
Analizziamo ora gli obiettivi di un software di I/O :
- indipendenza dal dispositivo
- es. un programma che legge un file dovrebbe funzionare indifferentemente che sia disco, SSD o USB drive
- denominazione uniforme : nome di un file o di un dispositivo non deve dipendere dal tipo di dispositivo
- es. su UNIX non vogliamo avere per forza ST6NM04 per indirizzare un primo disco, ma è meglio
/dev/sdao/mnt/movies
- es. su UNIX non vogliamo avere per forza ST6NM04 per indirizzare un primo disco, ma è meglio
- gestione degli errori : gli errori dovrebbero essere gestiti il più possibile a livello hardware
- molti errori (lettura dal disco) “scompaiono” se la l’operazione viene ripetuta
- trasferimenti sincroni vs asincroni : i trasferimenti possono essere bloccanti (sincroni) o gestiti con interrupt (non bloccanti asincroni)
- a causa della differente velocità, i dispositivi I/O sono tipicamente asincroni
- è molto più facile scrivere programmi utenti con primitive bloccanti (come
read()), quindi sta al OS di dare al programmatore “l’illusione” di utilizzare chiamate sincrone quando in realtà i dispositivi sono trattati con primitive asincrone
- bufferizzazione : i dati che vengono da un dispositivo non possono essere memorizzati direttamente nella loro destinazione finale, ma devono essere bufferizzati
- condivisione : alcuni dispositivi I/O possono essere utilizzati da più utenti contemporaneamente
Modalità di gestione dell’I/O
I dispositivi I/O possono essere gestiti con tre diverse tecniche :
- I/O programmato
- I/O guidato dagli interrupt (interrupt-driven)
- I/O con DMA
I/O programmato
È una tecnica semplice perché è la CPU che svolte tutto il lavoro, per esempio se consideriamo un processo utente che vuole stampare una stringa sulla stampante :
- il OS copia la stringa nello spazio kernel (es. array p) e controlla se la stampante è libera (altrimenti aspetta)
- se libera, OS invia un carattere alla volta al registro dati della stampante, viene quindi attivata la stampante con questa azione
- il OS esegue il polling della stampante per controllare se è pronta per accettare un altro carattere - polling o busy waiting
le azioni del OS possono essere riassunte in questo snippet :

L’I/O programmato è semplice ma ha lo svantaggio di utilizzare il tempo della CPU finché tutte le operazioni di I/O non sono finite, infatti il busy waiting è una prassi che andrebbe limitata solo ai casi di I/O veloce.
I/O guidato dagli interrupt
Il modo per consentire alla CPU di proseguire il suo lavoro e fare qualcos’altro piuttosto che aspettare, è usare gli interrupt. Quindi quando un dispositivo finisce un’operazione (es. stampare un carattere), genera un interrupt che “sveglia” la CPU, che può allora gestire l’operazione successiva.
Quindi nell’esempio della stampante avremo che :
- la CPU invia un carattere alla stampante
- la CPU chiama subito lo scheduler per eseguire altri processi
- la stampante quando finisce di stampare il carattere, genera un interrupt
- la CPU interrompe il processo corrente ed esegue la ISR che invia il carattere successivo
- ripete dal punto 2

I/O con l’uso del DMA
Il problema dell’I/O interrupt-driven è che genera un interrupt per ogni carattere, e ogni interrupt richiede tempo e spreca tempo della CPU. Quindi una soluzione alternativa è di utilizzare il controller DMA che invia i caratteri alla stampante una alla volta, senza l'intervento della CPU.
Il trade-off sta nel fatto che il controller DMA è più lento della CPU, quindi per trasferimenti molto piccoli (pochi caratteri) è più efficiente usare I/O programmato o interrupt-driven, mentre per trasferimenti grandi il DMA vince.

Livelli software per I/O
Il software I/O è organizzato in quattro livelli :
- software utente : programmi che usano le system call come
read,write(librerie) - software indipendente dal device : gestisce funzioni comuni a tutti i dispositivi
- driver del dispositivo : codice specifico per ogni device
- gestori degli interrupt : parte per “svegliare” i driver per gestire interrupt di I/O
Ogni livello ha una funzione ben definita e definisce dei servizi per gli altri livelli adiacenti.
Gestione degli interrupt nel OS
Nei sistemi con memoria virtuale, la gestione degli interrupt diventa complessa e richiede passaggi aggiuntivi per gestire MMU, TLB e cache.
I 10 passaggi per la gestione degli interrupt :
- salvataggio registri + quelli non salvati dall’hardware
- setup del contesto per la ISR + setup TLB, MMU e tabella delle pagine
- setup dello stack per la ISR
- invio ACK al controller degli interrupt
- copia dei registri nella tabella dei processi (in 1. li avevamo salvati temporaneamente)
- esecuzione della ISR (gestore interrupt) che estrae le info dai registri del controller del dispositivo che ha generato l’interrupt
- scelta del processo successivo (magari qualche processo sbloccato dal interrupt)
- setup contesto per il nuovo processo (MMU e TLB)
- caricamento dei nuovi registri del processo (+ PSW)
- avvio del processo
Driver
Ogni dispositivo hardware (stampante, disco, scheda video) ha caratteristiche uniche e richiede un programma specializzato (driver) per comunicare con il OS. I produttori scrivono questi driver per i vari sistemi operativi.
I driver tradizionali sono parte del kernel perché devono accedere direttamente ai registri del controller hardware (es. driver file system e rete).
È possibile anche avere driver che girano come normali programmi utente (es. driver per il plug-and-play), che usando system call riescono a comunicare con l’hardware, questo ci porta ad avere :
- isolamento dal kernel : se il driver “crasha”, non blocca tutto il sistema
- + lenti (switch allo spazio kernel per ogni operazione)
I driver si trovano al di sotto del resto del OS e formano uno strato intermedio tra il kernel e l'hardware. Inoltre ogni driver gestisce un controller specifico.
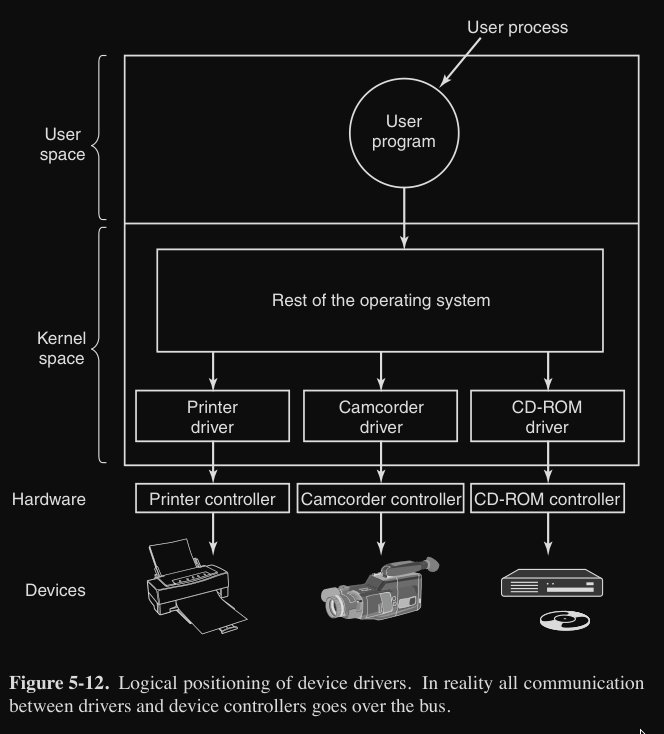
I progettisti dei OS sanno che i driver scritti dai produttori, verranno installati all’interno della loro architettura, quindi esiste un “modello standard” che i produttori di hardware devono seguire. Questo permette a codice scritto da terzi di integrarsi perfettamente nel sistema.
Classificazione driver e caratteristiche fondamentali
Gli OS di solito classificano i driver in base a come gestiscono i dati :
- dispositivi a blocchi : lavorano con blocchi di dati di dimensione fissa (es. dischi)
- dispositivi a caratteri : gestiscono flussi continui di caratteri (es. tastiere, stampanti). I dati arrivano in sequenza senza struttura a blocchi
Le caratteristiche critiche e fondamentali dei driver sono :
- rientranza (reentrant) : chiamato più volte
- pluggable “a caldo”: dispositivi collegati e scollegati mentre il computer è on
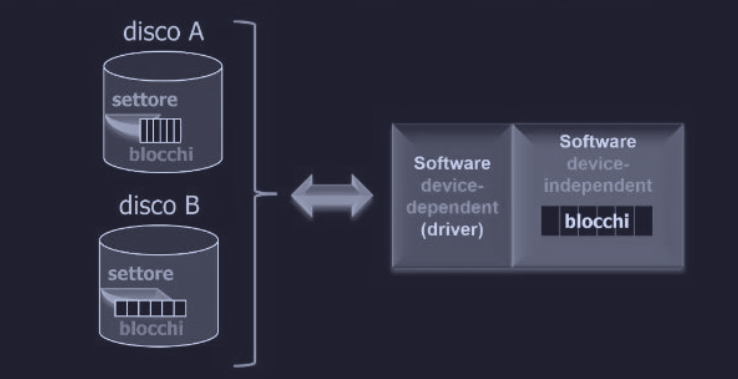
Software I/O indipendente dal device
ll sistema I/O è diviso in due parti: una parte specifica per ogni dispositivo (i driver) e una parte generica che funziona per tutti i dispositivi (parte indipendente).
Questo strato “indipendente” fornisce servizi comuni che evitano di duplicare codice in ogni driver, e ha le seguenti funzioni :
- buffering: gestione dei buffer di dati tra dispositivi e memoria
- segnalazione errori: gestione uniforme degli errori per tutti i dispositivi
- allocazione/rilascio device dedicati: gestione dei dispositivi che possono essere usati da un solo processo alla volta (es. stampanti)
- fornire uno standard per i blocchi: nasconde le differenze tra dischi con settori di dimensioni diverse
- fornire interfacciamento uniforme dei driver dei dispositivi (vedi sotto)
Interfacciamento uniforme dei driver :luc_inspect:
Il OS deve poter lavorare con molti dispositivi diversi senza dover conoscere i dettagli specifici di ognuno. Per questo si definisce un‘“interfaccia standard” che tutti i driver devono seguire, in modo che appaiano tutti uguali al OS.
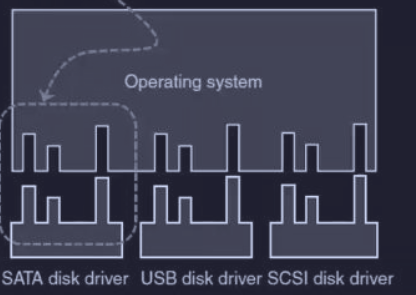
Senza interfaccia standard, l’interfacciamento di un nuovo driver richiederebbe uno sforzo enorme di programmazione.
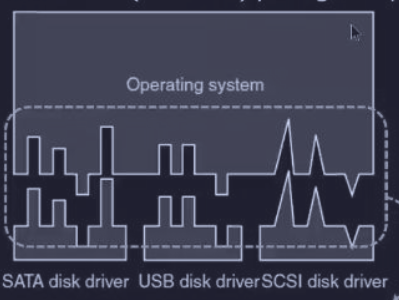
Quando un programma vuole accedere a un dispositivo, usa un nome simbolico (es. /dev/disk0). Infatti il software indipendente dal dispositivo fa da “traduttore” tra nomi simbolici e driver fisici.
review In UNIX tutti i dispositivi hanno :
- major device number : numero primario utilizzato per individuare il driver appropriato
- minor device number : numero secondario che specifica quale unità di quel dispositivo (es. disco 0, disco 1, stampante 0)
Infatti in UNIX il nome
/dev/disk0non è un file normale, ma un file speciale che punta ad un i-node che contiene il major number e il minor number.
Buffering
Il buffering serve a gestire la differenza di velocità tra dispositivi lenti (come modem) e CPU veloce, evitando che il processo venga svegliato troppo frequentemente.
Consideriamo per esempio un processo che vuole leggere dati da un modem (lento) senza buffer :
- processo fa
read()e si blocca in attesa di un carattere dal modem - il modem passa il carattere generando un interrupt
- l’ISR “sveglia” il processo per ogni singolo carattere questo modo non è efficiente perché il processo viene bloccato e risvegliato in continuazione per pochi caratteri alla volta.
La soluzione quindi è usare un buffer di n caratteri nello spazio utente :
- ISR scrive più caratteri nel buffer finché non si riempe
- il processo viene “svegliato” solo quando il buffer è pieno
- Ma cosa succede se il buffer è “paginato” su disco, ovvero, cosa succede quando arriva un carattere e il buffer non si trova in RAM?
La soluzione sta nello spostare il buffering nel kernel e usare una tecnica per alternare due buffer (utente e kernel) :
- l’ISR scrive i caratteri in un buffer nel kernel
- quando il buffer kernel è pieno, viene portata in memoria la pagina che contiene il buffer utente
- si copia tutto il buffer kernel nel buffer utente in una sola operazione
Il buffering è una tecnica molto utilizzata, ma bisogna fare attenzione all’eccesso di copia da uno spazio all’altro, che rallenta le prestazioni.
Segnalazione e gestione degli errori
I dispositivi di I/O sono soggetti a errori e quando si verifica un errore, il software deve decidere come gestirlo, con diverse opzioni disponibili.
Le classi più comuni di errori I/O sono :
- errori di programmazione: il processo fa richieste impossibili o illogiche
- esempio : tentare di scrivere su un dispositivo di solo input (come un mouse)
- errori fisici del dispositivo: problemi hardware reali
- esempio: settore danneggiato su un disco, cavo scollegato, dispositivo guasto
Quando un componente software (come driver) rileva un errore può :
- in presenza di utente interattivo provare a dialogare (riprova, ignora, termina processo)
- senza utente interattivo la system call fallisce restituendo un codice di errore
Allocazione/rilascio dei dispositivi dedicati
Alcuni dispositivi, come le stampanti, possono essere usati da un solo processo alla volta perché altrimenti si creerebbero conflitti (dispositivi dedicati). Il OS deve gestire queste richieste esclusive.
Infatti esistono due approcci possibili di gestione :
- “tentare non nuoce” : il processo che vuole utilizzare il dispositivo “tenta” una
open()sul file speciale del dispositivo- se libero riesce nell’operazione e blocca il dispositivo per uso esclusivo
- altrimenti fallisce e aspetta
- meccanismi di sincronizzazione : si utilizzano i classici meccanismi di sincronizzazione tra processi, quindi il processo che trova il device occupato va in
sleep, e quando il device è liberato il processo insleepviene “risvegliato”
Spooling
In un sistema multiprogrammato, dispositivi come le stampanti possono essere usati da un solo processo alla volta, per questo viene utilizzata una tecnica chiamata spooling.
Lo spooling crea un’area di attesa (directory) e invece di inviare i lavori direttamente al dispositivo lento, i processi li depositano in quest’area. Un daemon si occuperà poi, di prelevare un lavoro alla volta dall’area di attesa e inviarlo al dispositivo.
In questo modo il processo che ha richiesto l’operazione non deve aspettare che il dispositivo sia libero.
Dimensione dei blocchi device-independent
Dischi diversi hanno settori di dimensioni diverse (es. 512 byte, 4 KB, 8 KB). Il software indipendente dal dispositivo deve nascondere queste differenze e presentare ai programmi una dimensione di blocco standard e uniforme.
Software per I/O nello spazio utente - librerie di I/O
Anche se la maggior parte della gestione dell’I/O avviene dentro il OS, una parte importante si trova nelle librerie che usano i programmi.
Quando un programma in C contiene la chiamata :
count = write(fd, buffer, nbytes); write()è una funzione di una libreria- questa libreria viene collegata al nostro programma durante la compilazione
- quindi in fase di esecuzione (run-time)
write()sarà contenuta nella memoria del nostro processo
Quindi possiamo dire che le librerie :
- semplificano la programmazione di I/O
- permettono di concentrarsi sulla logica dell’applicazione piuttosto che sui dettagli di basso livello di I/O