
I progettisti dei OS devono considerare anche altri aspetti, oltre agli algoritmi utilizzati per la sostituzione delle pagine, al fine di ottenere buone prestazioni dai sistemi di paging :
- politiche di allocazione globale e locale (Da dove prendiamo le pagine?)
- politiche di allocazione equa e proporzionale (Quanti frame (memoria) allochiamo ad un processo?)
- dinamica di allocazione delle pagine review
- policy di pulizia
- dimensioni delle pagine
- dati e istruzioni su spazi separati
- pagine e librerie condivise
- file mappati in memoria
Politiche di allocazione
Il problema principale è la scelta della quantità di memoria che dovrebbe essere ripartito tra processi eseguibili.
Supponiamo per esempio di avere 3 processi in esecuzione (A, B e C) :
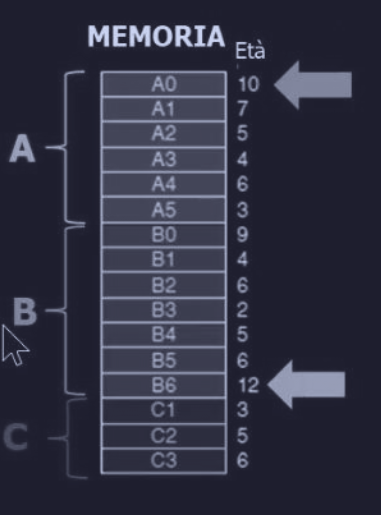
Il processo A ha un page fault, questo significa che ha bisogno di caricare una nuova pagina in RAM. La domanda che ci poniamo (politica) è dove va a cercare la pagina meno usata per sostituirla con quella da caricare:
- in tutte le pagine in memoria (RAM) ?
- solo nelle pagine di A ?
Quindi esistono due tipi di algoritmi di politiche di allocazione :
- locale : si cerca la pagina vittima solo tra le pagine del processo
- se il working set cresce, si ottiene tanto trashing (anche in presenza di molti frame di pagina liberi)
- se il working set decresce, si spreca memoria (siccome altri processi non posso toccare i frame assegnati al processo)
- globale : si cerca tra tutte le pagine in memoria, anche quelle di altri processi
La politica globale è più efficiente siccome si adatta dinamicamente al carico reale del sistema, sottraendo frame ai processi che ne usano pochi e dandoli a quelli che ne hanno bisogno di più.
Gli algoritmi FIFO, LRU e tutte le approssimazioni (versioni) del LRU, possono lavorare sia con politiche globali che locali. Mentre gli algoritmi Working Set e WSClock possono lavorare esclusivamente con politiche locali.
Allocazione equa e proporzionale
Un’altra domanda ora che ci facciamo è : quanta memoria (frame) diamo ad ogni processo? Anche qui abbiamo 3 approcci di allocazione :
- equa : distribuzione uniforme dei frame tra i processi
- se abbiamo 12416 frame, diviso 10 processi, avremo che ogni processo avrà frame
- svantaggio : non si tiene conte delle diverse esigenze tra processi di dimensioni varie (es. processo da 10 KB ha meno esigenze di uno da 300 KB)
- proporzionale : distribuzione dei frame in base alla dimensione del processo
- es. processo da 300 KB riceve 30 volte i frame di uno da 10 KB
- vantaggio : rispecchia meglio le esigenze di memoria
- minimo indispensabile : distribuzione di un numero minimo di frame per poter eseguire le operazioni fondamentali
- in questo modo si evita che un processo si blocchi perché non ha abbastanza pagine
- garantisce che le istruzioni che coinvolgono più pagine contemporaneamente abbiano sempre i frame necessari per poter risiedere in RAM insieme
Politica di allocazione dinamica
Un metodo per regolare il numero di pagine assegnate, è farlo dinamicamente, partendo da un valore iniziale proporzionale alla sua dimensione, facendo in modo che la frequenza dei page fault al secondo - PFF (Page Fault Frequency) - sia contenuta in un certo intervallo.
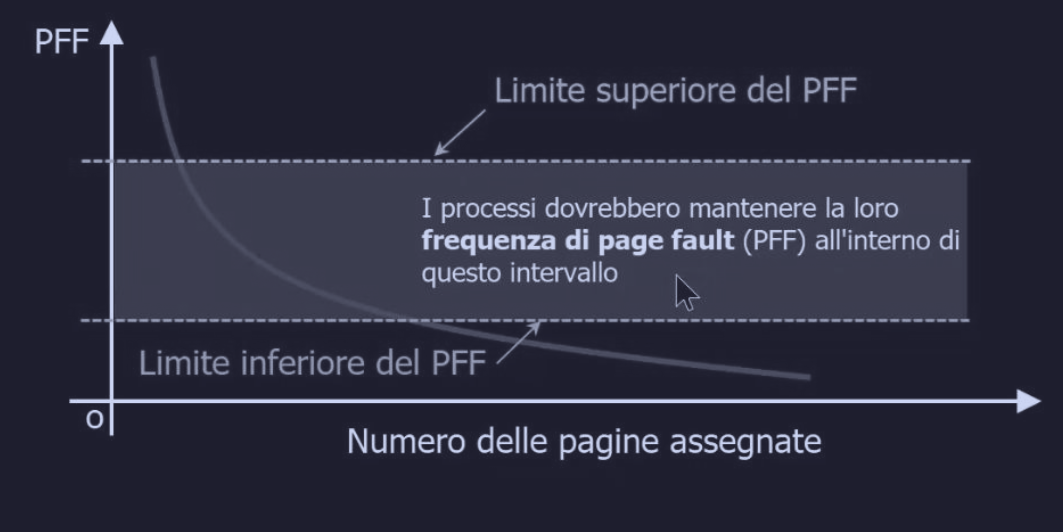
In parole semplici, misuriamo quanto spesso ogni processo va in page fault. Se fa troppi fault, gli diamo più frame. Se ne fa pochissimi, ne togliamo qualcuno.
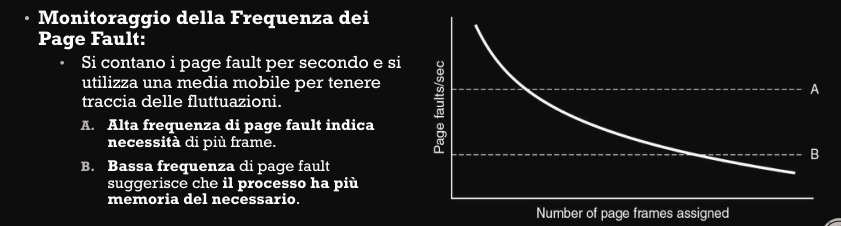
Controllo del carico
Anche se si utilizza il miglior algoritmo di sostituzione delle pagine e la migliore strategia di assegnazione, il sistema può andare comunque in sovraccarico.
Questo succede quando la somma delle dimensioni dei working set di tutti i processi in esecuzione supera la capacità fisica della memoria. Il risultato è che si verifica del thrashing, dove il sistema passa più tempo a spostare pagine tra disco e memoria.
Un “sintomo” per capire se si arriverà alla situazione descritta precedentemente, è quando i processi richiedono più memoria, ma nessun processo ne sta rilasciando o richiedendo di meno.
Esistono 2 soluzioni che il OS può utilizzare :
- Out Of Memory Killer (OOM Killer) (Linux) : processo speciale che termina uno o più processi per liberare memoria. La scelta del processo vittima è data da parametri del tipo :
- quanta memoria sta usando
- quanto è importante
- Swapping : meno drastico del OOM, siccome sposta temporaneamente il processo su disco (swap area). La scelta del processo da spostare è data qui da parametri del tipo :
- processo CPU bound o I/O bound
- frequenza di paginazione - PFF : un processo con PFF alto (troppi page fault) potrebbe essere un candidato
- dimensione del processo
Invece di uccidere o spostare i processi, è possibile utilizzare il compattamento, compressione e de-duplicazione.
Pulizia delle pagine
Il paging funziona meglio quando ci sono molti frame liberi disponibili utilizzabili subito quando si verifica un page fault.
Quando abbiamo tutti i frame allocati con pagine che sono state modificate, prima di poter caricare in memoria una nuova pagina, è necessario scrivere su disco la pagina modificata che deve essere sostituita. Questa operazione è molto costosa in termini di tempo.
Quindi gli OS implementano una politica di pulizia, dove un processo in background chiamato paging daemon :
- ispeziona periodicamente lo stato della memoria
- se ci sono pochi frame liberi, inizia la selezione delle pagine da rimuovere, utilizzando un algoritmo di sostituzione delle pagine
Un esempio di applicazione della politica di pulizia nell’algoritmo a Clock è quello di usare "due lancette" :
- lancetta anteriore : (paging daemon) analizza le pagine e se una pagina risulta sporca, viene schedulata per essere scritta su disco e il puntatore avanza
- lancetta posteriore : si usa l’algoritmo di sostituzione delle pagine
- la probabilità di trovare una pagina pulita aumenta, grazie al lavoro del paging daemon
Dimensione delle pagine
La dimensione della pagina è definita dal OS, ma anche se l’hardware ha una sua dimensione nativa per i frame di -byte, il OS può scegliere di lavorare con multipli di :

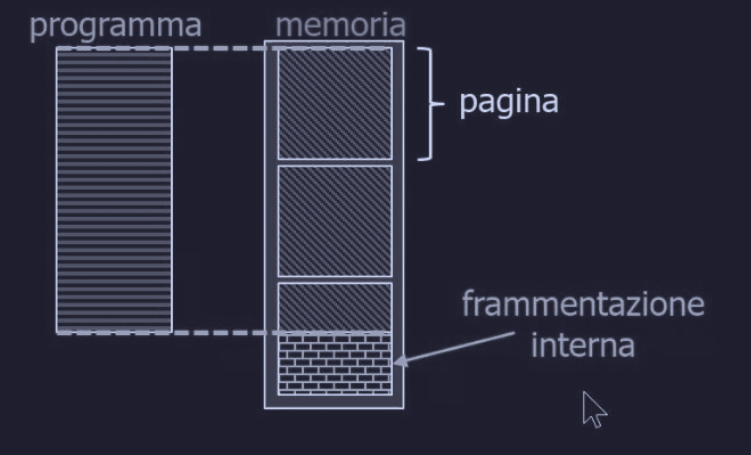
L’ideale sarebbero pagine piccole :
- permettono di caricare in memoria solo le parti di codice strettamente necessarie
- problema : abbiamo bisogno di tabelle delle pagine molto grandi (e quindi il TLB si riempe subito).
Nel caso invece utilizzassimo pagine grandi, avremo che per esempio se abbiamo pagine da 64 KB e un programma ha bisogno di altri 4 KB finali per i suoi dati, dovremmo assegnarli per forza una pagina da 64 KB e sprecare 60 KB (frammentazione interna).
Calcolo dimensione ottimale
Quindi abbiamo detto che i due overhead sono :
- pagine piccole overhead della tabella delle pagine
- infatti sia la dimensione di una pagina
- sia la dimensione media di un processo
- allora il # di pagine necessarie per un processo sarà
- sia la dimensione di una singola entry (riga) della tabella delle pagine
- allora lo spazio occupato dalla tabella sarà
- pagine grandi overhead nella frammentazione interna
- lo spazio sprecato dell’ultima pagina sarà in media la metà della dimensione della pagina, quindi
Se vogliamo ottenere una dimensione ottimale, in modo da minimizzare lo spreco totale (overhead), dobbiamo sommare i due overhead per avere un overhead totale :
infatti se osserviamo questa formula notiamo che :
- se la dimensione della pagina si abbassa, allora la dimensione della tabella cresce
- se la dimensione della pagine si alza, allora sprechiamo un sacco di memoria ( cresce)
Ora questa “funzione” del overhead totale, forma una specie di “U”. Quindi il nostro obiettivo è ottenere il minimo e lo facciamo :
- calcolando la derivata prima per :
- risolvendo l’equazione per (positivo) :
Quindi la dimensione ottimale delle pagine sarebbe
Per esempio :
- (dim. media processo)
- (dim. singola entry tab. pagine)
- avremo che :
Gli attuali computer utilizzano pagine da 1, 4, o 8 KB.
Altre tecniche
Poiché un’unica dimensione non va bene per tutti i carichi di lavoro, esistono altre 2 tecniche :
- pagine multiple : OS utilizza pagine grandi per il kernel e pagine standard per i programmi utente
- Transparent Huge Pages - THP : OS quando si accorge che un programma (db o videogioco) ha bisogno di un tanta memoria, fonde insieme tante pagine di dimensione standard (es. 4 KB) per creare un’unica pagina enorme (huge page) (in modo transparente al programmatore)
Dati e istruzioni su spazi separati
La maggior parte dei computer è progettata con un unico spazio di indirizzamento, questo vuol dire che sia il codice (istruzioni) sia i dati, devono “vivere” insieme nello stesso “contenitore” di indirizzi di memoria.

Per semplificare la condivisione bisogna avere due spazi di indirizzamento separati :
- I-space - Instruction space : spazio dedicato alle istruzioni
- D-space - Data space : spazio dedicato ai dati
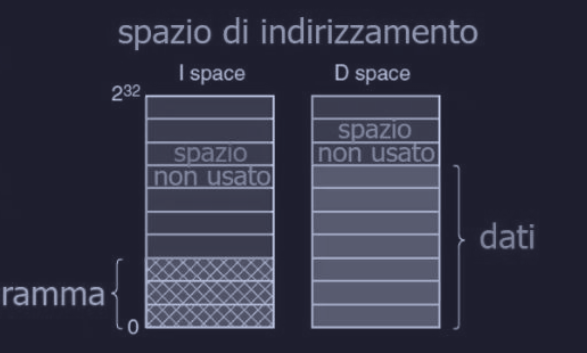
In questo modo entrambi gli spazi di indirizzamento hanno tabella di pagine separate. Quindi quando si vuole recuperare un’istruzione, si sa che si deve utilizzare la I-space e la sua tabella della pagine.
Quindi processi diversi possono utilizzare la stessa tabella della pagine per l’I-space, e tabelle diverse per il D-space (pagine condivise vedi dopo).
Pagine condivise
In un grande sistema multiprogrammato, capita spesso che più utenti stiano usando lo stesso programma contemporaneamente, per evitare di avere in memoria due (o più) copie identiche delle stesse pagine di codice.
La soluzione è condividere le pagine per evitare duplicati e risparmiare RAM.
Il problema è che non tutte le pagine sono condivisibili.
- codice (istruzioni): facile da condividere perché è solo read-only, e quindi non cambia durante l’esecuzione
- dati : difficile da condividere siccome i dati cambiano
Tipicamente l’implementazione consiste che ogni processo abbia due puntatori, uno per la tabella delle pagine del I-space e un altro per quella del D-space (come l’esempio di seguito). Quando lo scheduler sceglie il processo da eseguire, utilizza questi due puntatori per inizializzare la MMU.
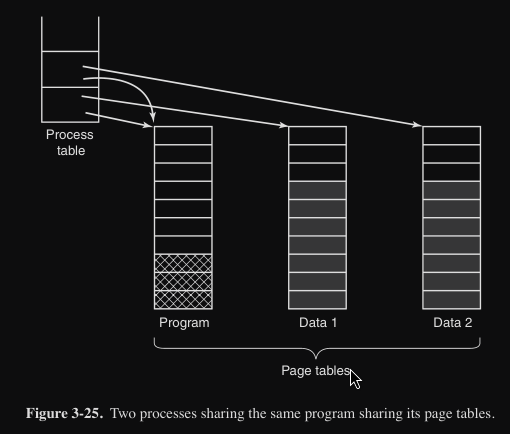
Esiste anche un problema con lo scheduling quando si condivide del codice : supponiamo per esempio che due processi A e B, che condividono pagine di codice, stiano entrambi eseguendo un editor. Se lo scheduler decide di togliere A dalla memoria, rimuovendo tutte le pagine a lui associate, provocherà molti page fault per il processo B che riporteranno di nuovo le pagine in memoria.
Nei sistemi UNIX la condivisione dei dati è fatta in modo intelligente, specialmente dopo una fork() :
- inizialmente padre e figlio condividono tutto, sia il codice che i dati
- il trucco sta nel contrassegnare tutte le pagine dati come read-only (anche se sono scrivibili)
- finché i processi si limitano a leggere le pagine dati è ok
- appena un processo tenta di scrivere una pagina dati, viene generata una trap al OS, che crea una copia “privata” di quella sola pagina per il processo che voleva scrivere
- in questo modo i due processi hanno copie di dati indipendenti
Questa tecnica si chiama Copy on Write (copia alla scrittura) e migliora drasticamente le prestazioni, siccome le copie sono create solo quando le pagine devono essere modificate.
Librerie condivise :luc_link_2:
Se un programma viene avviato più volte, il OS condivide automaticamente tutte le pagine di codice in modo da avere solo una copia in memoria. Le pagine più comuni utilizzate da quasi tutti i programmi, vengono riunite in quelle che vengono chiamate librerie condivise (DLL in Windows). In questo modo si risparmia spazio.
Il problema delle librerie condivise è l’utilizzo del indirizzamento assoluto, per esempio supponiamo che ci siano due processi che condividono la stessa libreria :
- processo 1 inizia a “vedere” la libreria dal indirizzo (virtuale) 36K, mentre processo 2 da 12K (come in figura sotto)
- supponiamo che la prima funzione della libreria fa una jump ad un istruzione, sempre della libreria stessa, in 36K+16 byte (indirizzo assoluto 36016)
- processo 1 va tutto ok, perché ci va perfettamente
- processo 2 non va tutto ok, perché lui in quel indirizzo non vede la libreria, ma altro!

La soluzione sarebbe di utilizzare gli indirizzi relativi, ovvero di utilizzare un offset :
- invece di fare un jump direttamente in 36016, fai un jump a (PC : Program Counter)
- codice delle librerie compilato in questo modo prende il nome di Position Independent Code - PIC
Un Memory-Mapped File è una tecnica dove il OS mappa i blocchi di un file su disco direttamente negli indirizzi virtuali di un processo. Il file si comporta come un enorme array in RAM: i dati vengono caricati dal disco solo quando vengono letti (demand paging) e salvati su disco solo alla chiusura.
I file mappati in memoria forniscono un modo alternativo per l’I/O, infatti il file mappato appare al programma come se fosse un grande array di caratteri in memoria.
Se più processi mappano lo stesso file, la memoria fisica viene condivisa, permettendo una comunicazione istantanea (IPC - Inter-Process Communication).