
Per decenni, l’industria informatica ha inseguito un obiettivo semplice e potente: aumentare le performance aumentando la frequenza di clock della CPU. Un clock più veloce significa più operazioni eseguite in un secondo. È stato un percorso lineare e vincente, noto come Legge di Moore.
Tuttavia, all’inizio del XXI secolo, ci siamo scontrati con un limite fisico invalicabile (teoria della relatività di Einstein): la velocità della luce.
- nei materiali come il rame su cui sono costruiti i chip, i segnali elettrici viaggiano a circa 20 cm per nanosecondo.
- prendiamo una CPU con un clock di 10 GHz. Il periodo, ovvero quanto dura un singolo ciclo di clock (T), è:
- quindi in questo minuscolo intervallo di tempo di 0.1 ns, un segnale elettrico può percorrere :
Questo significa che in un singolo ciclo di clock, un segnale non può percorrere più di 2 cm all’interno del computer.
Supponiamo ora di avere un computer con un clock di 1 THz () , allora il suo ciclo di clock sarebbe :
questo permetterebbe al segnare di andare avanti e indietro in un ciclo di clock.
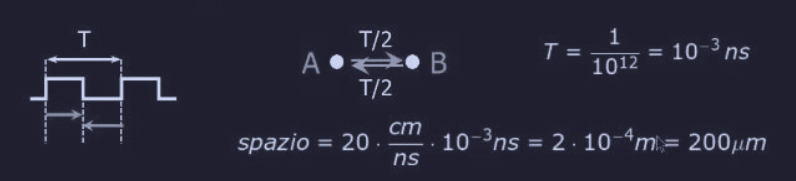
Rendere computer così piccoli è possibile ma andiamo incontro ad un altro problema, quello della dissipazione del calore.
Se non possiamo più rendere un singolo cervello più veloce, perché non usare tanti cervelli che lavorano insieme? Questo è il concetto di architetture parallele.
Quindi invece di una singola CPU super-veloce (e super-calda), usiamo molte CPU con una velocità di clock normale e gestibile, interconnesse tra loro, che collaborano per risolvere lo stesso problema, dividendosi il lavoro.
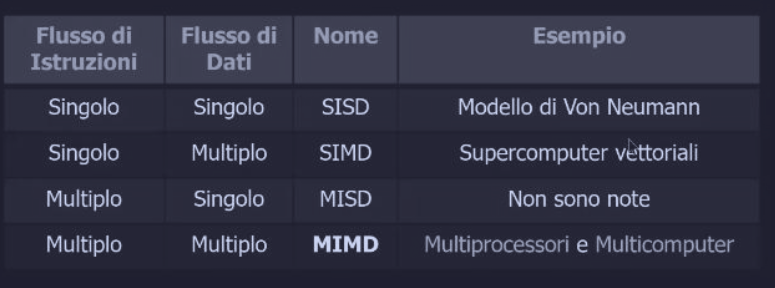
Classificazione di Flynn - 1966
Come già abbiamo visto in Processori, la classificazione di Flynn è un modo per categorizzare le architetture di calcolo in base alle dimensioni del flusso di dati e di istruzioni :
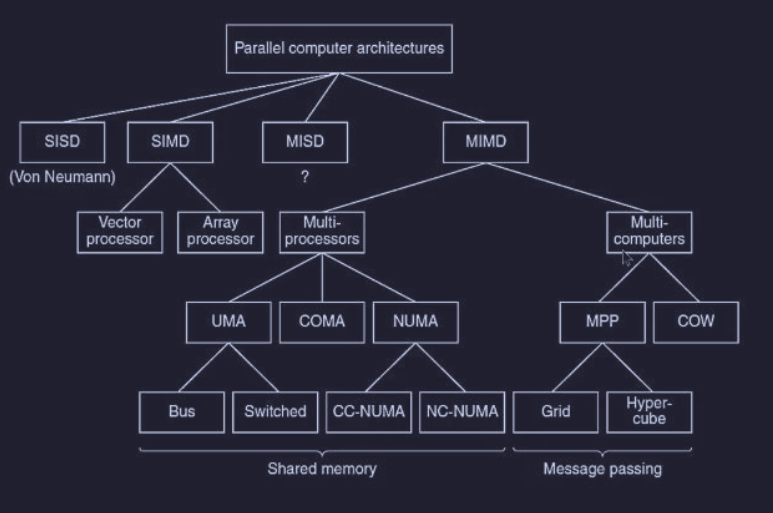
Mentre la tassonomia dei calcolatori paralleli :
Strategie per il parallelismo
^architetture-parallele Vediamo ora di introdurre diverse “strategie” per ottenere più potenza di calcolo (mettendole anche a confronto) :
- parallelismo nel chip
- tecniche per far eseguire più operazioni alla singola CPU. Quindi non aggiungiamo CPU fisiche, ma rendiamo più efficiente quella esistente
- tra le tecniche migliori abbiamo
- pipelining : catena di montaggio dove più istruzioni sono in fase di esecuzione contemporaneamente
- architetture scalari
- si può migliorare ad un fattore di miglioramento da 5 a 10
- sistemi con molte CPU :
- interconnettere più CPU
- si può ottenere miglioramenti di 50 o 100 volte
- esistono tre differenti approcci :
- Data Parallel Computers (SIMD)
- Multiprocessors (MIMD)
- Multicomputers (MIMD)
La seguente immagine mostra uno “spettro di architetture”, ordinate in base alla “strettezza” dell’accoppiamento tra le unità di calcolo, dal più stretto al più lasco :
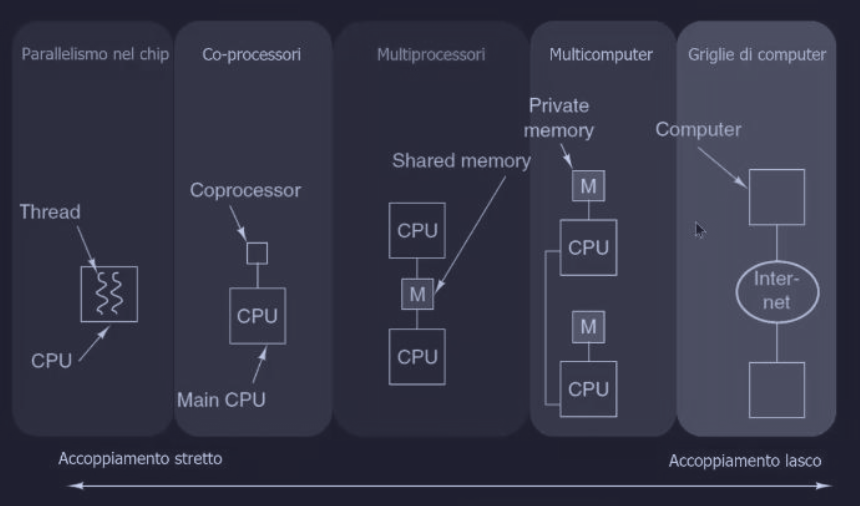
- Parallelismo nel Chip : multiple unità di esecuzione (thread) all’interno di un singolo core di una CPU condividono tutte le risorse
- Co-processori : una CPU principale delega compiti specializzati a un processore dedicato (co-processor)
- Multiprocessori :
- più CPU distinte che condividono la stessa memoria fisica centrale
- l’accoppiamento è “stretto” perché la comunicazione via memoria è estremamente veloce
- Multicomputer :
- ogni CPU ha la sua memoria privata (M)
- sono computer completi e indipendenti
- la comunicazione avviene tramite una rete di interconnessione
- l’accoppiamento è più “lasco” perché la comunicazione è più lenta e avviene via messaggi
- Griglie di Computer (Grid Computing) : si collegano computer geograficamente distribuiti (con Internet) per creare un unico, grande sistema virtuale
Parallelismo a livello delle istruzioni
Invece di aggiungere più processori, abbiamo già visto in Processori che è possibile eseguire più istruzioni in un singolo processore, ovvero il parallelismo a livello di istruzione. Inoltre possiamo avere una singola “linea” di pipeline ma con più unità funzionali in parallelo. Infatti i processori VLIW (Very Long Instruction Word) sono in grado di indirizzare le diverse unità funzionali.
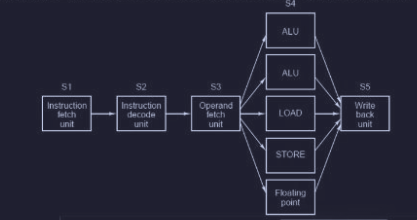
Problema dello stallo della pipeline
Il concetto di pipeline ha un problema, infatti quando la CPU cerca un dato nella cache e non lo trova, deve caricarlo dalla memoria e quindi attendere il caricamento prima di riprendere l’esecuzione. Quindi la “catena di montaggio” della pipeline (mentre un’istruzione viene eseguita, la successiva viene decodificata etc) viene fermata.
Consideriamo un esempio dove abbiamo 3 thread A, B e C :
- le istruzioni
A1,B1eC1partono insieme - l’istruzione
A2subisce una cache miss e impiega 2 cicli per essere completata - il problema è che durante quei 2 cicli era possibile eseguire altre istruzioni
- ogni tanto anche i thread B e C hanno degli stalli
Per risolvere questo problema, il multithreading nel chip permette di mascherare queste situazioni di stallo attraverso lo switch tra thread ed esistono tre differenti approcci :
- multithreading a grana fine
- multithreading a grana grossa
- multithreading simultaneo
Multithreading a grana fine
Il processore cambia thread (a turno) ad ogni singolo ciclo di clock.

Quando un’istruzione si blocca (come A2) il thread (come previsto) cambia di turno e passa a B, in questo caso i cicli di stallo di prima di A2 vengono rimpiazzati con l’esecuzione delle istruzioni B2 e C2.
Inoltre dobbiamo considerare alcune caratteristiche :
- siccome non esiste nessuna relazione tra i thread, ciascuno ha il proprio insieme di registri privato per non mescolare i dati
- il numero massimo di thread è fisso, definito in fase di progettazione
- nella pipeline c’è al massimo un’istruzione per thread alla volta
Multithreading a grana grossa
Il principio di base è semplice, dove si lascia che un thread lavori finché può e il cambio di contesto avviene solo quando il thread subisce uno stallo. Nel momento in cui un thread subisce uno stallo si perde un ciclo.
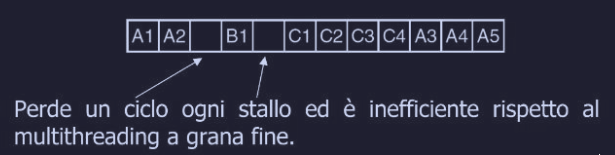
Questo approccio :
- richiede meno thread per mantenere la CPU occupata
- esiste una variante che “guarda avanti” le istruzioni anticipando lo stallo e permette di avvicinarsi all’efficienza del multithreading a grana fine
Multithreading nelle CPU super-scalari
Nelle CPU super-scalari abbiamo due catene di montaggio parallele :
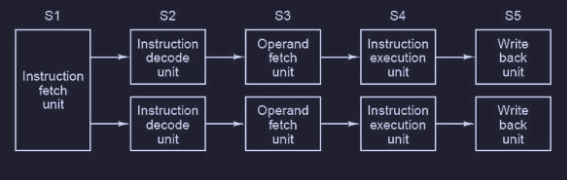
è possibile quindi utilizzare le tecniche viste prima del multithreading nel chip anche nelle CPU super-scalari. Quindi in ogni thread sono eseguite due istruzioni per ciclo finché non si raggiunge uno stallo :
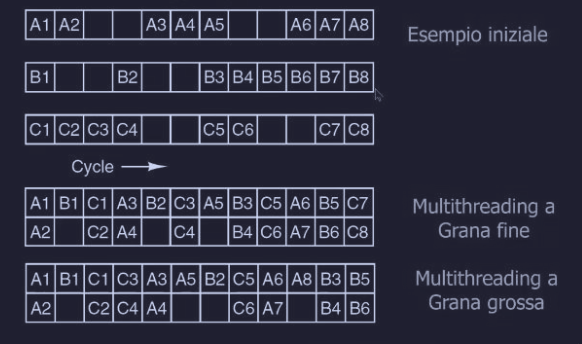
Il problema qui è che ogni “colonna” appartiene ad un solo thread e quindi se quel thread utilizza solo metà della risorse, l’altra metà va sprecata (i quadrati vuoti). Esiste un approccio per risolvere questo problema, chiamato multithreading simultaneo, dove la CPU diventa capace di “mescolare” le istruzioni, quindi nello stesso ciclo di clock possono essere eseguite due istruzioni di due thread diversi.

Multiprocessori in un solo chip
Per anni, per rendere i computer più veloci, i produttori hanno semplicemente aumentato la velocità (frequenza) del processore. Il problema era che se andavano più veloci, i chip diventavano troppo caldi (dissipazione) e i segnali elettrici non riuscivano a viaggiare abbastanza in fretta attraverso il materiale. Fortunatamente, la tecnologia ha permesso di rendere i componenti base (transistor) sempre più piccoli. Quindi, non potendo fare un processore più veloce, hanno deciso di usare quello spazio extra. Invece di avere un solo “cervello” velocissimo, ne hanno messi due, quattro o più (core) che lavorano insieme.
Esiste una distinzione fondamentale tra i multiprocessori :
- multiprocessori omogenei : dove tutti i core sono identici e hanno le stesse funzionalità, la stessa potenza e stesso set di istruzioni
- multiprocessori eterogenei : i core hanno specifiche funzionalità
Multiprocessori omogenei
I multiprocessori omogenei si dividono in due :
- quelle con una sola CPU ma con più pipeline che possono aumentare il throughput in base al numero di pipeline
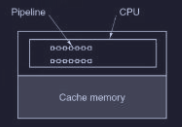
- quelle che hanno più CPU (core) ciascuna con la propria pipeline. In questo modo siccome sono unità separate farle collaborare è più complesso rispetto al primo metodo (condividono lo stesso la memoria cache sottostante)
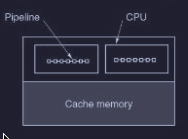
Per la condivisione per la memoria cache ci sono due possibili strade :
- cache condivisa : tutti i core usano una grande dispensa comune (L2 cache centralizzata)

- cache privata : ogni core ha il suo “frigobar” personale
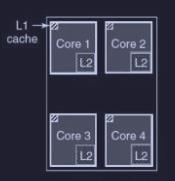
Nel metodo a cache privata per tenere aggiornati i dati in ogni cache di ogni core, esiste il processo di snooping (spionaggio) (eseguito dall’hardware) che controlla costantemente i dati nelle varie cache dei core.
Multiprocessori eterogenei
A differenza dei processori visti prima (dove i core erano tutti identici e intercambiabili), qui ogni unità di elaborazione è uno “specialista” progettato per fare benissimo una sola cosa. Mettendo insieme tanti specialisti diversi nello stesso pezzetto di silicio, si ottiene un computer intero in miniatura (System on a Chip). Il problema critico è che costruire questi chip potenti è diventato “facile” per gli ingegneri hardware, ma usarli è difficilissimo per i programmatori software. Infatti esistono pochi programmatori in grado di scrivere algoritmi paralleli senza che questi core si “pestino i piedi” (competizione per le risorse).
Chip-Level Multiprocessor - CMP
Fino ad ora abbiamo parlato di ‘core’. Ora dobbiamo fare un salto concettuale: un chip multi-core non è altro che un piccolo multiprocessore. Per questo motivo viene tecnicamente definito CMP (Chip-level Multiprocessor).
Questo significa che per un programmatore le tecniche di programmazione parallela non cambia se per scrivere per un server con 4 CPU fisiche o per un processore con 4 core.
Coprocessori
Per velocizzare un calcolatore si può aggiungere un secondo processore specializzato (coprocessore). Esistono molte varianti di coprocessori, di dimensioni molto diverse.
In alcuni casi la CPU assegna al coprocessore un’istruzione o un insieme d’istruzioni e gli ordina di eseguirle; in altri casi il coprocessore è più indipendente e lavora per conto proprio. In tutti i casi, ciò che li caratterizza è il fatto di assistere nell’esecuzione un altro processore, che resta il processore principale.
Esistono tre settori in cui è possibile velocizzare le prestazioni:
- elaborazione di rete (processori di rete)
- multimedia (processori grafici)
- crittografia (crittoprocessori)