapido ed efficiente, sono stati utilizzati due metodi:
- processori SIMD (calcolatore parallelo)
- processori vettoriali (estensione del singolo processore)
Con il parallelismo sui dati abbiamo che tutti i processori sono in esecuzione sulla stessa istruzione contemporaneamente. Quindi il sistema ha bisogno di un solo “cervello” per controllare il computer (un solo stage di prelievo, uno di decodifica, e uno di logica di controllo). Quindi riducendo la necessità di controllo individuale → più efficiente.
SIMD
Un processore SIMD (Single Instruction-stream Multiple Data-stream → "singole istruzione,dati multipli") consiste in un elevato numero di processori identici che eseguono la stessa sequenza d'istruzioni su insiemi diversi dati (esempio GPU).
Classificazione di Flynn
Classifichiamo ora i computer in base a due fattori :
- flusso di istruzioni (# di istruzioni eseguite contemporaneamente)
- flusso di dati (# di dati su cui si lavora)
| Flusso di Istruzioni | Flusso di Dati | Nome | Esempio |
|---|---|---|---|
| Singolo | Singolo | SISD | Modello Von Neumann |
| Singolo | Multiplo | SIMD | Super-computer vettoriali (GPU,…) |
| Multiplo | Singolo | MISD | Non sono note (poco usate) |
| Multiplo | Multiplo | MIMD | Multiprocessori/Multicomputer (CPU multi-core) |
Classificazione dei calcolatori paralleli
Vediamo ora una classificazione delle architetture dei calcolatori paralleli, organizzata in modo gerarchico.
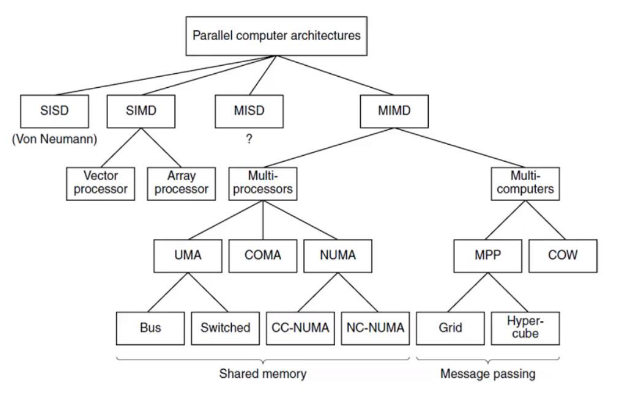
Il 3 livello (livello intermedio) si riferisce a come è organizzata la memoria nei sistemi paralleli : MULTI-PROCESSORI →
- UMA (Uniform Memory Access) : dove tutti i processori accedono alla memoria alla stessa velocità.
- NUMA (Non-Uniform Memory Access) : alcuni processori accedono alla memoria più velocemente di altri.
- COMA (Cache Only Memory Access) : la memoria è gestita come una cache distribuita (ogni processore ha la propria memoria locale → cache).
MULTI-COMPUTER →
- MPP (Massively Parallel Processors): tantissimi processori (nodi di calcolo) che lavorano in parallelo e dove ogni processore ha la propria memoria locale non condivisa con gli altri processori.
- COW (Cluster Of Workstation): gruppo di computer collegati in rete che lavorano insieme.
Il livello 4 (livello inferiore) si riferisce alle topologie di interconnessione (ovvero come i processori sono collegati tra di loro) UMA →
- Bus : condividono un unico canale
- Switched : collegati tramite “switch” per comunicazione più efficiente
NUMA →
- CC-NUMA (Cache-Coherent NUMA) : memoria distribuita in coerenza della cache.
- NC-NUMA (Non-Coherent NUMA) : memoria distribuita senza coerenza della cache.
MPP →
- Grid : rete di computer distribuiti geograficamente
- Hyper-cube : topologia a ipercubo.
MULTIPROCESSORI
Sistema parallelo composto da più CPU con una memoria in comune (es. gruppo di persone condividono la stessa lavagna). Siccome ogni CPU può leggere o scrivere qualsiasi zona della memoria (in comune), le CPU devono sincronizzarsi - via software - per evitare di ostacolarsi a vicenda. Quando due o più CPU possono interagire tra di loro in modo così profondo , si che sono ==TIGHLY COUPLED== (fortemente accoppiate).
La prima implementazione consiste nel avere un singolo BUS, con più CPU tutte connesse a un’unica memoria :
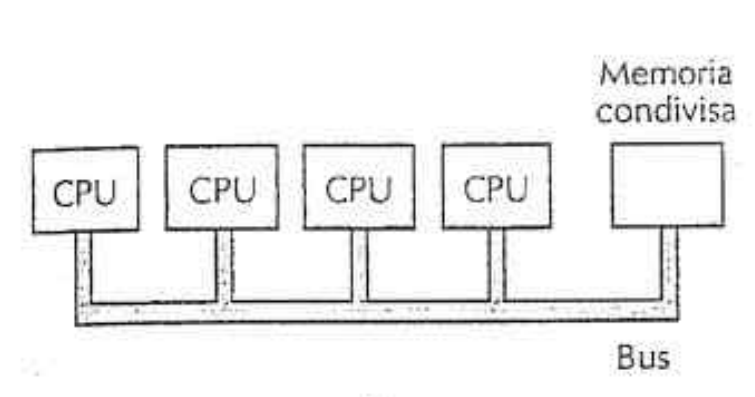
In questo caso però si presenta il problema di conflitti dove un gran numero di processori veloci tenta di accedere costantemente alla memoria attraverso lo stesso BUS. Infatti per ridurre questi problemi i progettisti di multiprocessori hanno ideato vari schemi (tra qui quello qui sotto e il caching → vedi collegamento a memoria principale).
Qui ogni processore possiede una propria memoria locale non accessibile agli altri processori e l’accesso a questa memoria (privata) non utilizza il bus principale → riducendo il traffico sul bus principale.
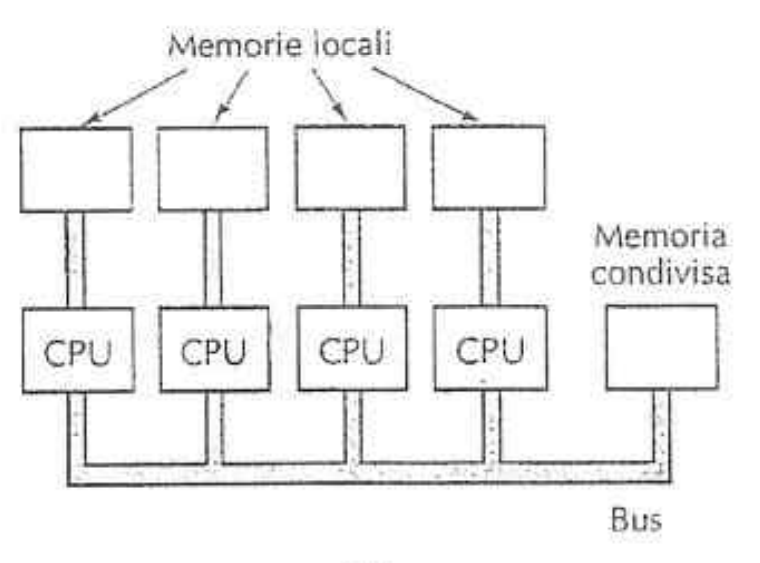
MULTICOMPUTER
Costruire multiprocessori con più di 256 CPU è difficile da fare, siccome c’è il problema di connettere tutti i processori alla memoria comune. Per questo i progettisti hanno abbandonato l’idea di avere una memoria comune e hanno costruito architetture composte da tante CPU (calcolatori) interconnesse, ciascuno dotato di una memoria privata → MULTICOMPUTER.
In questi sistemi le CPU sono accoppiate in modo “lasco” (LOOSELY COUPLED). Inoltre le CPU comunicano attraverso scambio di messaggi (come email ma molto + veloci).
Nel caso di architetture grandi, connettere tutti i calcolatori mutualmente non è efficiente, per questo sono utilizzate topologie diverse come la Griglie (2D,3D) , alberi e anelli.
Sono stati costruiti multicomputer dotati di oltre 250.000 CPU , come l’IBM Blue Gene/P.
Prossimo : Memoria-principale