
Quando si verifica un page fault, come abbiamo già detto in Paging, il OS deve scegliere una pagina da rimuovere (sostituire) dalla memoria per fare spazio alla pagina che manca. Ricordiamo inoltre che se la pagina è stata modificata, prima di sostituirla bisogna riscriverla sul disco.
Ci sono molti algoritmi che hanno la funzione di scegliere la miglior pagina candidata per la rimozione, e si basa tutti sull’idea di minimizzare il numero di page fault futuri, selezionando quelle pagine che sono usate raramente (quindi è giusto che siano sul disco e non in memoria).
Se fosse possibile etichettare ogni pagina con il numero di istruzioni che saranno eseguite prima che quella pagina sia referenziata di nuovo, l’algoritmo sarebbe banale, infatti basterebbe rimuovere la pagina con il numero più grande. Purtroppo, al momento del page fault, il OS non può sapere quando ciascuna pagina verrà referenziata di nuovo (quindi quel numero non lo può sapere).
Not Recently Used - NRU :luc_bar_chart_2:
Vengono utilizzati i due bit di stato associati ad ogni pagina :
R: impostato ogni volta che la pagina è referenziata (in lettura o scrittura)M(bit dirty o di modifica) : viene impostato quando la pagina viene scritta Questi bit devono essere aggiornati dall’hardware ad ogni riferimento alla memoria.
Quando un processo viene avviato, l’OS imposta a 0 i due bit della pagina, ed ad ogni impulso di clock il bit R viene azzerato, per distinguere le pagine che sono state utilizzate recentemente da quelle non usate.
Quindi quando si verifica un page fault, il OS controlla tutte le pagine e le separa in 4 categorie diverse:
- classe 0 :
R=0non referenziataM=0non modificata
- classe 1 :
R=0non referenziataM=1modificata
- classe 2 :
R=1referenziataM=0non modificata
- classe 3 :
R=1referenziataM=1modificata
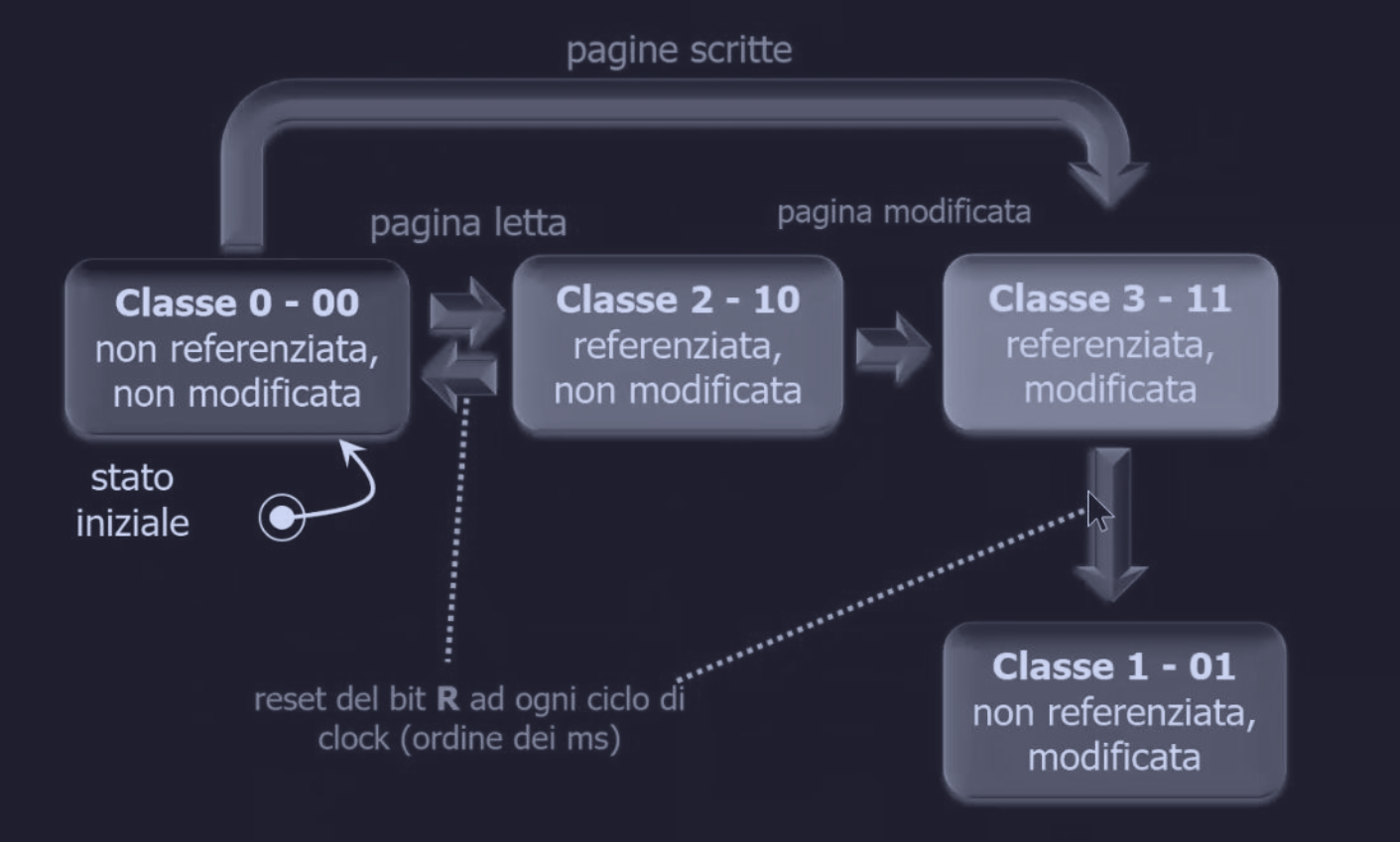
La pagine della classe 1 sembrano impossibili, ma appaiono quando ad un interrupt del clock viene azzerato il bit R di una pagina di classe 3.
L’algoritmo NRU cerca nella classe non vuota, con il numero più basso e rimuove una pagina a caso da quella classe :
- controlla prima la classe 0, se trova una o più pagina ne sceglie una a caso e la rimuove
- se la classe 0 è vuota, passa alla classe 1 e cosi via
review I vantaggi del NRU sono :
- semplice
- facile e veloce da implementare
- prestazioni accettabili
First In First Out - FIFO
In questo algoritmo il OS mantiene una lista (coda) di tutte le pagine attualmente in memoria, dove la pagina più recente è in coda (fine) e quella meno recente (più vecchia) è in testa (inizio).

Quando accade un page fault, la pagina in testa viene rimossa e la nuova pagina è aggiunta alla coda nella lista.
Il problema è che l’algoritmo non tiene conto dell'utilizzo della pagina, ma solo dell’ordine di caricamento in memoria. Quindi la pagina più vecchia potrebbe essere essenziale (ancora in uso) e portandola a scartarla.
FIFO 2 - algoritmo della seconda chance
Una semplice modifica al FIFO, che evita di buttare via una pagina usata frequentemente, è di ispezionare il bit R della pagina in testa alla coda (candidata per la sostituzione) :
- se 0 : la pagina non è stata utilizzata recentemente e quindi si può sostituire
- se 1 : la pagina è stata usata recentemente e quindi non si può sostituire.
- in questo caso il bit
Rviene azzerato e alla pagina viene data una “seconda chance” - reinserita in coda alla lista
- aggiornato il suo timestamp di caricamento
- la ricerca prosegue con la pagina successiva
- in questo caso il bit

Per esempio :

Se nella ricerca della pagina da sostituire tutte le pagine sono state referenziate, questo algoritmo inizia a lavorare come FIFO puro (è logico).
Algoritmo a Clock - orologio
review L’algoritmo FIFO 2 è un buon metodo, ma è inefficiente siccome le pagine vengono costantemente spostate (ad ogni page fault) e manipolate nella coda.
L’idea quindi dell’algoritmo a clock è quella di mantenere i frame di pagina in una lista circolare.

Dove la lancetta punta alla pagina più vecchia.
Quando si verifica un page fault, si controlla il bit R della pagina puntata dalla lancetta, se :
- 0 : la pagine è sostituita con la nuova e la lancetta si muove alla successiva posizione
- 1 : il bit viene azzerato e la lancetta si muove alla successiva posizione fino a trovare una pagina con il bit
Ra 0
review I vantaggi :
- eliminazione inefficienza del FIFO 2
- più performante rispetto al FIFO 2 e FIFO
Least Recently Used - LRU
Una osservazione è che le pagine che sono state usate frequentemente nelle istruzioni recenti saranno probabilmente usate ancora presto. Mentre le pagine che non sono state utilizzate da molto tempo probabilmente resteranno inutilizzate.
Questa osservazione suggerisce il metodo LRU, ovvero quel metodo dove : quando si verifica un page fault, è meglio sostituire la pagina che è rimasta inutilizzata per più tempo.
Per realizzare questo algoritmo bisogna utilizzare una lista collegata di tutte le pagine in memoria, dove:
- la pagina utilizzata più recentemente si trova in testa
- la pagina meno recentemente utilizzata si trova in coda
La complicazione deriva dal fatto che questa lista collegata deve essere aggiornata ad ogni riferimento in memoria, siccome trovare una pagina nella lista e cambiargli posizione richiede molto tempo.
Per superare questa lentezza, sono possibili due realizzazioni hardware:
- utilizzo di un contatore a 64 bit
- utilizzo di una matrice binaria
Ma anche se entrambi gli algoritmi LRU sono fattibili, non esistono hardware che li realizzino !
Simulazione software del LRU - Not Frequently Used - NFU
Un altro algoritmo che può essere implementato via software è il NFU, dove ogni pagina ha un contatore software, inizialmente a 0.
Ad ogni interruzione di clock il OS scansiona tutte le pagine in memoria e somma il bit R al contatore rispettivo della pagina (0+1+1+0+…).
In questo modo ogni pagina ha un contatore che indica il numero di riferimenti fatti a quella pagina stessa.
Quando si verifica un page fault, la pagina con il contatore più basso viene scelta per la sostituzione.
Sembra tutto rose e fiori, ma c’è un problema con questo algoritmo, ovvero che non dimentica nulla. Infatti in un primo momento le pagine utilizzate intensamente avranno un conteggio elevato, però in un secondo momento quando non sono più utili quelle pagine ma altre, l’OS non riesce a sostituirle (siccome hanno il contatore alto), portando a sostituire effettivamente quelle che ci servono in questo secondo momento (problema in fase di boot o ambienti multi-pass).
Aging
L’algoritmo aging è una modifica del NFU che ne costituisce una buona approssimazione. Infatti il meccanismo :
- utilizzare l’operazione di shift a destra al contatore di ogni pagina ad ogni ciclo di clock
- si inserisce il bit
Rnella posizione più significativa (sinistra) - si azzera il bit
RIn questo modo si garantisce che i riferimenti recenti abbiano un peso maggiore di quelli più vecchi (age - aging).
Consideriamo per esempio una memoria con 6 pagine, il flusso sarà il seguente :
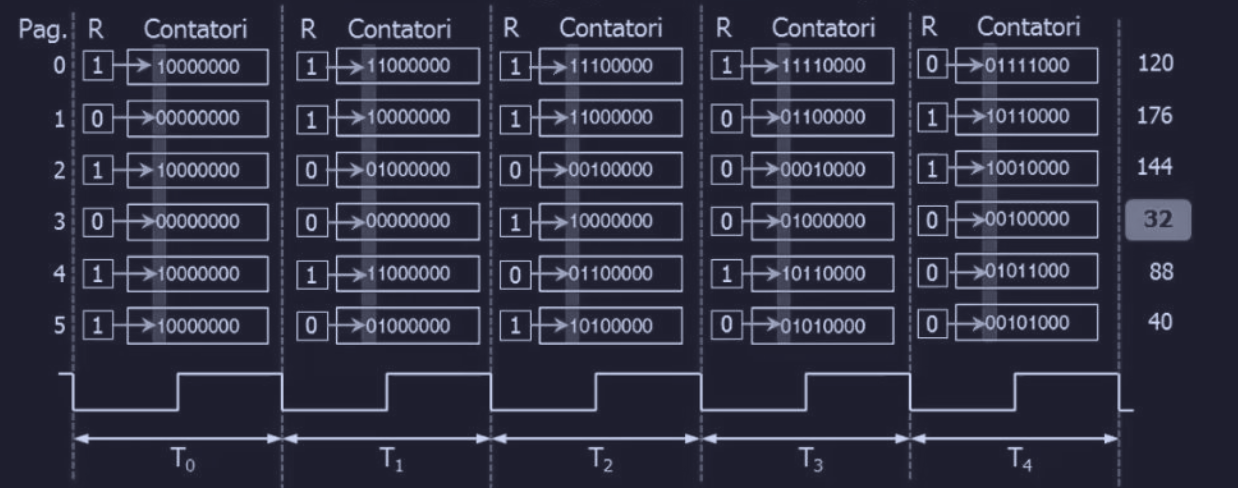
come possiamo notare :
- in caso di page fault viene rimossa la pagina 3, ovvero quella meno utilizzata
- tra la pagina 0 e la 2 c’è differenza ma cruciale :
- la pagina 0 l’abbiamo utilizzata “tanto” (4) all’inizio poi all’ultimo non ne abbiamo bisogno
- la pagina 2 all’inizio l’abbiamo utilizzata solo una volta e poi riutilizza alla fine (più recente), infatti il suo contatore è maggiore (144) della pagina 0
review Vediamo alcune considerazioni (pro-contro):
- LRU vero ricorda esattamente l’ordine di tutti gli accessi, senza limiti, mentre l’aging ha una “memoria corta” infatti con 8 bit (come nell’esempio) può ricordare solo gli ultimi 8 intervalli di clock, però
- in genere 8 bit forniscono un arco temporale sufficiente (160 ms) considerando un periodo di circa 20 ms
Il concetto di Working Set
Nella maggior parte dei casi vale un principio di località dei riferimenti, ovvero che durante l’esecuzione un processo utilizza solo una frazione piccola (insieme) delle sue pagine, chiamato Working Set.
Ovviamente se l’intero Working Set è in memoria il processo non causerà page fault.
Un processo che causa page fault ogni poche istruzioni è detto processo thrashing.
Molti sistemi di paging cercano di assicurarsi che il Working Set del processo sia in memoria prima di eseguirlo (Working Set Model), in modo da ridurre il tasso di page fault. Il caricamento della pagina prima di eseguire il corrispondente processo è chiamato prepaginazione.
Dobbiamo considerare inoltre che il Working Set cambia nel corso del tempo, infatti molti programmi non referenziano lo spazio di indirizzamento in modo uniforme, ma i riferimenti tendono a raggrupparsi in un numero ridotto di pagine.
La figura seguente mostra come nel tempo t , esiste un insieme di tutte le pagine utilizzate dagli ultimi k riferimenti di memoria, ovvero w(k,t).

w(k,t)è una funzione monotona non decrescente al crescere dikche tende al numero delle pagine del programma- se il numero di pagine più utilizzate recentemente (
k) è piccolo allora tenderò ad utilizzare più pagine, quindiw(k,t)tende a cresce rapidamente - esiste un ampio intervallo di valori di
kin cuiw(k,t)è quasi uniforme
PS : per capire meglio vediamo questa simulazione Simulazione by Claude
Quindi il working set è definito come l’insieme delle pagine usate negli ultimi
kriferimenti in memoria.
Approssimazione del working set
Il working set è spesso definito come l’insieme delle pagine utilizzare negli ultimi millisecondi del tempo di esecuzione (invece di utilizzare
k). Questo tempo di esecuzione di ogni pagina è chiamato tempo virtuale attuale.
Nella tabella delle pagine la riga contiene :
- timestamp dell’ultimo utilizzo
- il bit
Rse è stata referenziata nell’ultimo ciclo di clock- azzerato ad ogni ciclo di clock
- il bit
M(modificata)
Quando si verifica un page fault, si cerca nella tabella delle pagine la pagina da rimuovere (quelle fuori il working set), controllando il bit R:
- 1 : aggiorna il timestamp ultimo utilizzo come il timestamp attuale (pagina nel working set)
- 0 : si calcola l’età della pagina :
- se : la pagina non è più nel working set e può essere sostituita.
- se : la pagina è ancora nel working set e quindi risparmiata (per ora)
- se dopo aver controllato l’intera tabella delle pagine e non viene trovata alcuna pagina candidata (tutte le pagine sono nel working set), viene rimossa la pagina contrassegnata (anziana con
R=0). - nel caso tutte le pagine siano state referenziate (
R=1) durante l’ultimo ciclo di clock, viene rimossa una a caso tra quelle pulite (M=0).
WSClock
Gli algoritmi che si basano sul Working Set sono lenti, perché ad ogni page fault bisogna scorrere tutta la tabella delle pagine per trovare la pagina da rimuovere.
Una soluzione è una variante dell’algoritmo Clock che si chiama WSClock, che è quello più utilizzato.
Il funzionamento in caso di page fault è simile a quello dell’algoritmo clock + WS :
- in caso di page fault la “lancetta” punta alla pagina corrente da esaminare
- se
R=1la pagina è stata appena utilizzata (non è buona candidata per rimuoverla)Rè impostato a 0
- la lancetta va avanti per cercare una pagina da rimuovere
- se si verifica questa condizione :
vuol dire che la pagina non è nel working set ed esiste una copia valida sul disco (non è stata modificata), quindi la pagina può essere sovrascritta (sostituita) dalla nuova.
- se si verifica quest’altra condizione :
vuol dire che la pagina non è nel working set e NON esiste una copia valida sul disco (la pagina è stata modificata), quindi per evitare un cambiamento di processo, viene schedulata l’aggiornamento sul disco (lo fa dopo) e la lancetta passa alla pagina successiva.
Per esempio per capire meglio :
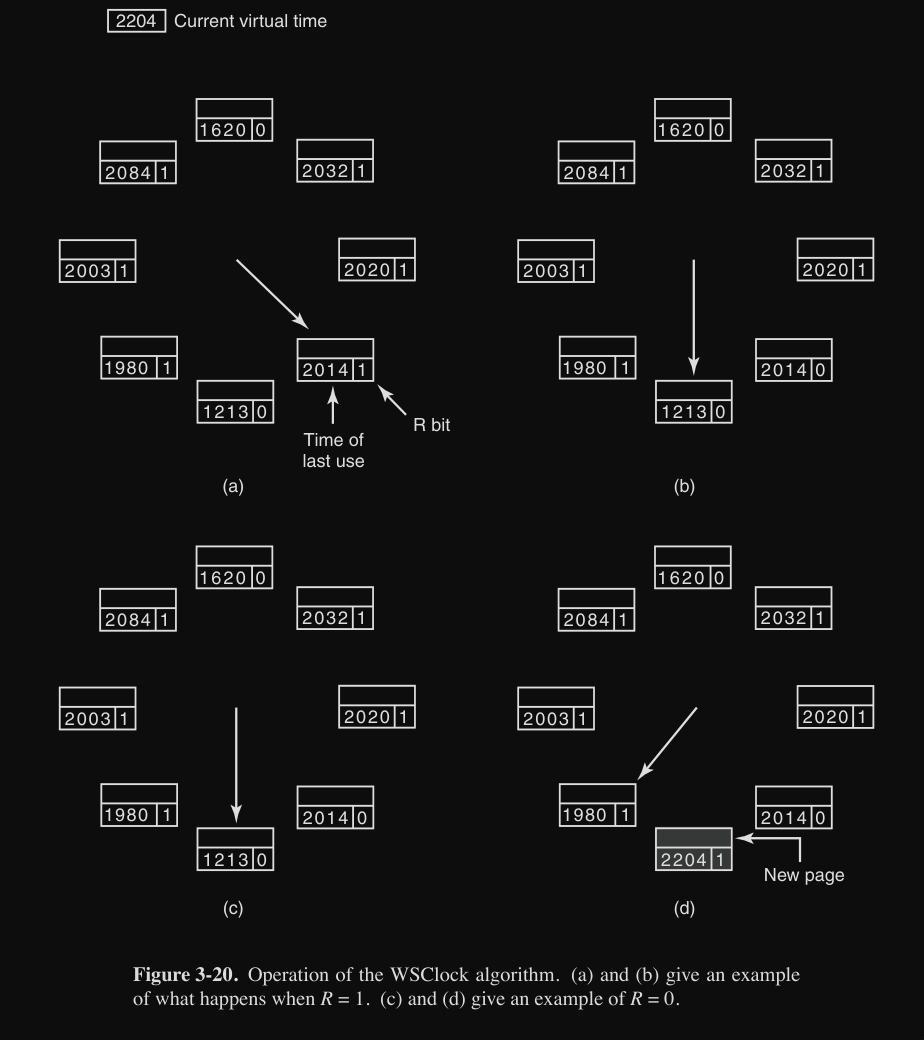
Siccome le scritture su memoria non volatile (disco/SSD) sono lente, viene impostato un limite massimo di scritture schedulate e una volta raggiunto quel limite, le ulteriori scritture vengono ignorate.
Ci chiediamo adesso che cosa succede se la "lancetta" torna al punto di partenza senza aver trovato la pagina da rimuovere?
Esistono 2 possibilità :
- sono presenti una o più scrittura/e pendenti (in caso dell’ultima condizione) :
- in questo caso la “lancetta” riprende il ciclo, siccome dal momento che una o più operazioni di scrittura (aggiornamento su disco) sono state programmate, al termine di queste operazioni una (o più pagine) saranno “pulite” (avranno il bit
M=0). Quindi la prima pagina che incontra la lancetta sarà rimossa
- in questo caso la “lancetta” riprende il ciclo, siccome dal momento che una o più operazioni di scrittura (aggiornamento su disco) sono state programmate, al termine di queste operazioni una (o più pagine) saranno “pulite” (avranno il bit
- NON sono presenti richieste di scritture pendenti :
- in questo caso tutte le pagine sono nel working set
- scelta come “vittima” una pagina a caso
- oppure se non ci sono pagine “pulite” disponibili, la prima pagina corrente viene scelta come “vittima” e la sua copia viene scritta su disco
Riepilogo
- NRU :
- divide le pagine in 4 classi a seconda dei bit
ReM - è scelta una pagina a caso dalla classe 0 (oppure se vuota vai avanti )
- facile da realizzare, è molto grezzo e ne esistono di migliori
- divide le pagine in 4 classi a seconda dei bit
- FIFO :
- mantiene l’ordine di caricamento delle pagine
- rimuove la pagina più vecchia (operazione semplice)
- il problema è che la pagina rimossa potrebbe essere ancora in uso
- algoritmo non utilizzabile
- FIFO 2 (Seconda chance) :
- versione applicabile del FIFO
- verifica se la pagina è in uso prima di rimuoverla
- questa modifica del FIFO ne migliora le prestazioni
- Clock :
- diversa organizzazione (struttura circolare) e realizzazione del FIFO 2
- richiede meno tempo per l’esecuzione
- LRU :
- eccellente algoritmo
- utilizzo del contatore o matrice binaria
- non può essere utilizzato senza hardware dedicato
- NFU :
- utilizzo contatore software
- tentativo grezzo di approssimare il LRU (simulazione software)
- Aging :
- buona approssimazione del LRU
- Working Set :
- richiede lunghi tempi di elaborazione
- troppo costo per realizzare
- WSClock :
- variante del working set
- buoni risulti ed è efficiente e valido
