
Tra i compiti del sistema operativo abbiamo la gestione dei dispositivi I/O :
- inviare comandi ai dispositivi I/O
- catturare gli interrupt dei dispositivi I/O
- gestire gli errori provenienti dai dispositivi I/O
- fornire un’interfaccia semplice tra i dispositivi I/O e il resto del sistema
Questa parte di software responsabile della gestione dell’I/O rappresenta una frazione significativa del OS.
Dispositivi di I/O
I dispositivi I/O possono essere divisi in due categorie :
- dispositivi a blocchi :
- come dischi rigidi, SSD e chiavette USB
- informazioni in blocchi di dimensione fissa (512 a 32 768 byte)
- dispositivi a caratteri :
- come stampanti, interfacce di rete e mouse
- gestione di informazioni attraverso un flusso di caratteri (senza struttura)
- non sono indirizzabili e non hanno alcuna operazione di ricerca
Ci sono altri tipi di dispositivi che non rientrano nelle due categorie tra cui :
- clock
- RAM della scheda video : memoria dentro il controller video che rappresenta una specie di bitmap dell’immagine sullo schermo
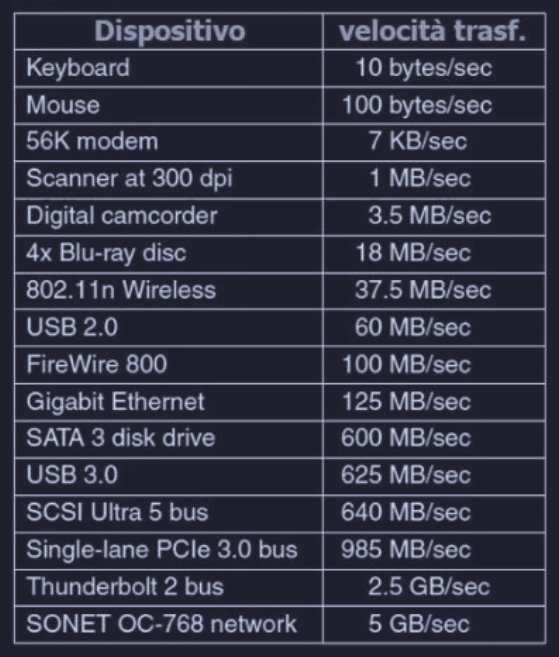
I dispositivi I/O possono avere velocità molto diverse, quindi è compito del software cercare di sfruttare al massimo le potenzialità del dispositivo durante il trasferimento dati :
Controller dei dispositivi I/O :luc_gamepad_2:
I dispositivi di I/O sono costituiti tipicamente da una componente elettrica e una meccanica.
La componente elettrica è chiamata controller del dispositivo (device controller).
Sui PC è un chip sulla scheda madre o una scheda che può essere inserita in uno slot di espansione (PCI). Mentre la componente meccanica è il device stesso.
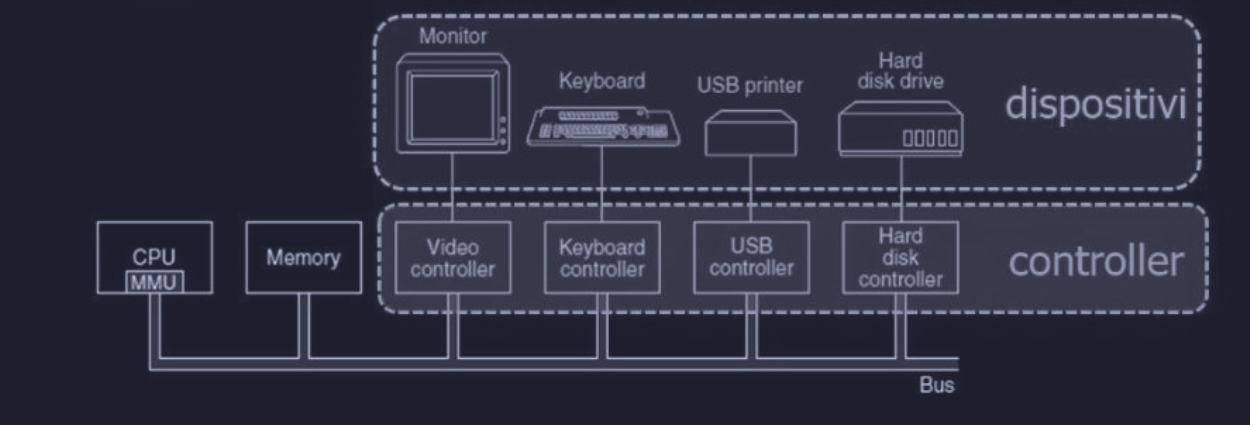
Molti controller possono gestire più dispositivi identici, infatti se l’interfaccia fra il controller e i dispositivi è un’interfaccia standard (come SATA o USB), possiamo collegare per esempio due dispositivi di produttori diversi (non bisogna avere tutto della stessa marca).
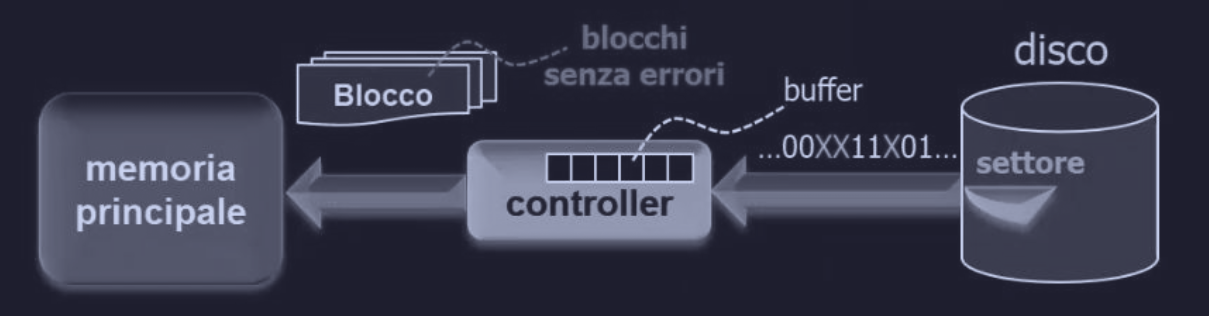
Quando il disco rigido legge dei dati, il disco non invia un file bello e pronto, invece sputa fuori un flusso seriale di bit strutturato in questo modo :
- preambolo
- dati
- bit extra per il ECC (codice correzione errori)
Il compito del controller in questo caso è quello di convertire il flusso seriale di bit in un blocco di byte e la correzione degli errori.
Dalla “vecchia” porta parallela alla porta USB
Parallel port

La vecchia porta parallela (figura sotto) è un tipo di interfaccia utilizzata tra pc e dispositivi (es. stampanti) :
- trasmette simultanea su più pin
- dotata di 25 pin (Standard DB-25) o 36 pin (Centronics)
La distribuzione dei pin dello Standard DB-25 :
- 1-8 (
D0-D7) : dati - 9-16 : controlli e status (selezione stampante, inizializzazione, errori etc.)
- 17-25 : massa e alimentazione

La velocità di questa interfaccia dipende dalla modalità e dal dispositivo che vi è collegato.
USB
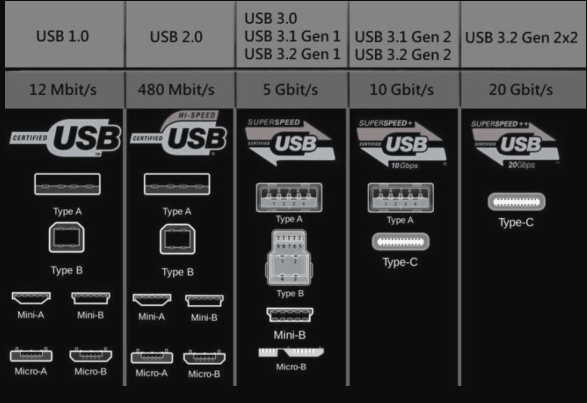
Già parlato inEsempi di bus - USB, che a differenza della porta parallela è un’interfaccia seriale.
L’USB ha si è evoluto con le versioni 1.x, 2.0 e 3.x, arrivando a velocità di trasferimento che partono da 1,5 Mbps a 10 Gbps.
Vantaggi :
- facilità d’uso
- connessione plug-and-Play
- trasmissione dati + alimentazione (stesso cavo)
- retrocompatibile con versioni precedenti
Comunicazione tra CPU e controller
Ogni controller ha alcuni registri di controllo per la comunicazione con la CPU :
- OS scrivendo questi registri comanda il dispositivo di inviare dati, accettarli, mettersi in stato di accesso o spento o eseguire un altra operazione
- OS leggendo da questi registri, riesce a capire lo stato del dispositivo, se pronto ad accettare un nuovo comando etc
Inoltre molti dispositivi hanno anche un buffer di dati dove il OS può scrivere e leggere dati.
La questione che sorge è come la CPU comunica con i registri di controllo e i buffer dati del dispositivo, infatti esistono tre modalità principali :
- port-mapped I/O (o I/O isolato) : come un vero e proprio dispositivo di I/O
- memory-mapped I/O : come parte della memoria
- (bonus) hybrid-mapped I/O : entrambi
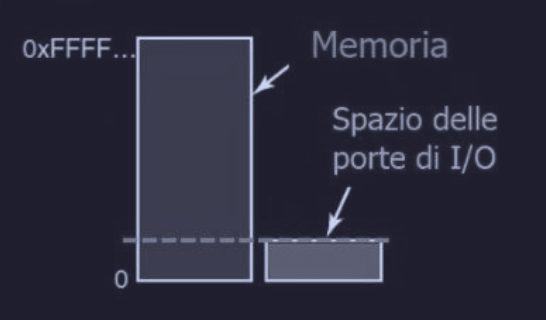
Port-mapped I/O
Il port-mapped I/O è uno dei metodi con cui la CPU comunica con le periferiche :
- ad ogni registro di controllo è assegnato un numero di porta I/O (un numero intero di 8 o 16 bit)
- spazio separato : l’insieme di tutte le porte I/O forma lo spazio delle porte I/O e solo OS può accederci
- siccome le porte sono in un “mondo separato” dalla memoria, la CPU non può usare i comandi standard di spostamento dati (
MOV-LOAD), ma deve usare delle istruzioni speciali :IN <REG>, <PORT>: CPU legge il registri di controlloPORTe salva il risultato nel registroREGOUT <PORT>, <REG>: CPU scrive il contenuto diREGin un registro di controllo del dispositivo (PORT)
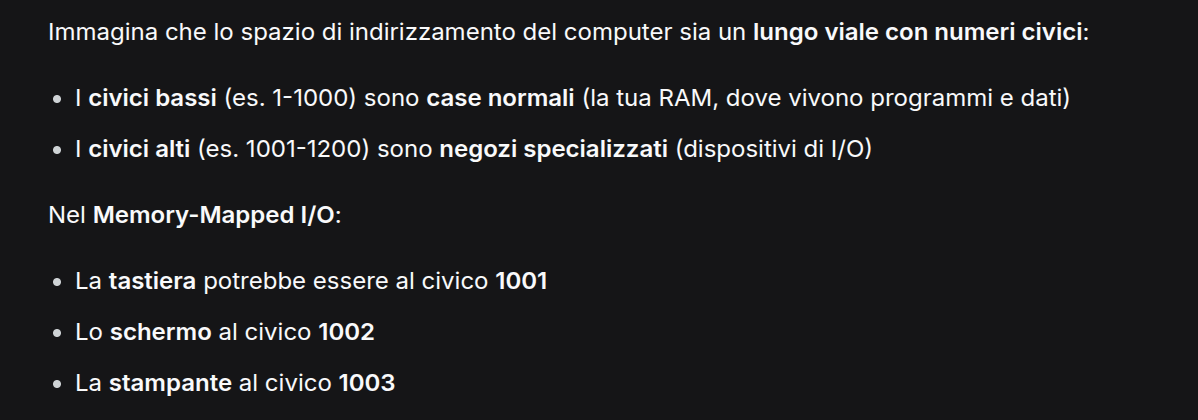
Memory-mapped I/O
Il memory-mapped I/O, utilizzato per la prima volta nel PDP-11, consiste nel mappare tutti i registri di controllo nella memoria.
Quindi a ciascun registro di controllo viene assegnato un indirizzo di memoria univoco (nella parte superiore dello spazio degli indirizzi) che diventa non più utilizzabile come spazio di memoria principale.

^svantaggi-memory-mapped Svantaggi :
- caching : se i valori dei registri di controllo dei dispositivi I/O finiscono nella cache, la CPU potrebbe leggere valori vecchi e sbagliare
- hardware deve avere la capacità di disabilitare la cache sulle pagine di I/O
- ascolto ogni riferimento memoria : tutti i dispositivi devono “stare in ascolto” ad ogni indirizzo che passa sul bus, per capire quando rispondere
- problema in architetture con bus multipli (es. x86)
- multi-bus cpu-memoria : se esiste un collegamento dedicato CPU-memoria, i dispositivi di I/O non vedono gli indirizzi di memoria sul bus e quindi non hanno modo di rispondergli

Per risolvere il problema dei bus multipli ci sono 2 soluzioni :
- memory-first : richiesta viene prima mandata alla memoria, poi la memoria dirà se gli piace oppure no, se non gli piace allora quella richiesta era per I/O
- pro : semplice da implementare
- contro : maggiore ritardo accessi I/O
- bus snooping : device nel bus monitora gli indirizzi e reindirizza quelli per I/O
- pro : accessi I/O più veloci
- contro : maggiore complessità hardware
Vantaggi :
- i registri di controllo dei dispositivi sono delle variabili in memoria e consentendo la programmazione di driver completamente in C
- eliminazione istruzioni speciali
- protezione semplificata : processi utente non accedono direttamente ai registri di controllo (gestione pagine da OS)
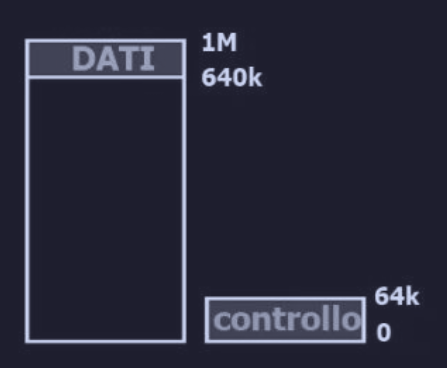
Hybrid-mapped I/O
Lo schema ibrido presenta :
- buffer dei dati dei dispositivi I/O mappati in memoria (memory-mapped I/O - MMIO)
- porte di I/O per i registri di controllo (port-mapped I/O - PMIO)
Vantaggi :
- semplicità del PMIO per le configurazioni + velocità del MMIO
- compatibilità con hardware più vecchi (grazie al PMIO)
Svantaggi :
- aumento complessità
- usare PMIO per la configurazione iniziale rallenta
- non tutte le CPU possono usarlo (es. ARM no PMIO)
Dal memory-mapped I/O alla realtà
Il MMIO definisce un modello di indirizzamento diciamo “astratto”, ma poi è l’hardware che deve :
- mantenere alte prestazioni sulla memoria
- supportare molti dispositivi I/O diversi
- un bus unico per tutto non va bene
La soluzione è l’introduzione di chipset a due livelli :
- northbridge :
- chip tra CPU e memoria
- gestire comunicazioni ad alte prestazioni (es. accessi RAM)
- riceve ogni riferimento in memoria e fa la decodifica degli indirizzi fisici (per memoria o I/O)
- southbridge : gestione dei dispositivi I/O
Nei sistemi moderni :
- northbridge integrato nella CPU
- southbridge diventa il PCH (Platform Controller Hub)
- ma l’astrazione rimane sempre quella del MMIO
Quindi anche se c’è questa divisione hardware, il concetto è sempre lo stesso del MMIO. Il software resta semplice e l’hardware nasconde le complessità.
Direct Memory Access (DMA)
A prescindere se una CPU abbia o meno dispositivi mappati in memoria, ha bisogno di accedere ai controller dei dispositivi per scambiare dati con loro. La CPU potrebbe chiedere i dati dal controller un byte alla volta, ma questo spreca il tempo della CPU.
Quindi viene usato uno schema diverso, chiamato DMA (Direct Memory Access) che permette alla CPU di disinteressarsi del trasferimento dati e di svolgere altre attività in parallelo (mentre i dati vengono trasferiti).
PS : Spiegazione DeepSeek
Il OS può usare il DMA solo se l’hardware ha un controller DMA, cosa che la maggior pate dei sistemi possiede. Infatti i controller possono avere un proprio DMA oppure si può utilizzare un controller DMA (nella scheda madre) per più dispositivi.
Lettura da disco senza DMA
La lettura dal disco senza l’utilizzo del DMA è la seguente :
- il controller del disco legge l’intero blocco dal drive in modalità seriale bit a bit
- il blocco viene caricato in un buffer (bufferizzato)
- controlla se ci sono stati errori (ECC)
- il controller genera un interrupt verso la CPU
- OS copia i dati in memoria

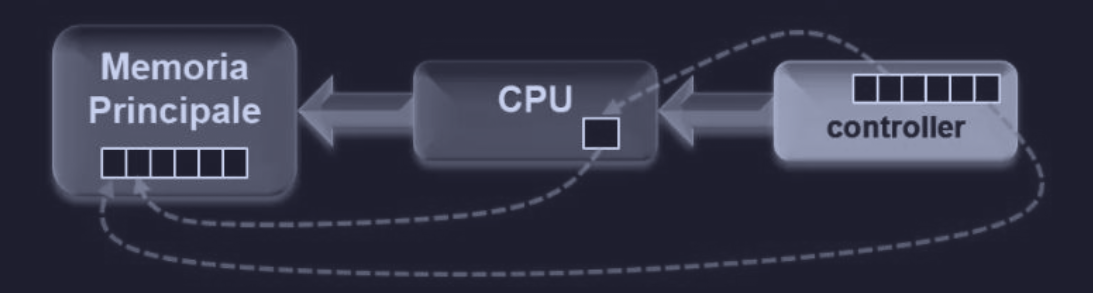
Lo svantaggio sta nel fatto che la CPU viene chiamata per fare un lavoro banale di copia da buffer a memoria (spreco di tempo).
Lettura dal disco con DMA
Quando si usa il DMA la procedura di lettura dal disco è la seguente :
- la CPU programma il controller DMA
- DMA invia un comando al controller del disco di leggere i dati nel suo buffer interno
- una volta caricato tutto nel buffer, il DMA inizia inviando una richiesta di lettura al controller del disco per il trasferimento in memoria
- ripetizione dei passi 2-3 fino al completamento del trasferimento
- DMA invia un interrupt alla CPU al termine del trasferimento
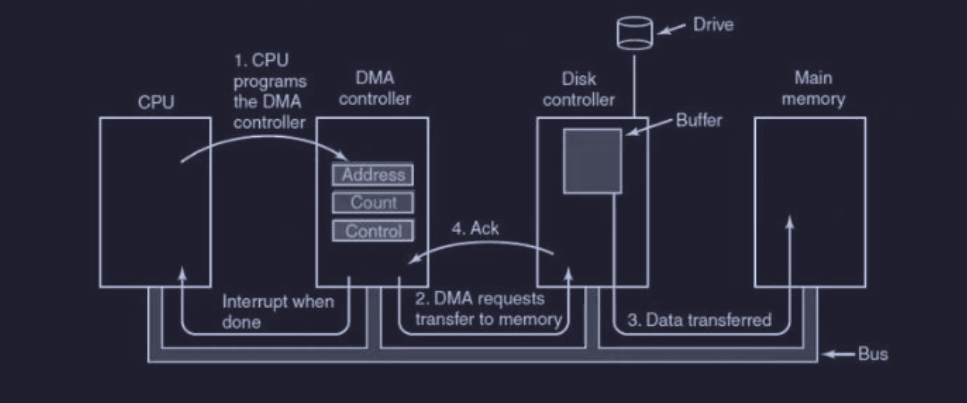
Modalità utilizzo bus del DMA
Molti bus (e anche controller DMA) possono funzionare in due modalità :
- una word alla volta :
- funzionamento : controller DMA richiede il trasferimento di una word di dati alla volta (stiamo trasferendo un blocco dati di word)
- interazione con CPU : se la CPU ha bisogno del bus durante questo trasferimento, il controller DMA deve aspettare
- quindi il DMA ruba un ciclo di bus occasionale dalla CPU, solo per trasferire una word dal buffer alla memoria, rallentandola leggermente - cycle stealing
- un blocco alla volta (modalità burst) :
- il controller DMA dice al dispositivo di acquisire il bus
- trasferisce tutto e poi rilascia il bus
Interrupt rivisitati
Quando un dispositivo di I/O ha terminato il proprio lavoro, genera un interrupt che invia al controllore degli interrupt (o arbitro) che decide cosa fare :
- se non c’è nessun altro interrupt in sospeso, viene elaborato l’interrupt appena arrivato
- se c’è un altro interrupt in sospeso o un dispositivo è arrivato prima, si decide in base alla priorità assegnata ai dispositivi
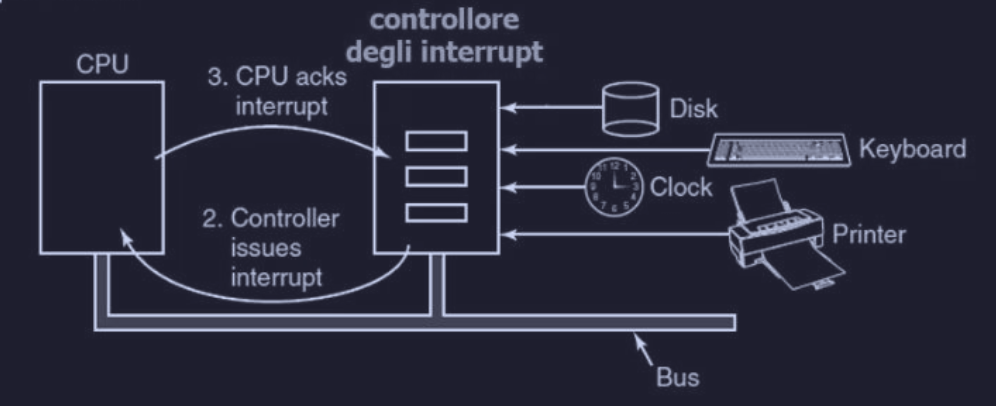
Per gestire l’interrupt :
- il controller pone un numero sulle linee di indirizzo per specificare quale dispositivo ha inviato l’interrupt
- segnala alla CPU l’interruzione
- il numero è usato come indice in una tabella chiamata vettore di interruzione che restituisce il nuovo valore del PC, ovvero l’inizio della ISR
Prima di avviare la ISR l’hardware deve salvare lo stato della CPU (PC, registri, stack etc), ma dove vengono salvate temporaneamente queste informazioni?
- nei registri interni del controller
- OS in questo modo può leggere non appena ne ha bisogno
- problema : il controller non può ricevere nuovi interrupt finché i registri non vengono letti, rischiando la perdita di interrupt successivi
- nello stack :
- bisogna decidere quale stack usare, se quello del programma utente o uno speciale del OS
- utilizzo dello stack kernel (OS) è migliore dal punto di vista di affidabilità siccome è gestito dal OS, ma il passaggi alla modalità kernel può richiedere tempo di CPU a causa del cambio di contesto nella MMU
Interrupt precisi
Nelle CPU vecchie, dopo ogni istruzione si controllava se c’era un interrupt in attesa. Se sì, si salvava tutto e si gestiva l’interrupt. Era chiaro quali istruzioni erano finite e quali no. Nelle CPU moderne pipeline e superscalari, molte istruzioni sono “in volo” contemporaneamente. Quindi ci domandiamo cosa succede se si verifica un interrupt mentre la pipeline è piena?
Molte istruzioni si troverebbero in diversi stati di esecuzione, mentre il valore del PC potrebbe non determinare il confine netto tra istruzioni eseguite e quelle non eseguite (alcune istruzioni potrebbero essere state eseguite parzialmente).

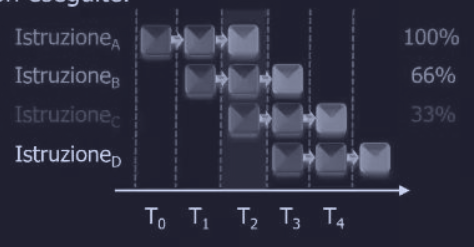
Un interrupt che lascia la macchina in uno stato ben definito è chiamato interrupt preciso e ha quattro proprietà :
- il PC viene salvato in un posto conosciuto
- tutte le istruzioni prima di quella a cui punta il PC sono state eseguite (completamente)
- nessuna istruzione dopo quella puntata dal PC è stata eseguita
- lo stato dell’istruzione puntata dal PC è conosciuto
Mentre un interrupt che non soddisfa le 4 proprietà è detto interrupt impreciso.
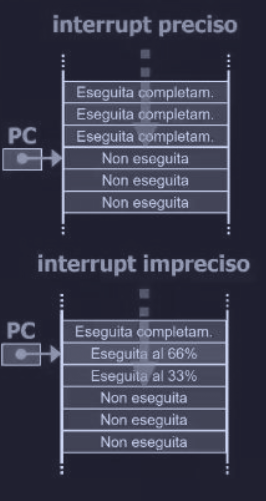
Le macchine con interrupt imprecisi delegano al OS di capire come gestire la situazione nel momento di ripristino e riversano sullo stack grandi quantità di dati sullo stato interno. Questo rende il ripristino estremamente complesso e lento, che porta a dire che le veloci CPU superscalari (che lasciano la macchina in uno stato non ben definito quando arriva un interrupt) sono inadatte per gestire sistemi real-time a causa delle lentezza nella gestione degli interrupt.